
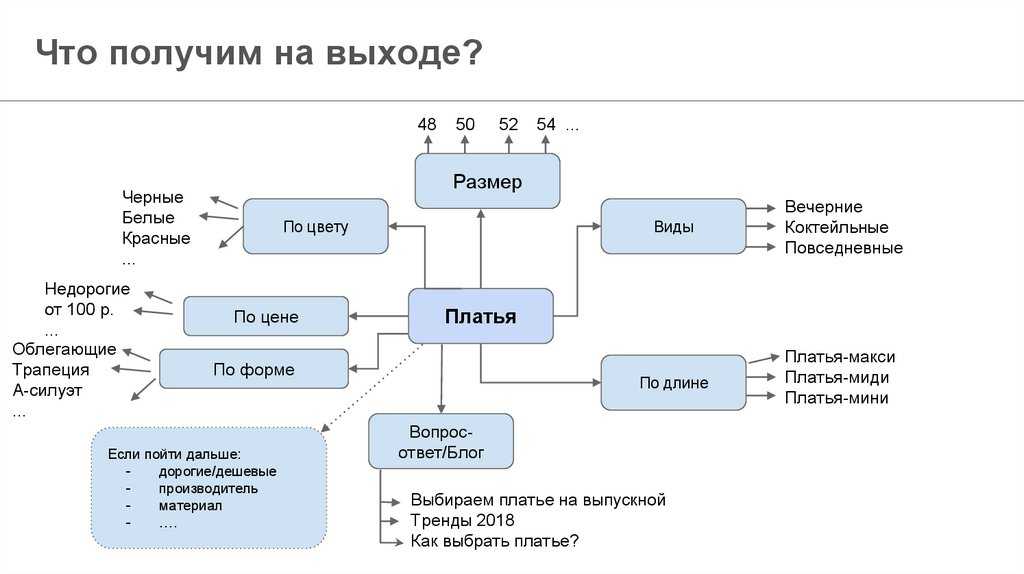
SEO анализ текста онлайн бесплатно.
Всем привет. Практически любой продвигаемый сайт содержит SEO текст, который является основным ключевым игроком для продвижения в поисковых системах. Всеми уже знакомые ключевые слова, объемы символов, уникальность и другие параметры текста. Уверен, что уже все наслышаны обо всем этом. Но не все имеют правильное представление SEO текста
Большинство акцентирует свое внимание на объем и уникальность текста
Но зная даже все правила написания грамотных статей, как мы можем посмотреть текст глазами машины? Ведь то, что для человека читаемый текст, машина по своему алгоритму может посчитать водой. На помощь SEO-шникам приходит сервис, который делает детальный SEO анализ текста от биржи текстов Advego. Сервис SEO анализа текстов бесплатный и не требует регистрации.
SEO анализ текста онлайн бесплатно
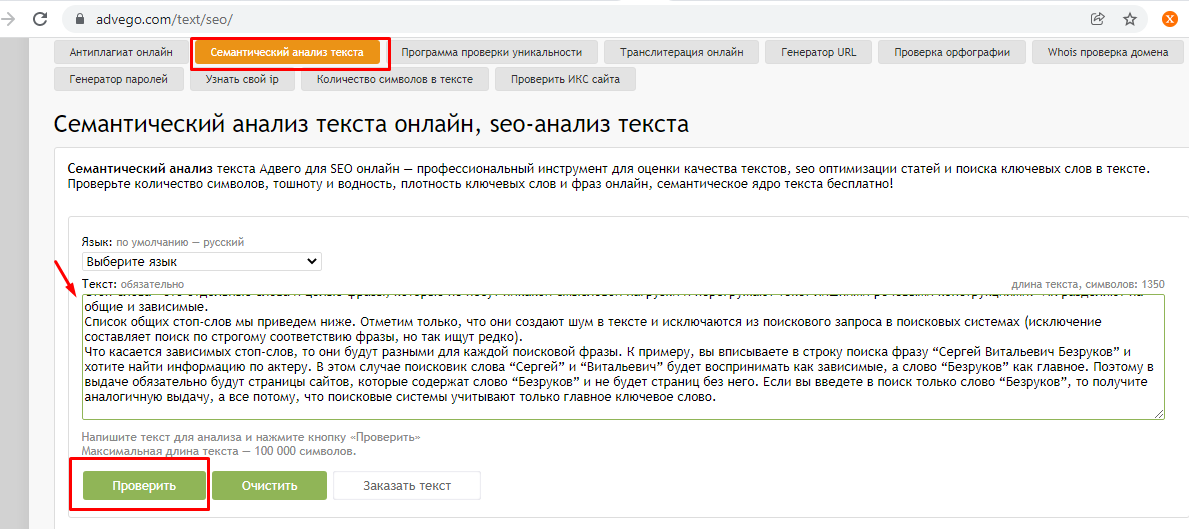
Для начала перейдите на страницу проверки. Перед вами откроется довольно простое окно с единственной функцией, которая позволяет выбрать язык проверяемого текста. Система позволяет проверить огромное количество языков. В том числе три самых важных русский, украинский и английский.
