
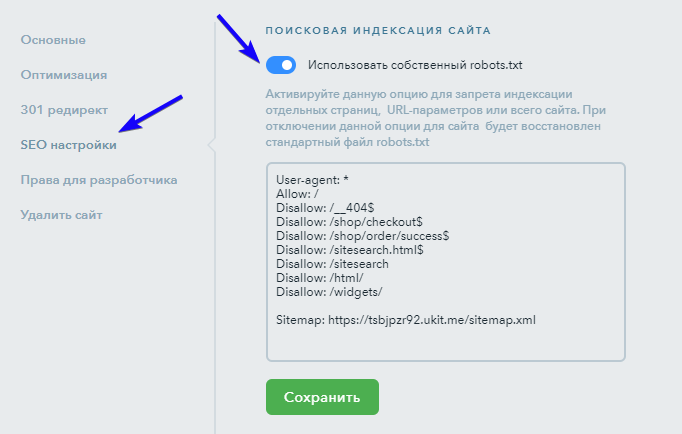
Введение
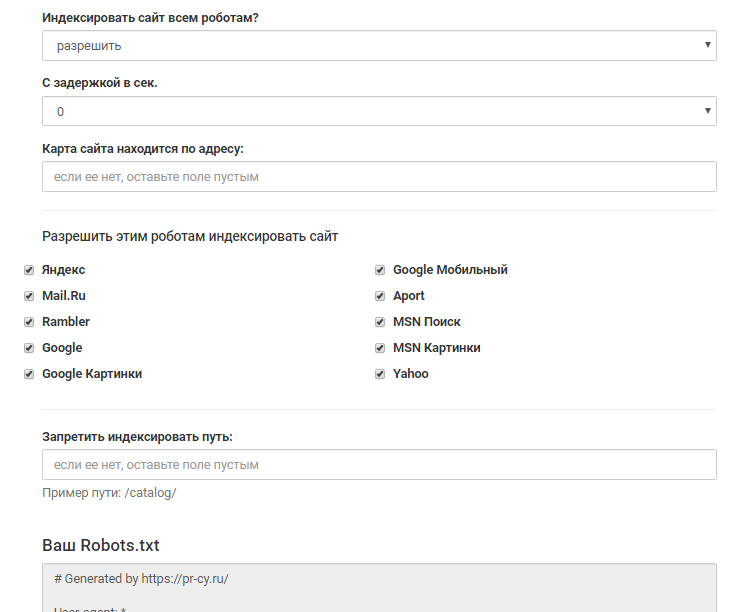
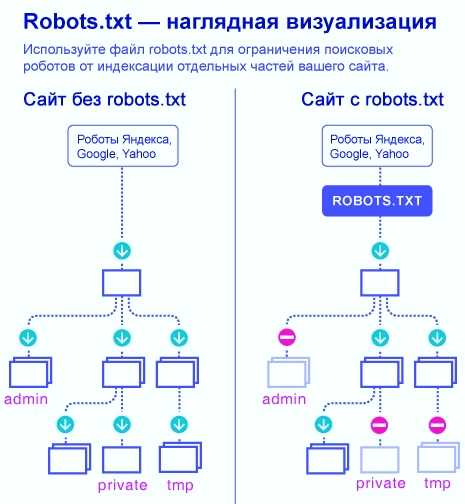
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
Как еще можно использовать robots.txt?
Содержимое robots.txt может включать не только список директив для обращения к поисковым системам. Поскольку файл является общедоступным, некоторые компании подходят к его созданию творчески и с юмором. Иногда там можно обнаружить картинку, логотип бренда и даже предложение о работе. Реализация нестандартного robots.txt осуществляется с помощью комментариев # и других символов.
Пользователи, которых заинтересовал robots.txt сайта, вероятнее всего разбираются в оптимизации. Поэтому документ может быть дополнительным способом поиска SEO-специалистов.
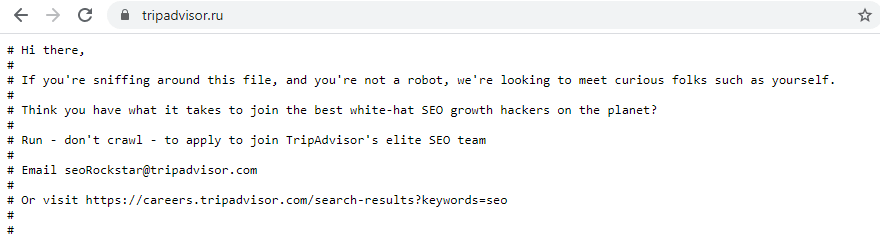
На сайте TripAdvisor:
На сайте маркетплейса Esty:
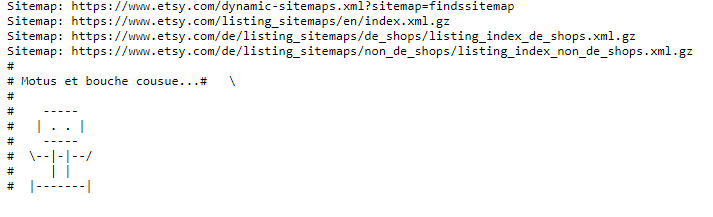
Таблица основных юзер-агентов ПС
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
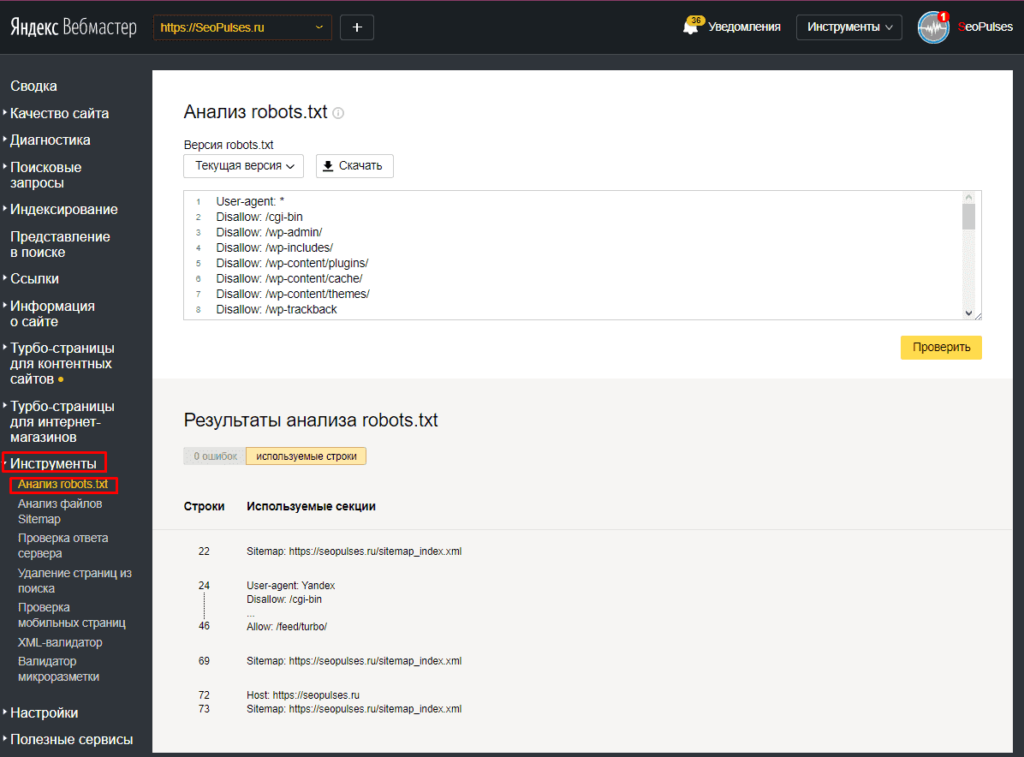
Также можно скачать другие версии файла или просто ознакомиться с ними.

Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
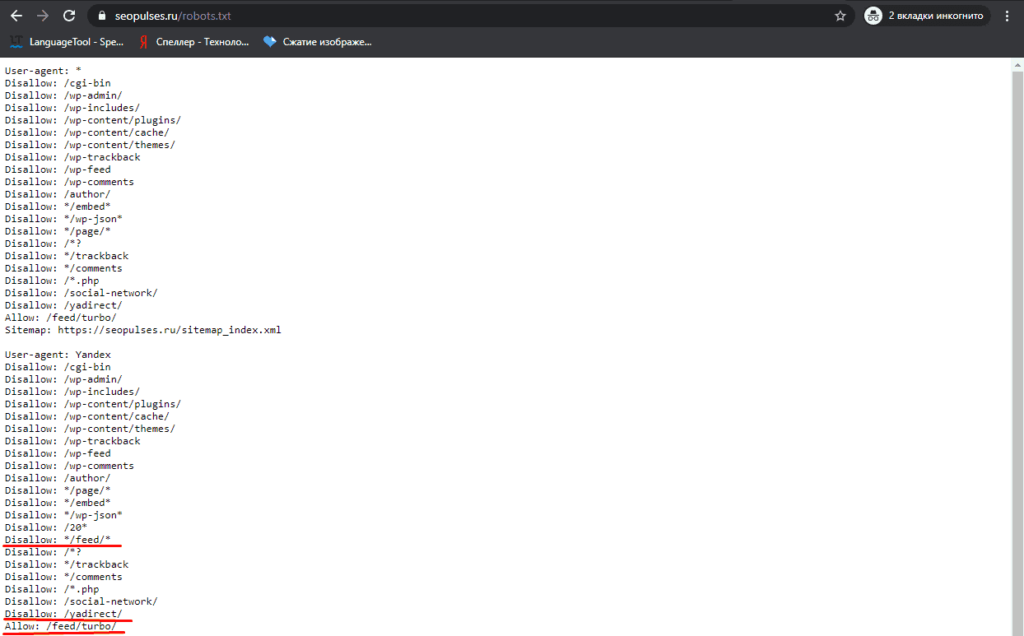
Как видим из примера все работает нормально.