После чего выберите текст, который необходимо проверить. Я для примера выбрал текст своей статьи, которую я писал недавно про поведенческие факторы. Скопируйте текст в окошко (вы сразу сможете увидеть количество символов, но с учетом пробелов) и нажмите кнопку проверить:
После выполнения SEO анализа текста, который, кстати, занимает всего лишь пару секунд, вы получите детальную информацию
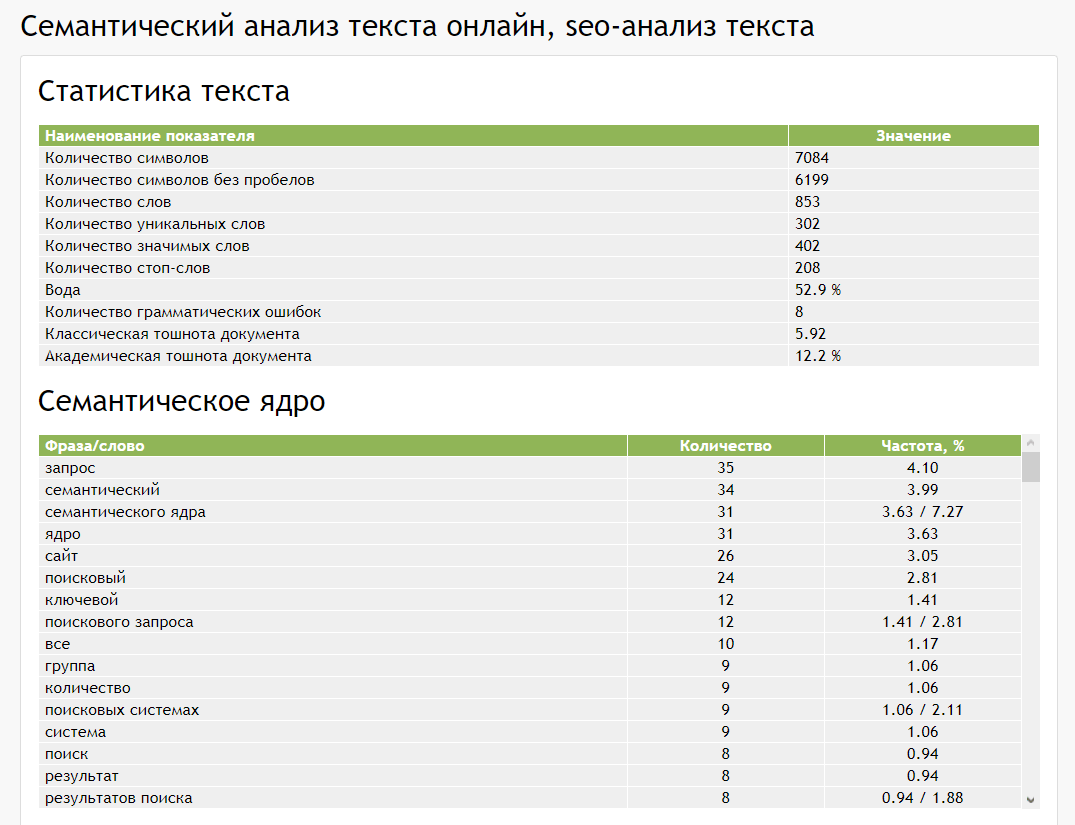
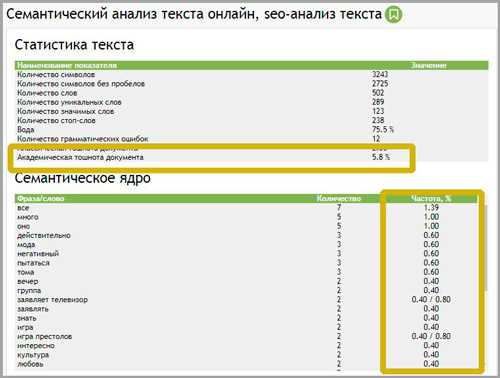
Первое и самое главное, на что надо обращать внимание это статистика текста. В этой таблице вы можете посмотреть следующие важные данные:
- количество слов
- количество символов без пробела
- количество грамматических ошибок
- количество стоп-слов
- классическая тошнота документа
- академическая тошнота документа
Классическая тошнота документа – это количество повторений одного и того же слова в тексте. Определяется как корень из квадрата количества слов. Классическая тошнота не должна превышать отметки 7, так как чем она выше, тем тошнота больше тем трудней продвигать сайт.
Академическая тошнота документа – это повторяющееся количество разных слов в тексте. Чем таких слов больше, тем и больше академическая тошнота. Показатель зависит от объема текста и количества повторяющихся слов.
Стоп — слова – это слова, которые не имеют определенной пользы, смысловой нагрузки. В основном, это предлоги, местоимения, частицы и т.д. Чем меньше количество слов, тем лучше для текста.
На странице есть и другая важная информация, например семантическое ядро статьи. С этой таблице вы можете посмотреть количество повторения одинаковых слов, как и в числовом значении так и в процентном соотношении. Вот и весь процесс SEO анализа текста, после которого вы можете решать соответствует он результат вашим ожиданиям и стоит ли его публиковать на сайте.
Стоит ли придерживаться строгих границ нормы при SEO-анализе
Нет, потому что SEO-проверка текста помогает проверить его качество при беглой оценке. И далеко не факт, что алгоритмы поисковых систем учитывают те же параметры, что и SEO-анализаторы.
Кроме того, алгоритмы «Яндекс» и Google постоянно меняются
То, что было важно еще месяц назад, сейчас может никак не влиять на ранжирование и попадание в топ. Например, сегодня уникальность уже не важна: согласно исследованию Группы компаний ПРОФ о влиянии уникальности контента на продвижение сайта, можно выйти в топ и со статьями, которые скопированы с других сайтов
Поэтому не гонитесь за строгими нормами: они могут не отражать реального качества контента. В попытке достичь желаемого уровня тошноты или водности можно получить текст, который будет качественным с точки зрения сервисов, но сложно читаемым с точки зрения обычного пользователя.
Помните, SEO-параметры текста – не самое главное. Лучше следить не за показателями, а за тем, насколько полно контент отвечает на запрос пользователя, интересный ли он и легко ли его читать. Если вы не можете писать качественные статьи своими силами, то наймите проверенных специалистов в каталоге специалистов по созданию текстового контента на площадке Workspace. Хороший автор напишет такой материал, который понравится и пользователям, и поисковым системам.
Какие показатели текста проверяют семантическим анализом
В интернете много сервисов, которые выполняют SEO-анализ текста. Самые популярные – text.ru, Адвего. Они бесплатные.
Важно: эти сервисы используют разные алгоритмы, поэтому у одной и той же статьи значения показателей будут разными. В ТЗ обычно указывают конкретный сервис для проверки и нужные параметры
Водность документа
Водность показывает, сколько процентов слов в тесте не несут смысловой нагрузки – их называют стоп-словами. Это могут быть разные части речи:
- предлоги
- союзы
- вводные слова и словосочетания
- местоимения
- многочисленные словесные штампы
- междометия
- наречия.
К этой категории относятся слова-паразиты и популярные обороты, которые можно отнести к любой нише. Чем больше таких слов в тексте, тем выше процент водности и хуже качество текста с позиции поисковых систем и сео.