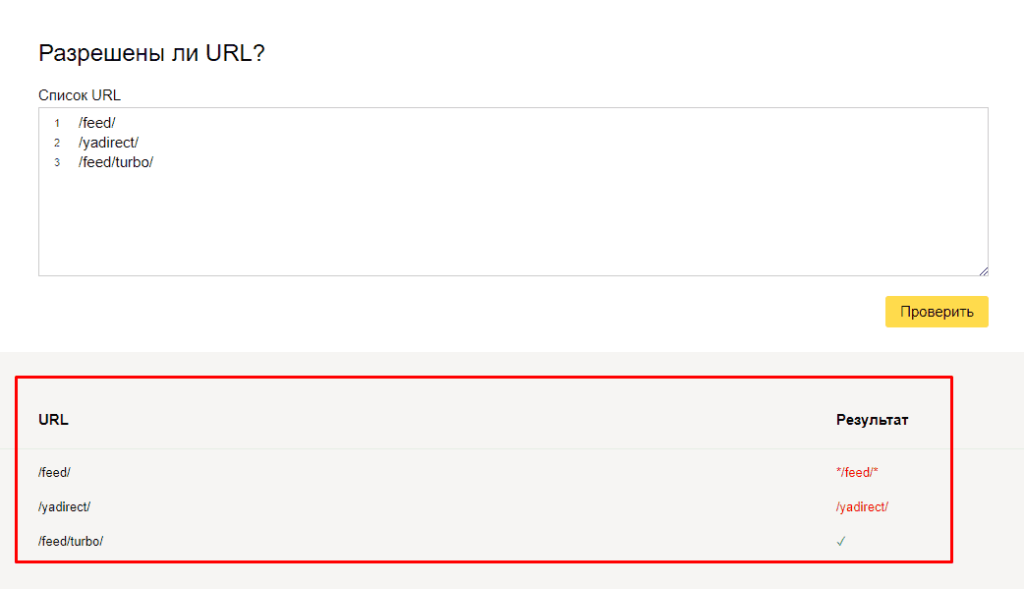
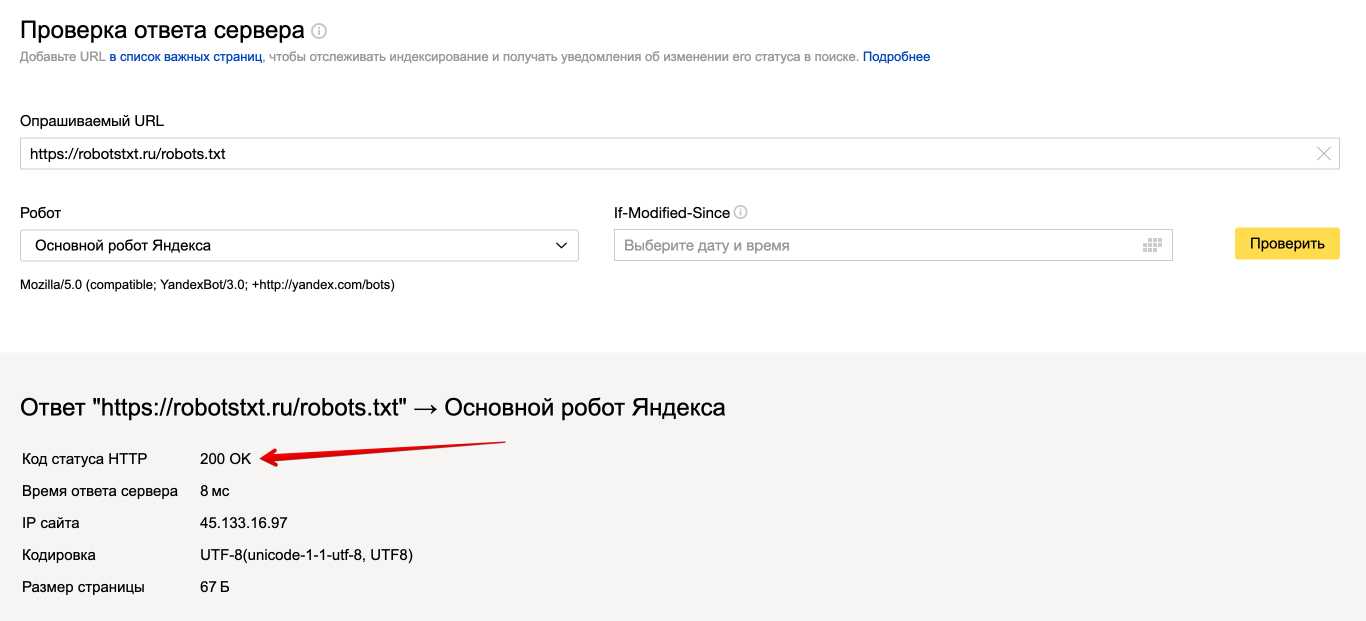
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
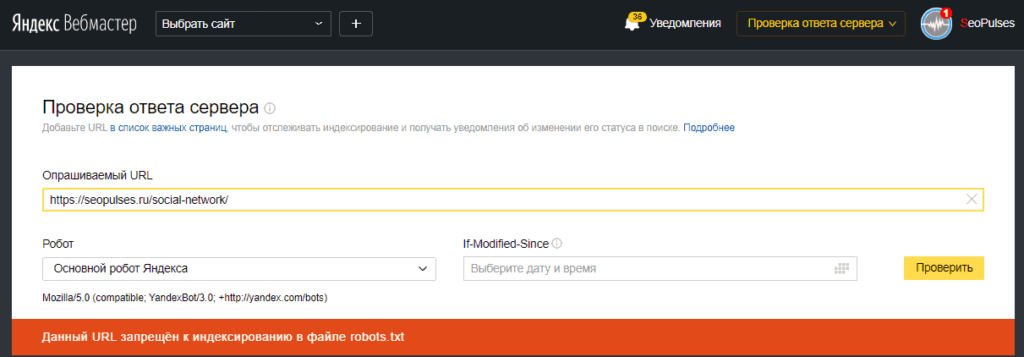
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
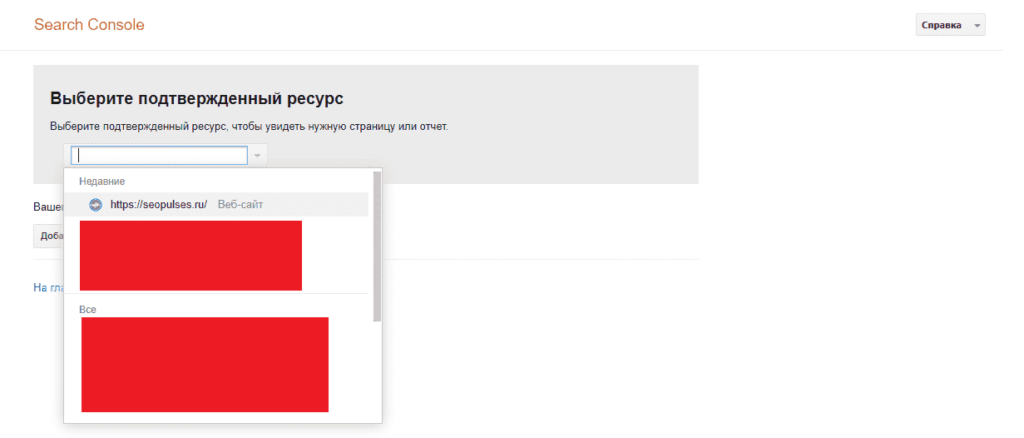
Важно! Ресурсы-домены в этом случае выбирать нельзя. Теперь мы видим:
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
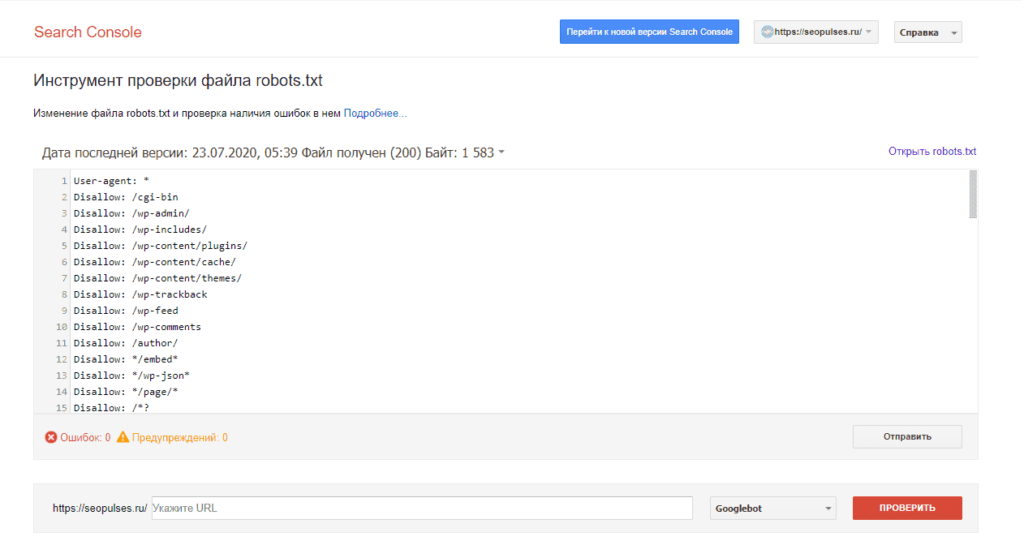
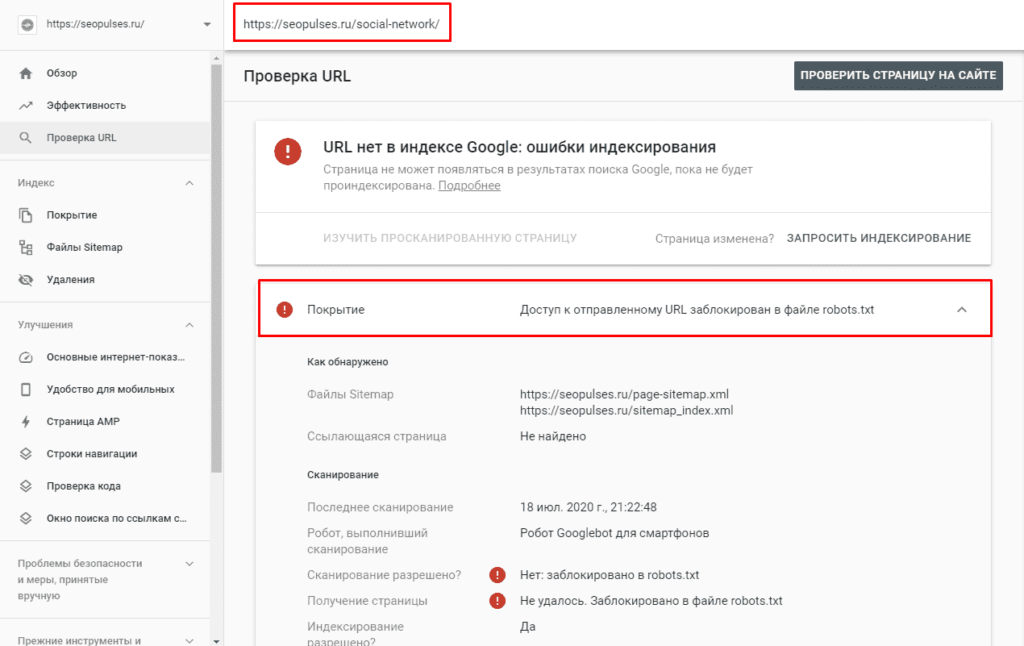
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».

Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Подписывайтесь на наш Telegram-канал
Подписывайтесь на наш Youtube-канал
Подписывайтесь на нашу группу ВКонтакте
Что такое robots.txt?
Отвечая на вопрос, что такое robots.txt это инструкция, хранящийся в формате текста на сервере. Текст robots.txt это команды, созданные из латинских символов. С помощью этой информации поисковые роботы понимают, какие страницы можно индексировать. Если не прописывать robots.txt, система будет индексировать все страницы, включая дубли или другой «мусор». Каждая строка robots.txt несет одну команду в форме директивы.

Robots.txt можно редактировать по необходимости, чтобы закрыть отдельные страницы от индексации. Чаще это лендинги под временные акции и распродажи, версии для печати, системные файлы и каталоги, пустые страницы.
При обработке robots.txt, роботы получают 3 правила для индексирования:
- Полный доступ дает разрешение для сканирования всего сайта.
- Частичный доступ позволяет сканировать отдельные элементы.
- При полном запрете Googlebot не сможет ничего просканировать.
Пример файла robots.txt