Вот так подсвечивает водность текста сервис text.ru
Как влиять на количество стоп-слов в документе
Совсем обойтись без стоп-слов невозможно, потому что некоторые из них — это служебные части речи. В то же время переизбыток негативно сказывается на качестве статьи – это сигнал Яндексу, что текст неполезный.
Можно уменьшить количество стоп-слов, если следить за речью. Обычно чаще других повторяется союз «и». Старайтесь не употреблять его без надобности, лучше поставить запятую.
Второе место по частоте занимают предлоги. Если сео-анализ текста покажет, что некоторые повторяются чаще остальных слов, перефразируйте предложения по-другому.
Еще один лидер – личные местоимения. Если они часто встречается в статье, поработайте над текстом.
В итоге количество «воды» в тексте заметно уменьшится.
Классическая тошнота документа
Ее рассчитывает сервис Адвего. Классическая тошнота документа зависит от вашего словарного запаса. Когда вы употребляете одни и те же слова, этот показатель растет и ухудшает качество текста.
Классическую тошноту вычисляют по формуле: корень квадратный от числа вхождений самого частого слова в тексте.
До недавнего времени верхнее допустимое значение было 7, а нормальное — 2-5. Но алгоритмы Яндекса постоянно меняются. Сегодня нормальным показателем классической тошноты считают 5 на 20 000 знаков текста. При уменьшении объеме текста эта норма снижается.
Я нигде не встречала конкретных норм для конкретных объемов текста. Поэтому высчитываю, исходя из предложенного сервисом «Адвего» нормального значения 5 на 20 000. Логика такая:
- 5 — это корень квадратный из 25. Значит, на 20 000 знаков текста допускается 25 повторов самого частотного слова — у меня это чаще всего предлог «в» или союз «и».
- дальше составляю обычную пропорцию: если на 20 000 норма 25 слов, то на 3000 — Х. И этот показатель нужно узнать. Перемножаем 3000 и 25 и делим на 20 000. Получаем 3,75 — это нормальное количество повторов самого частого слова в тексте объемом 3000 знаков. Извлекаем из него квадратный корень и получаем 1,93.
Вместо цифры 3000 нужно подставлять тот объем текста, который у вас получился, и высчитывать по этой формуле для каждого конкретного случая.