С целью закрепления понимания вышеописанной структуры и правил, приведем стандартный robots txt для CMS Data Life Engine.
User-agent: * # директивы предназначены для всех поисковых систем Disallow: /engine/go.php # запрещаем отдельные разделы и страницы Disallow: /engine/download.php # Disallow: /user/ # Disallow: /newposts/ # Disallow: /*subaction=userinfo # закрываем страницы с отдельными параметрами Disallow: /*subaction=newposts # Disallow: /*do=lastcomments # Disallow: /*do=feedback # Disallow: /*do=register # Disallow: /*do=lostpassword # Host: www.pingoblog.ru # указываем главное зеркало сайта Sitemap: https://pingoblog.ru/sitemap.xml # указываем путь до карты сайта User-agent: Aport # указываем направленность правил на ПС Aport Disallow: / # предположим, не хотим мы с ними дружить
Типичные ошибки
- robots.txt отсутствует;
- в robots.txt сайт закрыт от индексирования (Disallow: /);
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла;
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий;
- в файле указаны только директивы: Allow: *.css Allow: *.js Allow: *.png Allow: *.jpg Allow: *.gif при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий
- директива Host прописана несколько раз (неактуально);
- в Host не указан протокол https (неактуально);
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта;
Добавить с помощью Yoast SEO
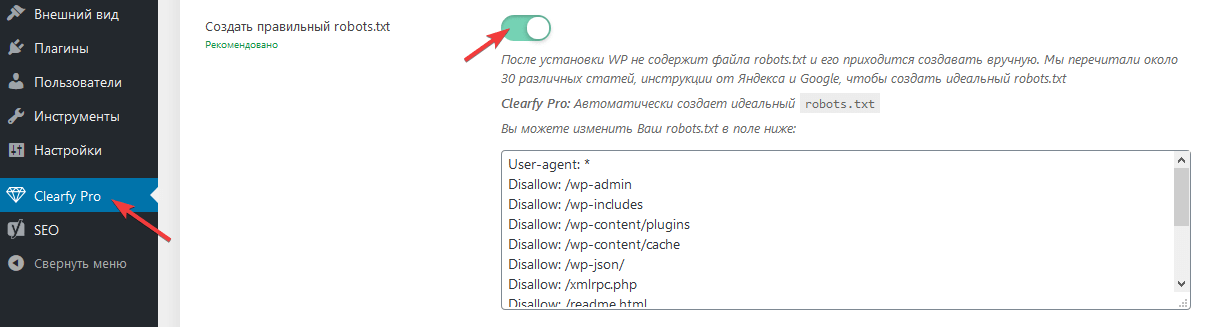
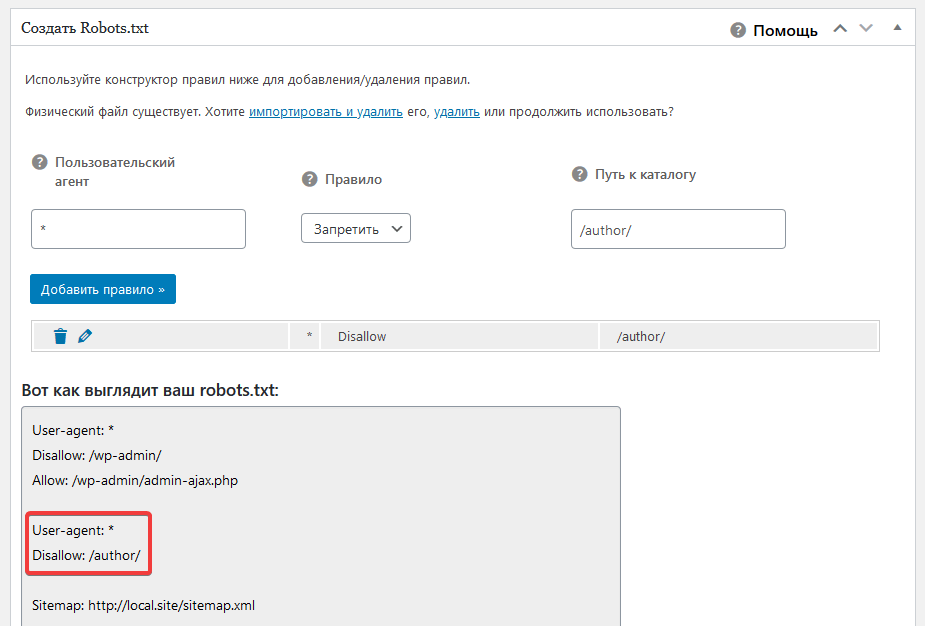
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
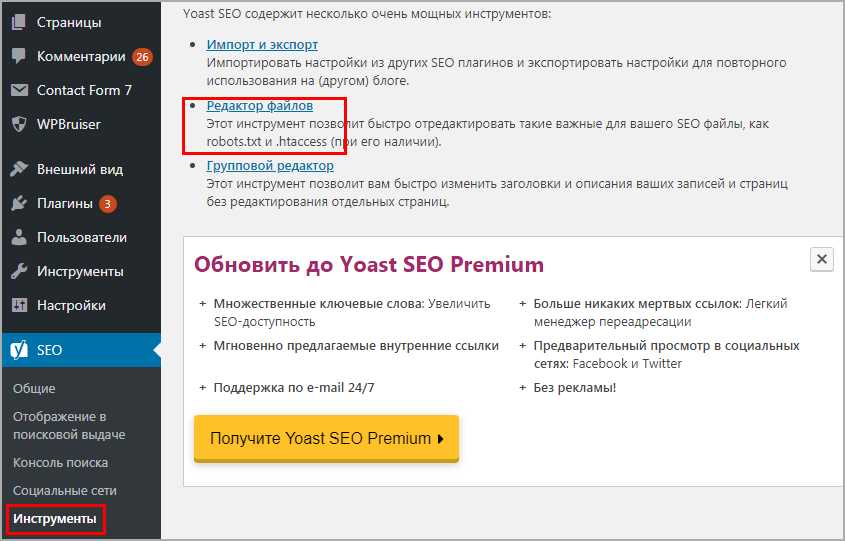 Yoast SEO редактор файлов
Yoast SEO редактор файлов
Если robots есть, то отобразится на странице, если нет есть кнопка «создать», нажимаем на нее.
 Кнопка создания robots
Кнопка создания robots
Выйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Как создать и куда поместить robots.txt?
Поскольку файл с директивами является самым простым текстовым файлом, то для его создания подойдёт любой редактор
Важно лишь при сохранении дать ему правильное название, то есть «robots.txt». Каждая команда внутри представляет собой отдельную строку
Готовый файл следует разместить в корневой директории сайта. Только в этом случае есть гарантия того, что он будет замечен и прочитан ботом. Если случайно перенести файл в другую папку, то поисковый механизм его просто не увидит, то есть останется бесконтрольным.
После чтения инструкций послушный бот заглянет только в те разделы, в которые ему разрешили доступ и проигнорирует все остальные.
Проверка robots.txt
Чтобы проверить правильность составленного файла — необходимо провести анализ. Для этого существуют два наиболее популярных инструмента:
Проверка robots.txt в Яндекс вебмастере или с помощью инструментов Google. ( Если вы еще не зарегистрировались в сервисах для Вебмастеров — советую это сделать незамедлительно. )
Я покажу как воспользоваться обеими вариантами, выбирайте сами какой больше нравиться. А еще лучше воспользуйтесь каждым, тем более это не займет больше пары минут.
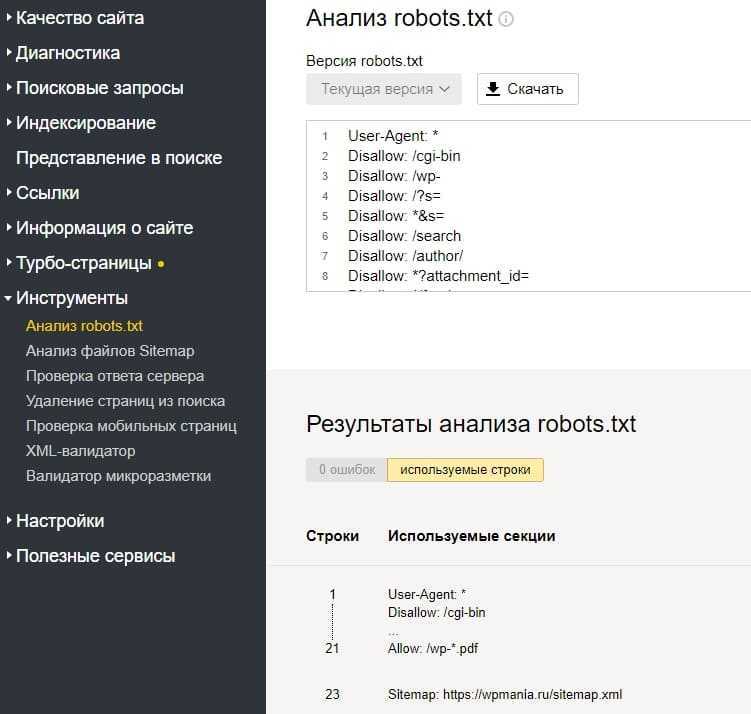
Проверка с помощью Яндекс Вебмастера
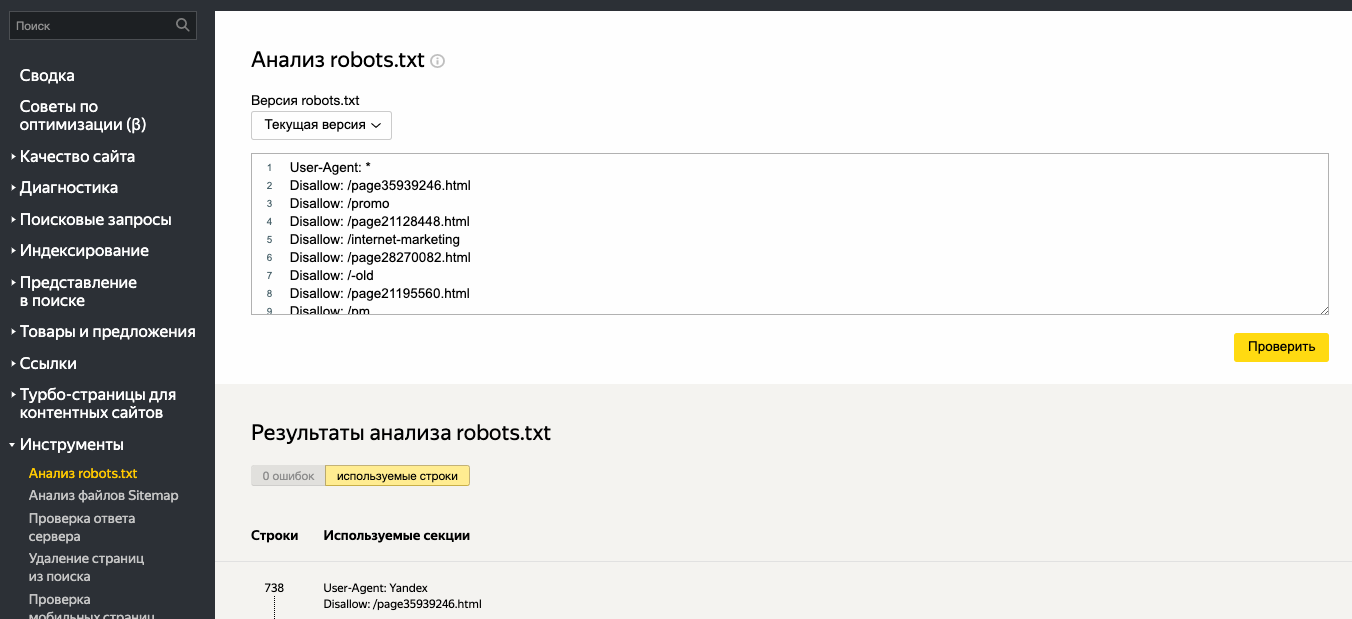
Заходим в инструменты в левом меню, и выбираем первый пункт Анализ robots.txt:
Добавляем ссылку на проверяемый сайт, нажимаем кнопку загрузки, а затем проверить.
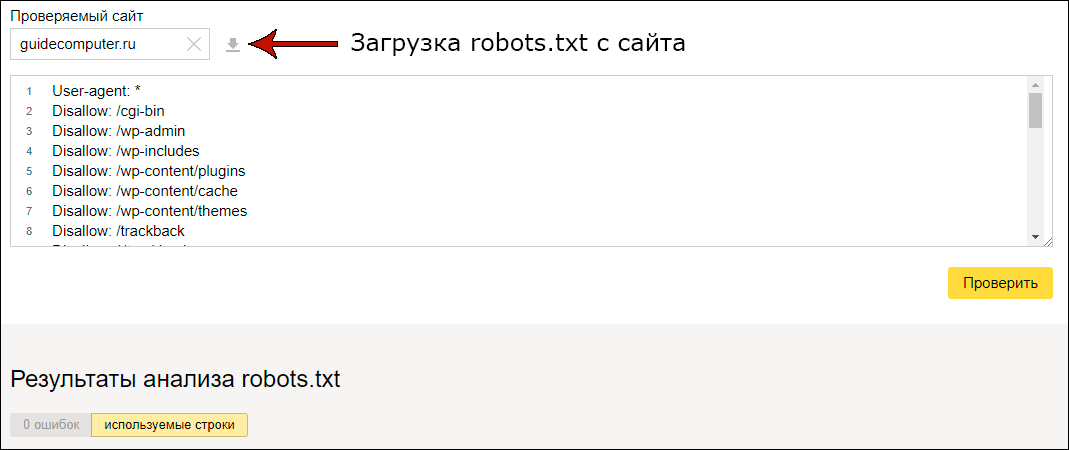
Немного ждем и смотрим Результаты анализа, в моем случае 0 ошибок.