Если заказчик в ТЗ указал конкретную цифру по сервису Адвего, нужно добиваться этого показателя, снижая количество повторов.
Подсказка. Если самые частые слова — предлоги и союзы, предложения нужно перефразировать, чтобы убрать лишние служебные части речи. Если это полноценные слова — существительные, прилагательные, глаголы — нужно часть из них заменить синонимами, чтобы уменьшить количество повторов.
Академическая тошнота документа
Академическая тошнота — это процентное соотношение повторов к общему количеству слов. Тоже зависит от словарного запаса, но высчитывается по другой формуле — это автоматически делает сервис, когда загружаем в него текст для SEO-анализа. При определении академической тошноты учитываются все слова, которые использовались неоднократно, в том числе и стоп-слова. Как раз они в большей степени влияют на показатель — он в идеале не должен превышать 8%. Максимум – 10%.
Уменьшить значение академической тошноты документа можно с помощью синонимов. Например, если слово «текст» повторить 10 раз в статье на 2000 знаков и на 3000 знаков – это не одно и то же. Во втором случае показатель тошноты будет меньше, так как общее количество слов – больше. Но имейте в виду, что тошнота высчитывается не по каждому повторяемому слову в отдельности, а по всем сразу.
Если заказчик не указал в ТЗ значения тошноты, можно сделать проще: загнать текст в сервис text.ru и проверить процент заспамленности. Суть инструмента та же – контролировать число повторов. Ориентируйтесь, чтобы было в пределах нормы – слишком высокий процент покажет красным цветом.


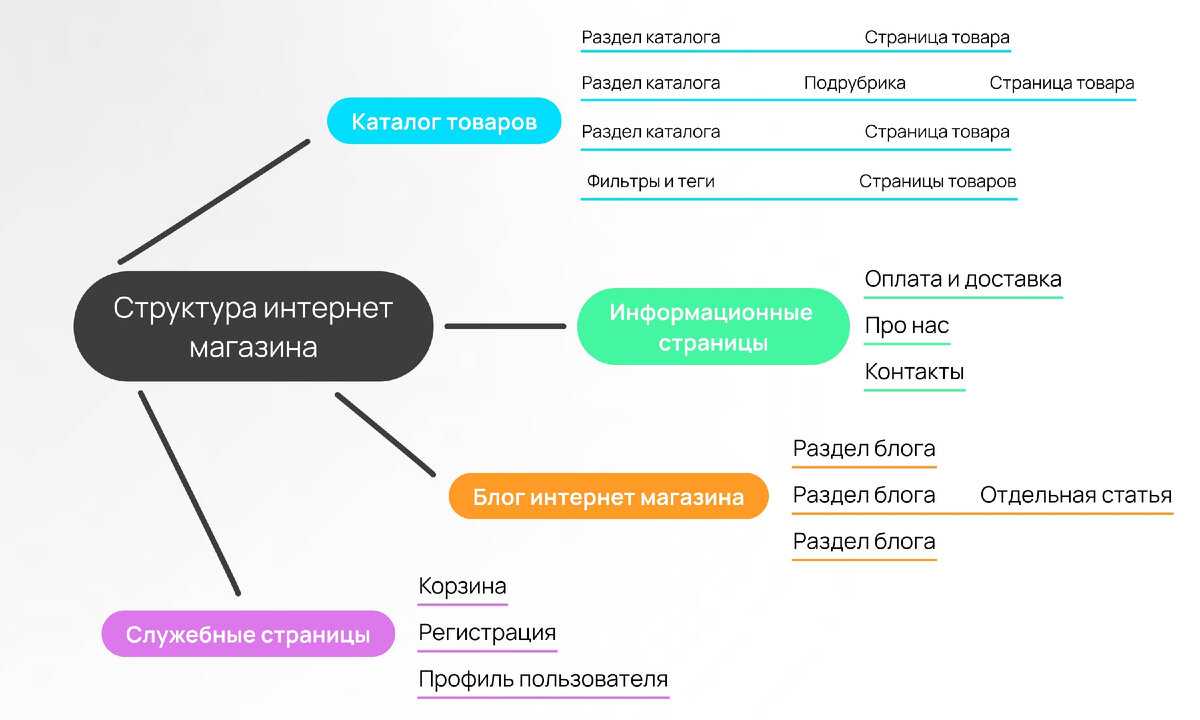
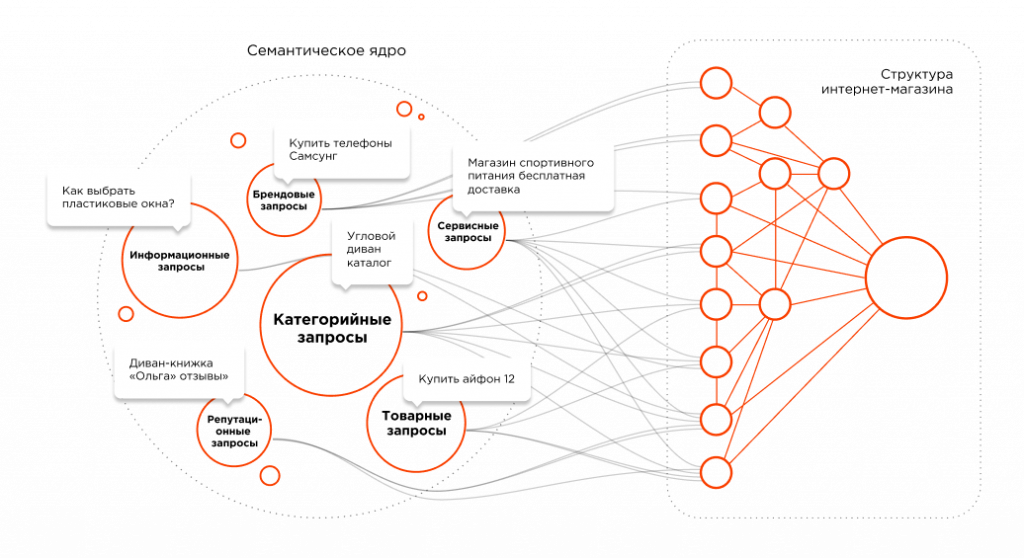
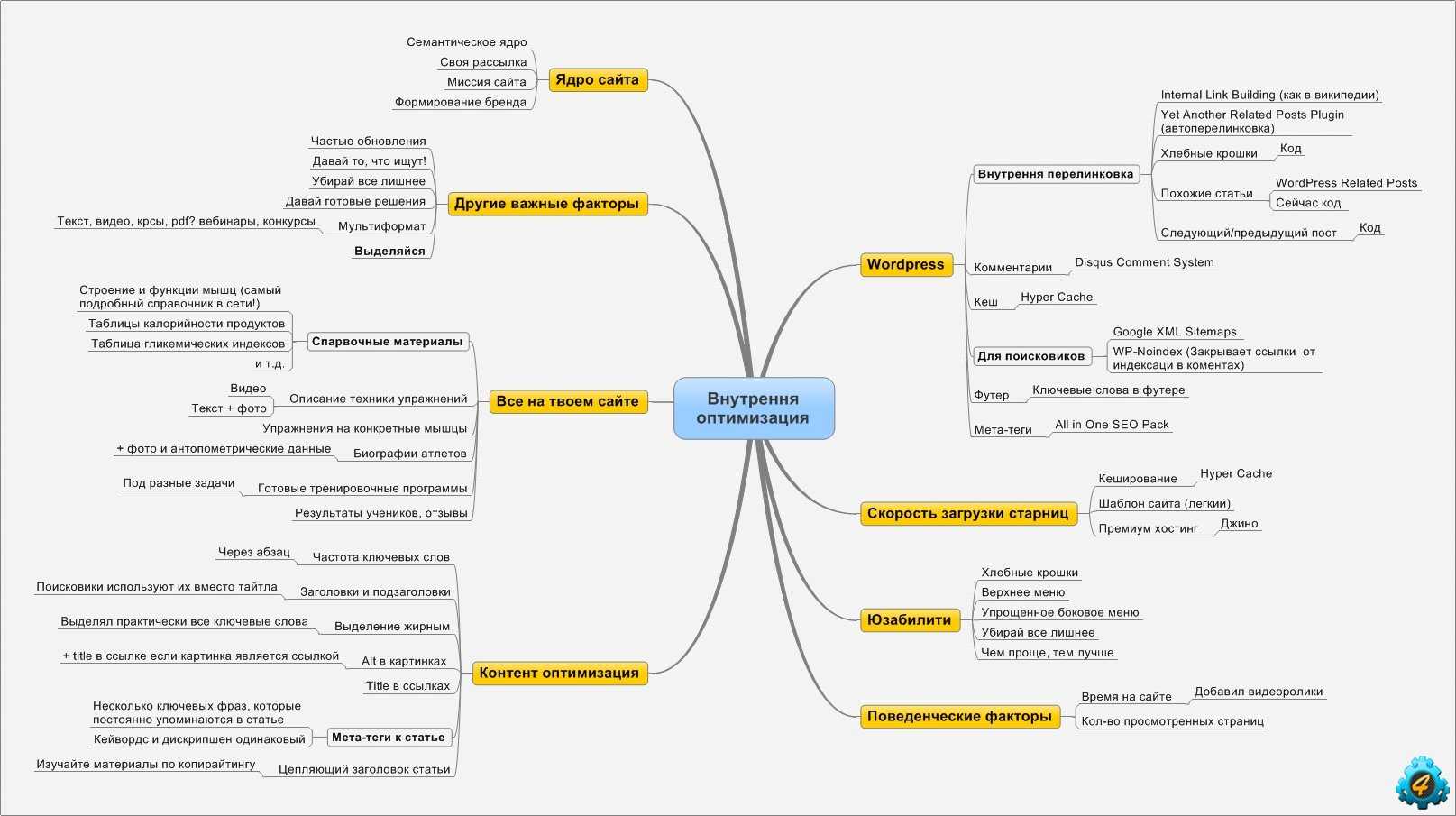


Как Google находит релевантные страницы
Давайте теперь определим, по каким принципам работает семантический поиск.
Анализ слов и выражений
Данный принцип определяет намерение пользователя. Чтобы подобрать страницы по поисковому запросу, Google создал специальные языковые модели, которые понимают правильное значение слов. Даже если вы ввели запрос с ошибкой, алгоритм все равно сможет определить верное значение, подобрать синонимы и понять разговорную речь.