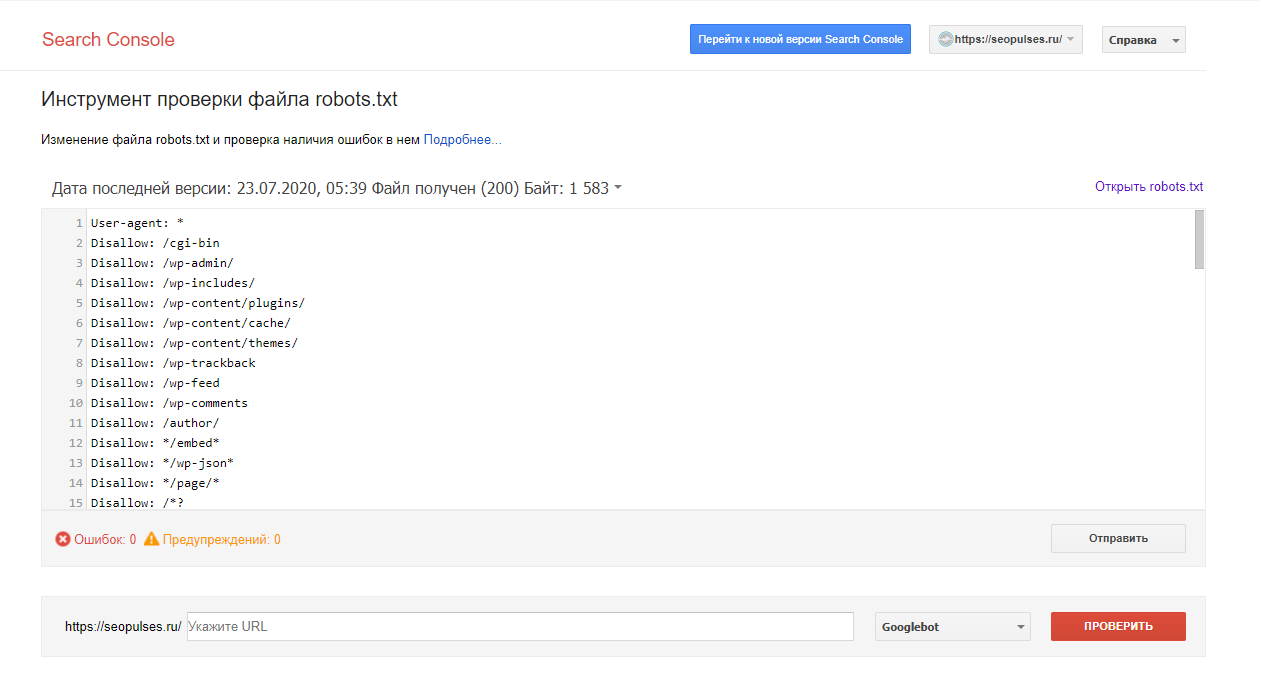
Проверка с помощью Search Console
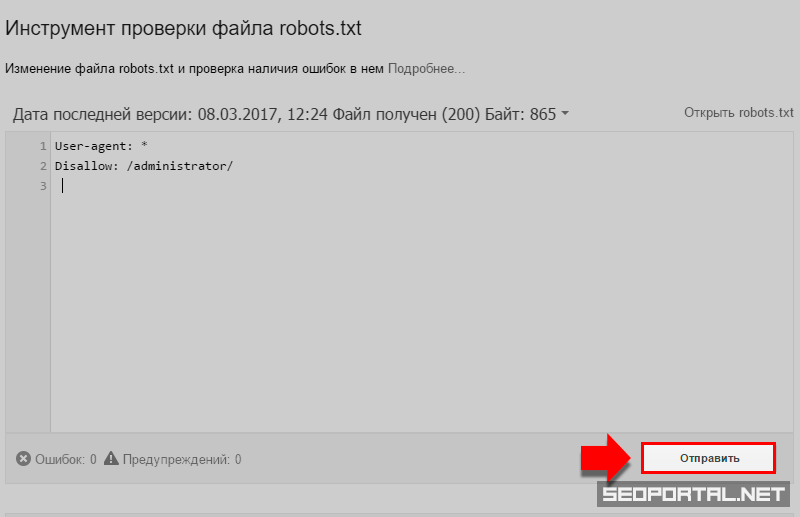
Заходим в Сканирование, выбираем раздел инструменты проверки файла:
Вставляем robots.txt и кликаем отправить.

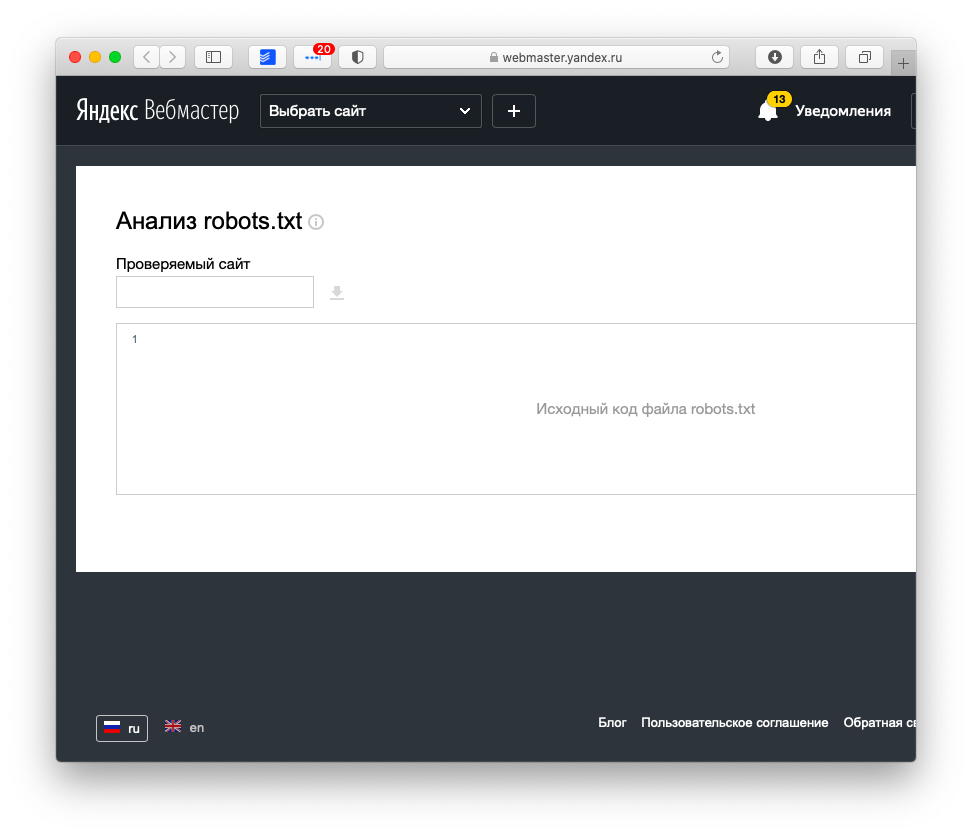

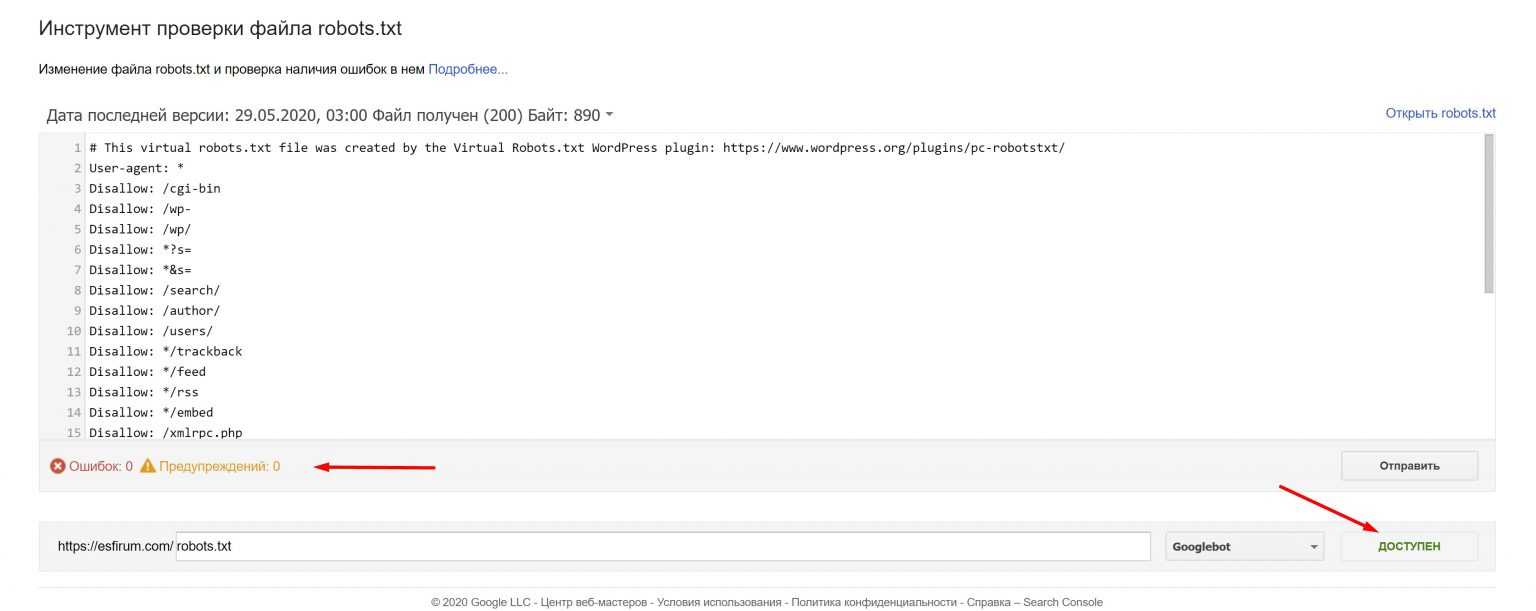


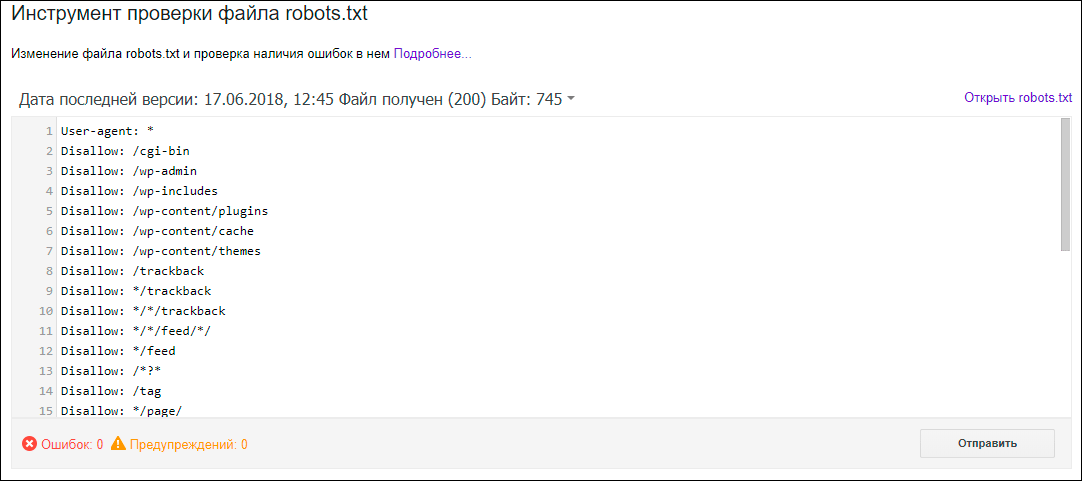
В 3-ем пункте выбираем отправить и смотрим на количество ошибок.