Синонимы
Благодаря умной системе синонимов, в выдаче появляются более релевантные сайты, даже если в их заголовках и описаниях отсутствует точная поисковая фраза.

На скриншоте видно, что по введенной фразе «как дешево путешествовать» поисковая система поняла, что мы ищем разные варианты бюджетных путешествий и способов экономии в поездках. В выдаче мы видим разные статьи и видеолайфхаки о том, как сэкономить на перелетах, отелях, питании и прочем.
Подбор подходящих страниц
Следующий этап — оценить качество сканируемых страниц и определить, насколько их контент соответствует запросу пользователя.
Прежде всего алгоритм анализирует ключевые слова: встречаются ли они на самой странице, в заголовках, мета-описаниях. Это базовый сигнал, который говорит о релевантности контента. Помимо него, существуют еще дополнительные критерии, например, насколько широко страница раскрывает тему. Вряд ли кому-то будет интересно сотню раз видеть одни и те же ключевые слова в статье. Для этого программа должна убедиться, что страница содержит полезную информацию по запросу, а не просто дублирует текст. Также учитывается внутренняя перелинковка, наличие обратных ссылок из авторитетных источников и сигналы о взаимодействии пользователей с результатом поиска.
Диксон Джонс, международный SEO-спикер и консультант по диджитал-маркетингу считает, что сам по себе объем текста не играет ключевой роли в продвижении страницы.
В семантическом SEO большую роль играет качество и актуальность текста, а также умение доказать поисковым роботам, что ваша страница будет релевантна поисковому запросу. С одной стороны длинная статья может глубже раскрывать тему, а с другой — затронуть лишние вопросы, что усложнит задачу попадания на первую страницу в выдаче по узкому запросу. Поэтому размер имеет значение в том случае, если в тексте есть только нужная информация.
В релевантности контента большую роль играют LSI-фразы (латентно-семантическое индексирование). Проще говоря, это слова, которые семантически связаны с основным ключевым словом и дополняют основную тему.
Давайте вернемся к нашему примеру про бюджетные путешествия.
Существуют сотни, если не тысячи, страниц на тему дешевых путешествий. Но далеко не все из них содержат подходящий контент. Например, если Google видит, что ключевая фраза «как дешево путешествовать» повторяется в тексте много раз, скорее всего эта страница не займет достойное место в результатах поиска. С другой стороны, когда вы используете LSI-фразы (например, «бюджетный», «скидки», «экономия» и т. д.), для поисковой системы это будет дополнительным фактором того, что данная страница действительно раскрывает тему бюджетных путешествий.
Также помните, что «чем больше, тем лучше» в данном случае не работает. В некоторых случаях чрезмерное количество LSI-фраз на странице может привести к ручным санкциям.
Крейг Кэмпбелл, SEO-эксперт из Глазго, рекомендует использовать ключевые слова только там, где это уместно и в умеренных количествах.
Использование большего количества LSI-фраз увеличит общее количество ключевых слов, что может привлечь больше трафика
Но важно не переусердствовать и не добавлять их в каждом предложении «для галочки». Если эти слова естественно смотрятся в предложении и полезны для читателей, почему бы и нет
Главное, соблюдайте баланс.
Задача поисковых роботов состоит не только в том, чтобы сопоставлять ключевые слова и LSI-фразы с запросом. Алгоритм также оценивает надежность источников. PageRank — это один из алгоритмов ссылочного ранжирования, разработанный Google
Он определяет важность и авторитетность страницы на основе количества и качества ссылок, которые ведут на ту или иную страницу.
Разбор примера
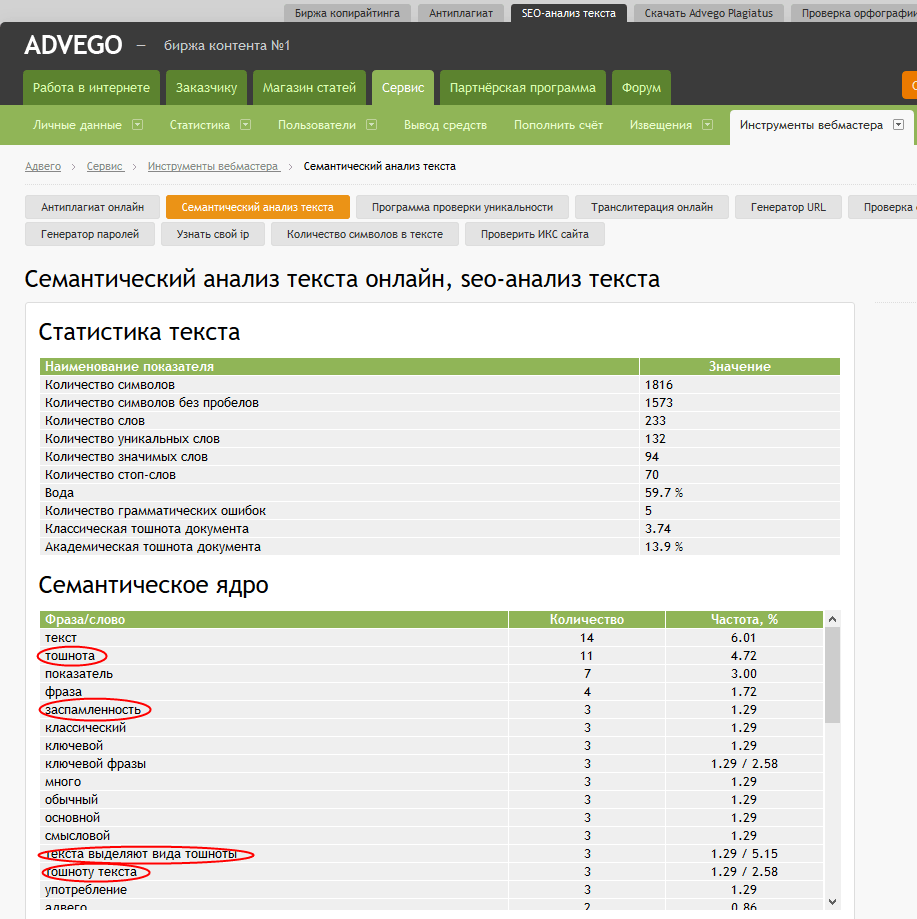
На скриншотах — пример SEO-анализа моего текста в сервисе Адвего. На первых трех картинках — данные с нормальными показателями классической и академической тошноты. Количество повторений слов и стоп-слов — небольшое.
1.1
1.2
А теперь посмотрите на следующие три скриншота. Здесь результаты с процентом классической тошноты чуть больше, чем в предыдущем примере
Обратите внимание, как сразу подскочило количество повторяющихся слов и стоп-слов
2.1
2.2
Из этих примеров следует: чтобы показатели были в норме, необходимо иметь богатый словарный запас и лаконично, без лишних слов, излагать мысли.
Есть мнение, что слишком сухой текст неинтересно читать. Поспорю с этим мнением, поскольку мой опыт показывает:
- люди читают статьи не ради развлечения, а чтобы получить конкретную информацию. Чем меньше словесного мусора, тем больше доверия вызывает сайт
- при переизбытке информации в интернете и дефиците времени лаконичность – большой плюс.
Что стоит запомнить
Когда вы создаете и оптимизируете контент — в первую очередь думайте о его важности и пользе для читателей, а не о ключевых словах. Даже высокий рейтинг не поможет странице выйти в ТОП, если она не соответствует запросу пользователей и плохо раскрывает тему
Учитывайте принципы семантического поиска и создавайте полезный и разнообразный контент, который добавит ценности вашему сайту и, безусловно, положительно отразится на позициях.
693 views
Автор статьи
Мария Ефименко
Мария – копирайтер и редактор блога SE Ranking. Большую часть своей карьеры она занимается контент маркетингом и написанием статей для блогов. Имея достаточно разносторонний опыт, она успела поработать в разных нишах, включая SEO, блокчейн, финтех, и технологических стартапах.
Семантический анализ текста: параметры анализа
Семантический анализ текста – один из ключевых инструментов поисковой оптимизации (SEO). Этот процесс позволяет понять смысл и значение текстового контента, определить его релевантность и степень соответствия запросам пользователей. Важным этапом семантического анализа является определение параметров анализа, которые помогают более точно определить ключевые слова и фразы, а также контекстуальные связи между ними.
Параметры анализа включают в себя различные критерии и показатели, которые помогают оценить семантику текста. Ниже мы рассмотрим некоторые из них:
1. Частотность ключевых слов
Один из основных параметров, влияющих на семантический анализ текста, – это частотность использования ключевых слов. Частотность можно определить как количество повторений ключевого слова или фразы в тексте. Более высокая частотность указывает на большую связь между ключевыми словами и темой текста, что положительно сказывается на релевантности и, соответственно, на позициях в поисковой выдаче.
2. Взаимосвязь между ключевыми словами
Другим важным параметром семантического анализа является взаимосвязь между ключевыми словами в тексте. Для этого используются алгоритмы и методы, позволяющие определить контекстуальные связи между словами и выявить наиболее релевантные ключевые фразы. Знание контекстуальных связей позволяет оптимизатору использовать более точные ключевые слова и фразы в тексте, увеличивая его семантическую ценность.
3. Анализ семантического ядра
Анализ семантического ядра – это процесс определения наиболее значимых и релевантных ключевых слов для конкретного текста. Семантическое ядро представляет собой группу ключевых слов и фраз, связанных с темой статьи или страницы. При анализе семантического ядра учитывается как частотность и взаимосвязь ключевых слов, так и их релевантность для целевой аудитории. Подробное изучение семантического ядра позволяет оптимизировать текст с учетом наиболее важных ключевых слов и фраз.
4. Определение поисковых запросов пользователей
Для более точного семантического анализа текста необходимо учитывать поисковые запросы, которые пользователи используют при поиске информации. Анализ запросов позволяет определить, какие ключевые слова и фразы актуальны для целевой аудитории. Исходя из этих запросов, можно провести анализ семантического ядра и оптимизировать контент для максимальной релевантности запросам пользователей.
5. Оптимизация контента
Когда необходимые параметры семантического анализа определены, можно приступить к оптимизации текстового контента. Оптимизация включает в себя правильное распределение ключевых слов и фраз в тексте, создание уникального и ценного контента для пользователей, а также учет требований поисковых систем к структуре текста (например, использование внутренних ссылок, метатегов и заголовков).
Семантический анализ текста является важной составляющей SEO-оптимизации. Этот процесс позволяет более точно определить ключевые слова и фразы, а также контекстуальные связи между ними
Правильное проведение семантического анализа позволяет улучшить релевантность и позиции контента в поисковых системах, а это в свою очередь приводит к привлечению более целевой аудитории и повышению общей эффективности веб-сайта.