Как закрыть сайт от бота Google
Заблокировать поисковым роботам Google доступ к сайту можно также через robots.txt, HTML-разметку или указать инструкцию для Googlebot в HTTP-заголовке.
Как заблокировать доступ робота к странице через robots.txt
Основным поисковым роботом Google является Googlebot. Его задача – индексировать страницы и проверять их на адаптивность под мобильные устройства. Но также у Google есть десяток других ботов, каждый из которых выполняют свою задачу. Например, Googlebot-News сканирует страницу с новостями и добавляет их в Google Новости, Googlebot-Video индексирует видеоконтент на страницах сайта, а Googlebot-Image – изображения.
Управление индексированием сайта или отдельных его страниц для Googlebot в файле robots.txt происходит с помощью той же директивы Disallow, что и для поискового робота Яндекса.
То есть, для того чтобы закрыть обход всего сайта для бота Google, в файле укажите:
- User-agent: Googlebot
- Disallow: /
Если вам надо закрыть обход определенной страницы, пропишите такую директиву:
- User-agent: Googlebot
- Disallow: / page
Для закрытия обхода раздела прописывается директива:
- User-agent: Googlebot
- Disallow: / catalogue
Для закрытия раздела с новостями от индекса поисковым роботом Googlebot-News пропишите директиву:
- User-agent: Googlebot-News
- Disallow: / news
Если нужно закрыть сайт полностью от поисковых роботов Яндекса и Google, не обязательно прописывать для них разные директивы. Это можно сделать одной командой.
- User-agent: *
- Disallow: /
В первой строке вместо имени агента ставится знак «*».
Как запретить индексирование содержимого страницы через HTML-разметку
С помощью HTML-разметки можно закрыть от индексации роботом Google целую страницу или определенную ее часть. Для этого пропишите метатег «googlebot» с директивой noindex или none.
Для того чтобы ограничить боту Google доступ к странице вашего сайта, на HTML-странице вы можете прописать такие команды:
1. Если хотите скрыть определенный контент на странице и предупредить его появление на поиске и в Google News, пропишите команду:
2. Если хотите запретить индексирование определенных изображений на странице, пропишите команду:
3. Если на сайте очень быстро устаревает актуальность контента, например, у вас новостной портал, или вы проводите акции и не хотите, чтобы в индекс попадали страницы с неактуальной информацией, пропишите команду, когда страница должна быть удалена из индекса Google.
Например, вы разместили на сайте новость о проведении Черной пятницы. Срок окончания акции – 29 ноября. Команда будет выглядеть так:
Что касается индексирования ссылок, в Google есть два дополнительных параметра, которые указывают поисковику на происхождение линков:
- rel=»ugc» – используется в том случае, если у вас на ресурсе есть форум, где пользователи делятся отзывами и оставляют свои ссылки. В качестве таких ссылок сложно быть уверенным, и этот атрибут помогает роботу понять, откуда взялась ссылка.
- rel=»sponsored» – используется в том случае, если на сайте размещена рекламная ссылка, которая указывает на размещение в рамках партнерской программы.
Как проверить статус страницы в Google Search Console
В Google Search Console также предусмотрена возможность проверки статуса страницы. Для этого в боковой панели выберите раздел «Инструмент проверки URL», введите нужный адрес и кликните на «Изучить просканированную страницу».
Если страница исключена из индексирования, в отчете будет сообщение о том, что URL нет в индексе Google.
В Google Search Console также можно проверить все страницы сайта. Для этого перейдите в раздел «Статус индексирования» и сформируйте отчет с результатами сканирования. В отчете будут представлены результаты сканирования, сгруппированные по статусу (ошибка, предупреждение, без ошибок) и причине (код ответа HTTP).
Кроме Google Search Console и Яндекс Вебмастера существуют и другие инструменты и онлайн-сервисы, позволяющие проверить статус страниц сайта. Например, в PromoPult есть «Анализ индексации страниц», который быстро проверит индексацию всего сайта или отдельных страниц в Яндексе и Google. Нужно только загрузить XML-карту, XLSX-файл со списком URL или ввести нужные адреса страниц вручную. Подробная инструкция по работе с инструментом – здесь.
Что такое robots.txt и для чего он нужен
Robots.txt — это обычный текстовый файл с расширением .txt, который содержит директивы и инструкции индексирования сайта, его отдельных страниц или разделов для роботов поисковых систем.
Давайте рассмотрим самый простой пример содержимого robots.txt, которое разрешает поисковым системам индексировать все разделы сайта:
User-agent: * Allow: /
Данная инструкция дословно говорит: всем роботам, читающим данную инструкцию (User-agent: *) разрешаю индексировать весь сайт (Allow: /).
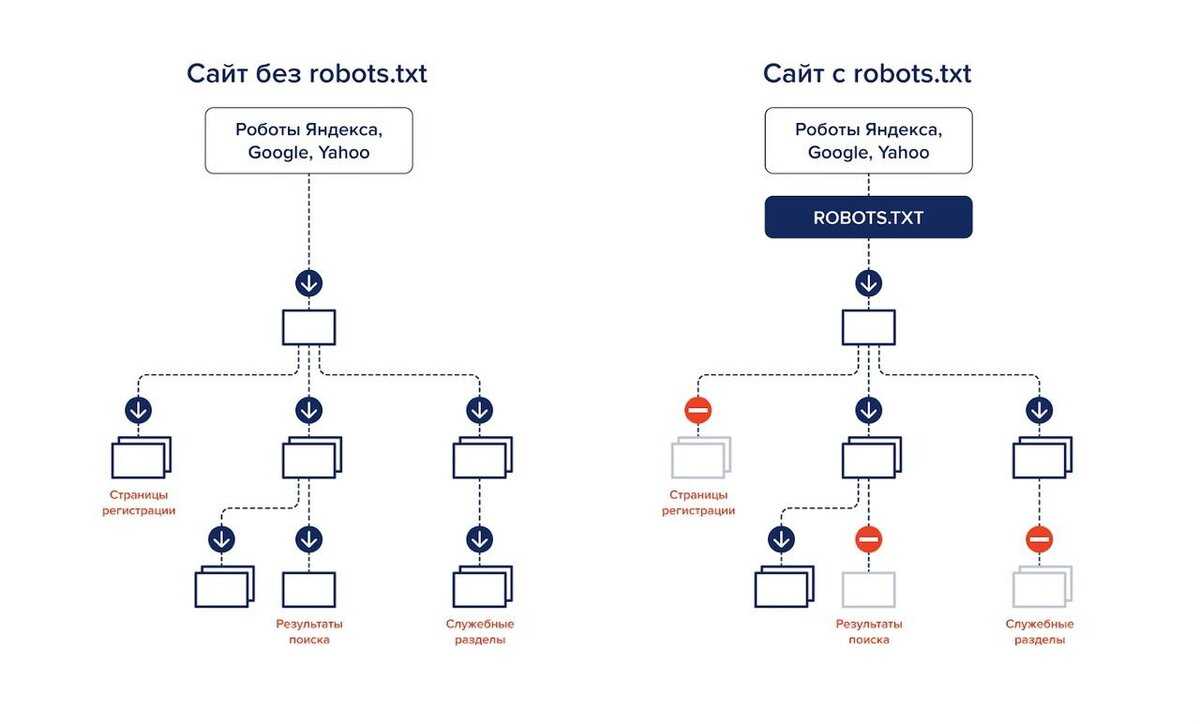
Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Представьте, что вы поисковый робот, которому нужно просмотреть миллиарды страниц по всем интернету, потом определить для каждой страницы запросы, которым они могут соответствовать и в конце проранжировать эту массу в поисковой выдаче. Согласитесь, задача не из легких. Для работы поисковых алгоритмов используются колоссальные ресурсы, которые, разумеется, ограничены.