| Параметр анализа | Описание |
|---|---|
| Ключевые слова | Ключевые слова — это слова или фразы, которые наиболее полно описывают содержание текста или его тематику. Они играют важную роль в семантическом анализе текста, помогая определить смысл и контекст, а также оптимизировать процессы поиска и классификации. |
| Тональность | Тональность текста — это эмоциональная окраска выраженных в тексте мыслей или сообщений. Определение тональности помогает понять, является ли текст позитивным, негативным или нейтральным. Это полезная информация, которая может быть использована для анализа мнений, оценки общественного мнения или определения эмоциональной реакции аудитории на определенное событие или продукт. |
| Сущности | Сущности — это именованные сущности или объекты, которые могут быть определены в тексте. Они могут быть людьми, местами, организациями, датами, суммами денег и другими элементами, имеющими особую значимость в контексте текста. Определение и классификация сущностей помогает структурировать информацию и извлекать полезные данные, такие как имена, даты, адреса и другие важные детали. |
TF-IDF и закон Ципфа
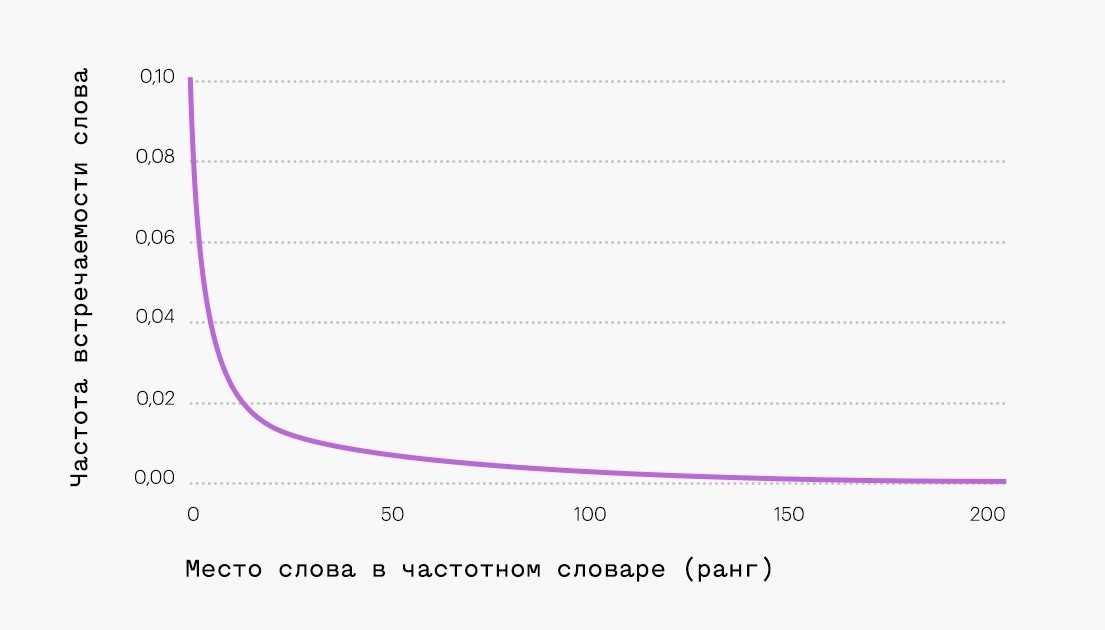
Проверка по закону Ципфа – это метод распределения частоты слов естественного языка: если все слова языка (или просто достаточно длинного текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (так называемому рангу этого слова). Например, второе по используемости слово встречается примерно в два раза реже, чем первое, третье – в три раза реже, чем первое, и так далее. Наиболее часто используемые 18% слов (приблизительно) составляют более 80% объема всего текста.






Самые популярные слова будут отображаться в большинстве документов. В результате такие слова усложняют подбор текстов, представленных с помощью модели мешка слов. Кроме того, самые популярные слова часто являются функциональными словами без смыслового значения. Они не несут в себе смысл текста.
10 самых популярных слов в русском языке:
1. и
2. в
3. не
4. на
5. я
6. быть
7. он
8. с
9. что
10. а
Мы можем применить статистическую меру TF-IDF (частота слова – обратная частота документа), чтобы уменьшить вес слов, которые часто используются в тексте и не несут в себе смысловой нагрузки. Показатель TF-IDF рассчитывается по следующей формуле:

- tfi,j– частота слова в тексте,
- dfj– количество документов, содержащих текст с данным словом,
- N – общее количество документов.
В таблице ниже приведены значения IDF для некоторых слов в пьесах Шекспира, начиная от самых информативных слов, которые встречаются только в одной пьесе (например, «Ромео»), до тех, которые настолько распространены, что они полностью не дискриминационные, поскольку встречаются во всех 37 пьесах. Такие как «хороший» или «сладкий».
IDF самых распространенных слов равен 0, в результате их частоты в модели мешка слов также будут равны 0. Частоты редких слов будут наоборот увеличены.
|
Слово |
DF |
IDF |
|
Ромео |
1 |
1,57 |
|
салат |
2 |
1,27 |
|
Фальстаф |
4 |
0,967 |
|
лес |
12 |
0,489 |
|
боевой |
21 |
0,074 |
|
дурачить |
36 |
0,012 |
|
хорошо |
37 |
|
|
милая |
37 |
Что такое ключевой запрос
Прежде чем говорить о том, что такое семантика, стоит определиться с таким понятием, как ключевые запросы.
Примеры ключевых запросов
Когда вы ищете какую-либо информацию в интернете, то вводите в поисковую строку определенные слова и словосочетания, связанные с интересующим вас предметом. А поисковый робот выдает список веб-страниц, которые содержат нужную вам информацию.
К примеру, для того, чтобы найти ресурс, где рассказывается о том, что такое семантика, вы использовали примерно следующее: «семантика что это для сайта», «что такое семантика», «семантика простыми словами», «что такое семантическое ядро», «семантическое ядро что это». Такие сочетания слов называются ключевыми фразами (запросами, ключами). Множество таких словосочетаний, сгруппированных по конкретным темам, и представляет собой семантическое ядро (СЯ).
Ключевой запрос (ключевая фраза, ключ, ключевик) – это слова и словосочетания, которые пользователи добавляют в строку поиска, когда хотят найти какую-то информацию в интернете. Ключи — главный инструмент SEO-продвижения (поисковой оптимизации). Именно ключевые запросы помогают сайтам продвигаться на первые позиции в поисковой выдаче.
Если при написании статей грамотно используются ключи, релевантные поисковым запросам, площадка с таким контентом имеет все шансы занять топовые места в поиске и опередить конкурентов.
Релевантность в сфере поисковой оптимизации – это степень соответствия контента нуждам пользователей.
Виды ключевых запросов
Условно ключевые запросы подразделяются на несколько групп, при этом запросы разного вида могут пересекаться.
По популярности
В разных по популярности тематиках показатели частотности будут отличаться.
- ВЧ (высокочастотные) – более 1000–5000 показов в месяц.
- СЧ (среднечастотные) – от 100–1000 показов в месяц.
- НЧ (низкочастотные) – 100–1000 показов в месяц.
- МНЧ (микронизкочастотные) – менее 100 показов в месяц.
Если ниша узкая, частотность понижается.
При создании нового ресурса лучше ориентироваться на низко- и микронизкочастотные ключевые фразы. По статистике, от 60 до 80% пользователей приходят на сайт именно по ним. Поэтому желательно собрать максимум ключей – в СЯ лучше включить все запросы, даже те, частотность которых ниже 10. Еще один важный момент: использование широкого диапазона НЧ и МНЧ может помочь вывести сайт в топ по запросам средне- и высокочастотным.




По геозависимости
- Геозависимые – результат выдачи зависит от региона, где находится пользователь. Например: доставка суши, заказать такси, записаться на маникюр, где отремонтировать стиральную машину.
- Геонезависимые – запрос не привязан к региону. Например: как утеплить окна, когда лучше сажать чеснок, как избавиться от тараканов, преимущества удаленной работы.
По сезону
- Сезонные – те, которые наиболее актуальны в определенный сезон или перед каким-то мероприятием, событием. Примеры: летняя распродажа в италии 2020, как высадить рассаду в теплицу, когда пасха в 2020, как украсить квартиру на новый год. Некоторые специалисты в отдельную группу выделяют событийные запросы – такие, частотность которых возрастает в период проведения спортивных, культурных мероприятий, политических и других событий. Например: собор парижской богоматери пожар, грета тунберг в оон, состав сборной англии по футболу 2019.
- Несезонные – их частотность на протяжении года меняется незначительно. Например: как приготовить плов, как настроить вордпресс, почему нужно знать иностранные языки. По таким запросам сезонных всплесков практически не бывает.
Искусственная семантика
Искусственная семантика – это группа поисковых ключевых слов и фраз для создания контента, то есть создание семантического ядра, которое может привлечь внимание к контенту или поднять посещаемость веб-ресурса и т. д. В основном искусственная семантика или семантика текста используется для создания контента, рекламы
В основном искусственная семантика или семантика текста используется для создания контента, рекламы.
Семантика онлайн
В информатике термин семантика относится к смыслу языковых конструкций, в отличие от их формы (синтаксиса). Она предоставляет правила для интерпретации синтаксиса, который не даёт значения напрямую, но сдерживает возможные интерпретации того, что объявлено. В технологии онтологии этот термин относится к смыслу понятий, свойств и отношений, которые формально представляют объекты, события и сцены реального мира в логическом подходе, такие как логика описания обычно реализуемая в интернете.
Значение концепций логики описания и ролей определяется их теоретико-модельной семантикой, основанной на интерпретациях. Понятия, свойства и отношения, определённые в онтологиях, могут быть развёрнуты непосредственно в разметке веб-сайта, в базах данных графов в виде триггеров
Семантика языков программирования и других языков является важной проблемой и областью изучения информатики. Разработаны различные способы описания языков программирования формально, основываясь на математической логике
Семантические модели
Семантика онлайн относится к расширению Всемирной паутины посредством внедрения добавленных метаданных с использованием методов моделирования семантических данных. В семантической сети такие термины, как семантическая сеть и модель семантических данных, используются для описания конкретных типов модели данных, характеризующихся использованием ориентированных графов, в которых вершины обозначают понятия или сущности мира и их свойства, а дуги обозначают отношения между ними.
В сети, анализ слова, структуры ссылок и декомпозиции сети немногочисленны и включают часть, вид и подобные ссылки. В автоматизированных онтологиях ссылки вычисляются векторами без явного значения. Разрабатываются различные автоматизированные технологии для вычисления значения слов: латентные семантические индексирование и векторные машины поддержки, а также обработка естественного языка, нейронные сети и методы исчисления предикатов.
Подсчет количества символов в тексте онлайн, посчитать знаки и слова, SEO-анализ текста
Описание сервиса
SEO-анализ текста от Text.ru — это уникальный сервис, не имеющий аналогов. Возможность подсветки «воды», заспамленности и ключей в тексте позволяет сделать анализ текста интерактивным и легким для восприятия.
SEO-анализ текста включает в себя:
Счетчик символов, подсчет количества знаков и слов в тексте онлайн
С помощью данного онлайн-сервиса можно определить число слов в тексте, а также количество символов с пробелами и без них.
Определение ключей и семантического ядра текста
Возможность нахождения поисковых ключей в тексте и определения их количества полезна как для написания нового текста, так и для оптимизации уже существующего. Расположение ключевых слов по группам и по частоте сделает навигацию по ключам удобной и быстрой. Сервис также найдет и морфологические варианты ключей, которые выделятся в тексте при нажатии на нужное ключевое слово.
Определение процента водности текста
Данный параметр отображает процент наличия в тексте стоп-слов, фразеологизмов, а также словесных оборотов, фраз, соединительных слов, являющихся не значимыми и не несущими смысловой нагрузки. Небольшое содержание «воды» в тексте является естественным показателем, при этом:
- до 15% — естественное содержание «воды» в тексте;
- от 15% до 30% — превышенное содержание «воды» в тексте;
- от 30% — высокое содержание «воды» в тексте.
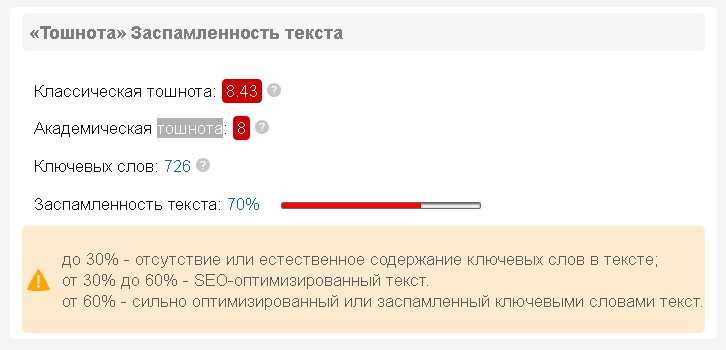
Определение процента заспамленности текста
Процент заспамленности текста отражает количество поисковых ключевых слов в тексте. Чем больше в тексте ключевых слов, тем выше его заспамленность:
- до 30% — отсутствие или естественное содержание ключевых слов в тексте;
- от 30% до 60% — SEO-оптимизированный текст. В большинстве случаев поисковые системы считают данный текст релевантным ключевым словам, которые указаны в тексте.
- от 60% — сильно оптимизированный или заспамленный ключевыми словами текст.
Поиск смешанных слов или слов в различных раскладках клавиатуры
Данный параметр показывает количество слов, состоящих из букв различных алфавитов. Часто это буквы русского и английского языка, например, слово «стол», где «о» — буква английского алфавита. Некоторые копирайтеры заменяют в русских словах часть букв на английские, чтобы обманным путем повысить уникальность текста. SEO-анализ текста от Text.ru успешно выявляет такие слова.
SEO-анализ текста доступен через API. Подробнее в API-проверке.