Если помимо страниц, которые содержат полезный контент, и которые по задумке владельца сайта должны участвовать в выдаче, роботу придется просматривать еще кучу технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут тратиться впустую. Вы только представьте, что только один единственный сайт может генерировать тысячи страниц результатов поиска по сайту, дублирующихся страниц или страниц, не содержащих контента вообще. А если этот объем масштабировать на всю сеть, то получатся гигантские цифры и соответствующие ресурсы, которые необходимо тратить поисковикам.
Наличие огромного количества бесполезного контента на вашем сайте может негативно сказаться на его представлении в поиске. Как бы вы отнеслись к человеку, который дал вам мешок орехов, но внутри оказалась только скорлупа и всего 2-3 орешка? Не трудно представить и позицию поисковиков при аналогии данной ситуации с вашим сайтом.
Кроме того, существует такое понятие, как краулинговый бюджет. Условно, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, естественно, ограничен, но по мере роста проекта и повышения его качества, краулинговый бюджет может увеличиваться, но сейчас не об этом. Главное идея в том, в выдаче должны участвовать только страницы, которые содержат полезный контент, а весь технический «мусор» не должен засорять выдачу поисковым спамом.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
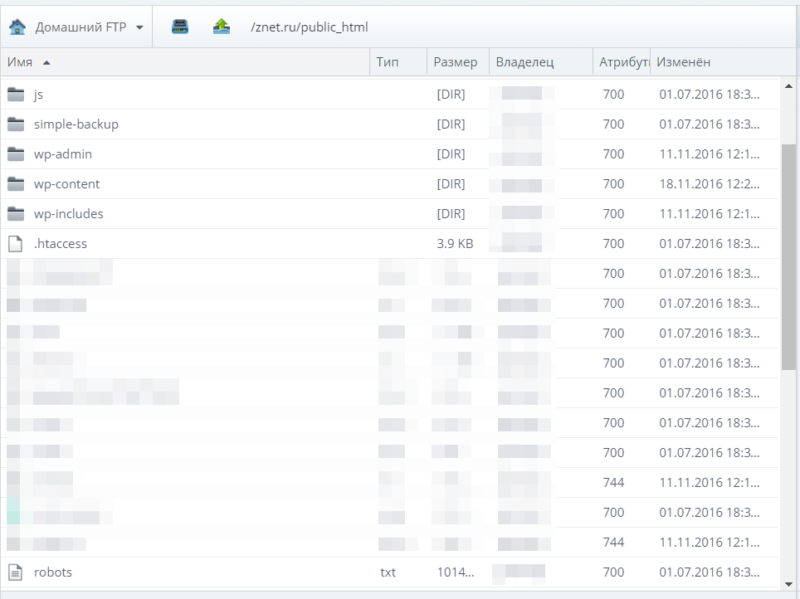
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего используют robots.txt?
К основным функциям документа можно отнести закрытие от сканирования страниц и файлов ресурса в целях рационального расхода краулингового бюджета. Чаще всего закрывают информацию, которая не несет ценности для пользователя и не влияет на позиции сайта в поиске.
Примечание. Краулинговый бюджет — количество страниц сайта, которое может просканировать поисковый робот
Для его экономии стоит направлять робота только к самому важному содержимому ресурса, закрывая доступ к малополезной информации
Какие страницы и файлы закрывают с помощью robots.txt
1. Страницы с персональными данными.
Это могут быть имена и телефоны, которые посетители указывают при регистрации, страницы личного кабинета, номера платежных карт. В целях безопасности доступ к этой информации стоит дополнительно защищать паролем.
2. Вспомогательные страницы, которые появляются только при определенных действиях пользователя.
К ним можно отнести сообщения об успешно оформленном заказе, клиентские формы, страницы авторизации или восстановления пароля.
3. Админпанель и системные файлы.
Внутренние и служебные файлы, с которыми взаимодействует администратор сайта или вебмастер.
4. Страницы поиска и сортировки.
5. Страницы фильтров.
Результаты, которые отображаются после применения фильтров (размер, цвет, производитель и т.д.), являются отдельными страницами и могут быть расценены как дубли контента. SEO-специалисты, как правило, ограничивают их сканирование, за исключением ситуаций, когда они приносят трафик по брендовым и другим целевым запросам.
6. Файлы определенного формата.
К ним могут относиться фото, видео, PDF-документы, JS-скрипты. С помощью robots.txt можно ограничивать сканирование файлов как по отдельности, так и по определенному расширению.
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
Разберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам Блок с Disallow запрещает к индексу все технические страницы и дубли
обратите внимание что я заблокировал папки начинающиеся на wp- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен». Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress
Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.



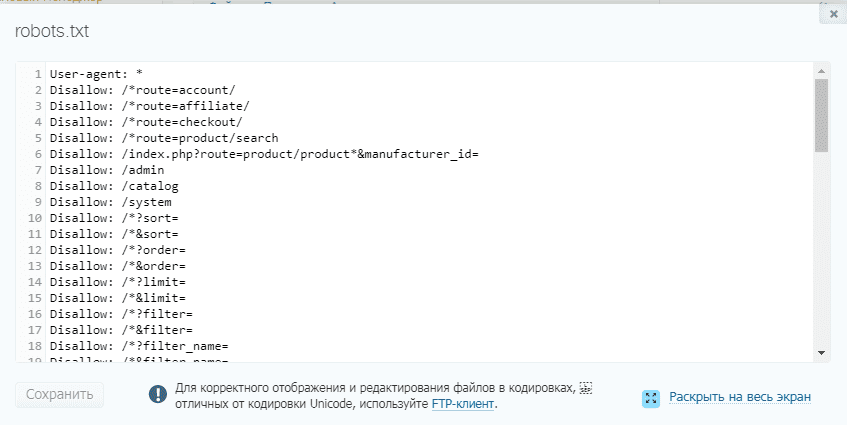
Адрес в строке запроса
Чего стоит избегать при настройке robots.txt?
Будьте внимательны: хоть robots.txt непосредственно и не влияет на то, окажется ли ваш сайт в выдаче, этот файл помогает избежать попадания в индекс тех страниц, которые должны быть скрыты от пользователей. Все, что робот не сможет интерпретировать, он проигнорирует.
Вот несколько частых ошибок, которые можно допустить при настройке.
Не указан User-Agent
Или указан после директивы, например:
Такую директиву робот прочитает так:
Disallow: /wp-admin/— так, это не мне, не читаю
User-agent: * — а это мне… Дальше ничего? Отлично, обработаю все страницы!
Любые указания к поисковым роботам должны начинаться с директивы User-agent: название_бота.
Или для всех сразу:
Несколько папок в Disallow
Если вы укажете в директиве Disallow сразу несколько директорий, неизвестно, как робот это прочтет.
По своему разумению он может обработать такую конструкцию как угодно. Чтобы этого не случилось, каждую новую директиву начинайте с нового Disallow:
Регистр в названии файла robots.txt
Поисковые роботы смогут прочитать только файл с названием “robots.txt”. “Robots.txt”, “ROBOTS.TXT” или “R0b0t.txt” они просто проигнорируют.
$ и другие спецсимволы
Нужно помнить, что при внесении любых директив по умолчанию в конце приписывается спецсимвол *. В результате получается, что действие указания распространяется на все разделы или страницы сайта, начинающиеся с определенной комбинации символов.
Чтобы отметить действие по умолчанию, применяется специальный символ $.
Пример использования:
User-agent: Googlebot
Disallow: /pictures$ # запрещает ‘/pictures’,
# но не запрещает ‘/pictures.html’
Стандарт использования файла robots.txt рекомендует, чтобы после каждой группы директив User-agent вставлялся пустой перевод строки. При этом специальный символ # применяется для размещения в файле комментариев. Роботы не будут учитывать содержание в строке, которое размещено за символом # до знака пустого перевода.
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
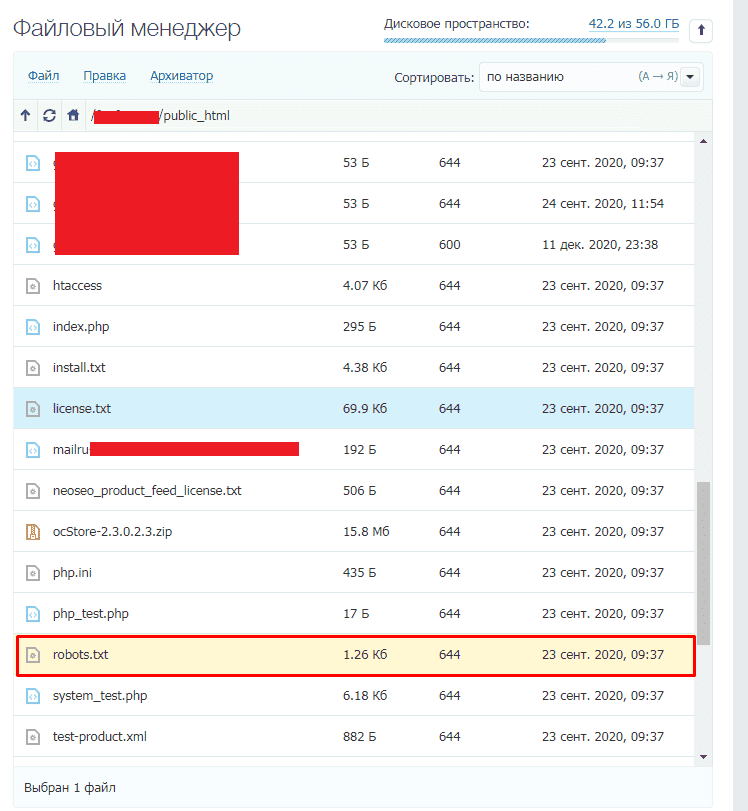
Далее открываем сам файл и можно его редактировать.
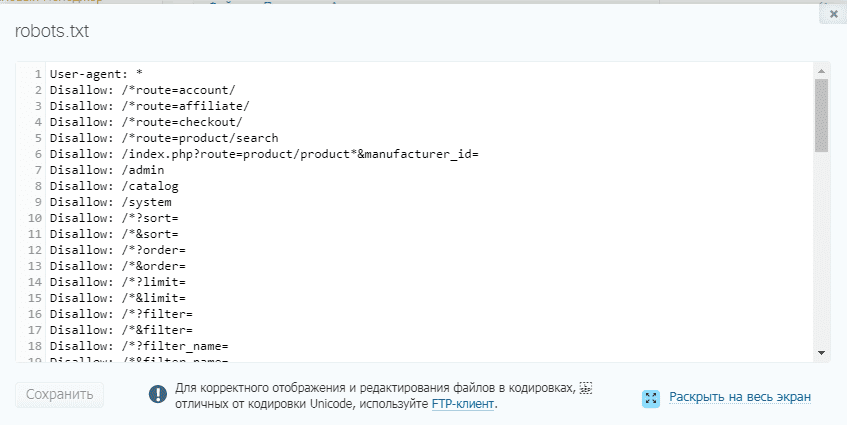
Если его нет, то достаточно создать новый файл.

После вводим название документа и сохраняем.

Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814

WordPress;
Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Что исключать из индекса с помощью robots.txt?
Robots.txt это возможность управлять поисковыми алгоритмами и направить их на главные страницы сайта, которые будут видеть пользователи. Правильный robots.txt не должен содержать следующие пункты:
- Дубли страниц. Каждая из них имеет индивидуальный URL с уникальным контентом;
- Страницы с неуникальным контентом;
- Данные с показателями сессий;
- Файлы, связанные с системой CMS и управлением сайтом (шаблоны, темы, панель администратора).
Исключать с помощью robots.txt это значит закрыть все, что не приносит пользу, а также то, что еще находится на стадии доработки или разработки, дублируется, нерелевантные страницы.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида .
WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Директива во второй строке закроет доступ по всем каталогам, начинающимся на , в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Служебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Далее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент
Такие страницы с параметрами следует запрещать аналогичным образом:
Это правило распространяется на простые постоянные ссылки , страницы с поисковыми запросами и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску , тем самым запрещая индексирование архивов по годам:
Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива — указывает на главное зеркало для Яндекса:
При работе сайта по HTTPS необходимо указать протокол:
С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Структура и правильная настройка файла robots.txt
Как должен выглядеть правильный файл robots txt для сайта? Структуру можно описать следующим образом:
1. Директива User-agent
Что писать в данном разделе? Эта директива определяет то, для какого именно робота предназначены нижеизложенные инструкции. Например, если они предназначены для всех роботов, то достаточно следующей конструкции:
User-agent: *
В синтаксисе файла robots.txt знак «*» равноценен словосочетанию «что угодно». Если же требуется задать инструкции для конкретной поисковой системы или робота, то на месте звездочки из предыдущего примера пишется его название, например:



User-agent: YandexBot
У каждого поисковика существует целый набор роботов, выполняющих те или иные функции. Роботы поисковой системы Яндекс описаны тут. В общем же плане имеется следующее:
- Yandex — указание на роботов Яндекс.
- GoogleBot — основной индексирующий робот .
- MSNBot — основной индексирующий робот Bing.
- Aport — роботы Aport.
- Mail.Ru — роботы ПС Mail.
Если имеется директива для конкретной поисковой системы или робота, то общие игнорируются.
2. Директива Allow
Разрешает отдельные страницы раздела, если, скажем, ранее он целиком закрыт от индексации. Например:
User-agent: *
Disallow: /
Allow: /открытая-страница.html
В данном примере мы запрещаем к индексации весь сайт, кроме страницы poni.html
Служит эта директива в какой-то степени для указания на исключения из правил, заданных директивой Disallow. В случае, если таких ситуаций нет, то директива может не использоваться совсем. Она не позволяет открыть сайт для индексации, как многие думают, так как если нет запрета вида Disallow: /, то он открыт по умолчанию.
2. Директива Disallow
Является антиподом директивы Allow и закрывает от индексации отдельные страницы, разделы или сайт целиком. Являет аналогом тега noindex. Например:
User-agent: *
Disallow: /закрытая-страница.html
3. Директива Host
Используется только для Яндекса и указывает на основное зеркало сайта. Выглядит это так.
Основное зеркало без www:
Host: site.ru
Основное зеркало с www:
Host: www.site.ru
Сайт на https:
Host: https://site.ru
Нельзя записывать директиву host в файл дважды. Если же вследствие какой-то ошибки это произошло, то обрабатывается та директива, которая идет первой, а вторая — игнорируется.
4. Директива Sitemap
Используется для указания пути к XML-карте сайта sitemap.xml (если она есть). Синтаксис следующий:
Sitemap: http://www.site.ru/sitemap.xml
5. Директива Clean-param
Используется для закрытия от индексации страниц с параметрами, которые могут являться дублями. Очень полезная на мой взгляд директива, которая отсекает параметрический хвост урлов, оставляя только костяк, который и является родоначальным адресом страницы.
Скажем, у нас имеется страница:
http://www.site.ru/index.php
И эта страница в процессе работы может обрастать клонами вида.
http://www.site.ru/index.php?option=com_user_view=remind
http://www.site.ru/index.php?option=com_user_view=reset
http://www.site.ru/index.php?option=com_user_view=login
Для того, чтобы избавиться от всевозможных вариантов этого спама, достаточно указать следующую конструкцию:
Clean-param: option /index.php
Синтаксис из примера, думаю, понятен:
Clean-param: # указываем директиву
option # указываем спамный параметр
/index.php # указываем костяк урла со спамным параметром
Если параметров несколько, то просто перечисляем их через амперсант(&):
http://www.site.ru/index.php?option=com_user_view=remind&size=big # урл с двумя параметрами
Clean-param: option&big /index.php # указаны два параметра через амперсант
Пример взят простой, поясняющий саму суть. Особенно спасибо этому параметру хочется сказать при работе с CMS Bitrix.
Директива Crawl-Delay
Позволяет задать таймаут на загрузку страниц сайта роботом Яндекс. Используется при большой загруженности сервера, при которой он просто не успевает быстро отдавать содержимое. На мой взгляд, это анахронизм, который уже не учитывается и который можно не использовать.
Crawl-delay: 3.5 #таймаут в 3,5 секунды
Типичные ошибки
Ошибки в robots.txt кардинально различаются по степени влияния на ранжирование сайта. Старайтесь минимизировать количество ошибок для наилучшего индексирования вашего сайта!
Ошибка
Важность
Влияние на индексирование
Использование «Disallow: /»
Критичная
Блокирует индексирование сайта. Может полностью исключить сайт из поисковой выдачи.
Закрытие всех параметров «Disallow: /*?»
Важная
Директива блокирует индексирование страниц с параметрами
Сигналы ранжирования на основную страницу не передаются, в отличие от ситуаций, когда используются Clean-param или теги canonical. Также могут быть заблокированы CSS и JS-файлы, из-за чего поиск может некорректно индексировать страницы, что плохо для ранжирования.
Закрытие файлов с изображениями, скриптами или стилями CSS
Важная
Кроме параметрических URL, пути до картинок, CSS и JS-файлов могут быть закрыты напрямую. Это может ухудшить индексирование контента страниц, а также исключить ранжирование в Яндекс и Google Картинках.
Пустая директива User-agent
Важная
Не указаны поисковые роботы, для которых обозначены правила. Из-за этой ошибки robots.txt может быть невалиден.
Правило начинается не с символа «/» и не с символа «*»
Средняя
Если после директив Disallow или Allow нет символа «/» или «*», директивы не будут работать.
Не указан путь к XML-карте сайта или указан относительный путь
Низкая
Если вы не указали путь к XML-картам сайта в файле robots.txt, то вам необходимо добавить их вручную в сервисы Яндекса и Google для веб-мастеров. Иначе поисковые системы их могут не найти.