
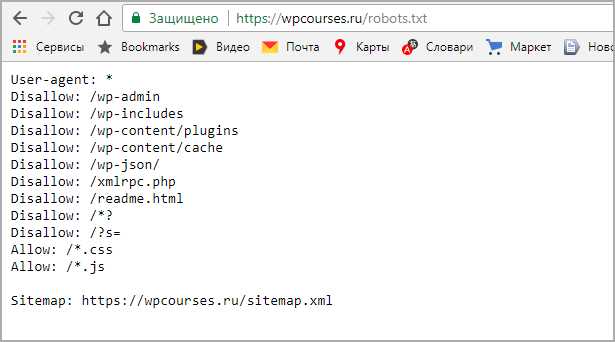
Популярные ошибки
Существует множество мелких и досадных ошибок, из-за которых можно потерять кучу времени и сил.
-
Запрет индексации в CMS.
У ряда CMS (к примеру, у WordPress) и шаблонов по умолчанию стоит галочка — «не индексировать сайт». Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания.
К сожалению, не все вспоминают о ней по окончании работ.
-
Синтаксические ошибки.
Синтаксические ошибки в файле robots.txt и тэгах часто приводят к совершенно непредсказуемым последствиям. Вам повезет, если после такого недочета в индекс просто попадут лишние страницы. Очень часто весь сайт закрывается, что в последствии приводит к полной потере органического трафика.
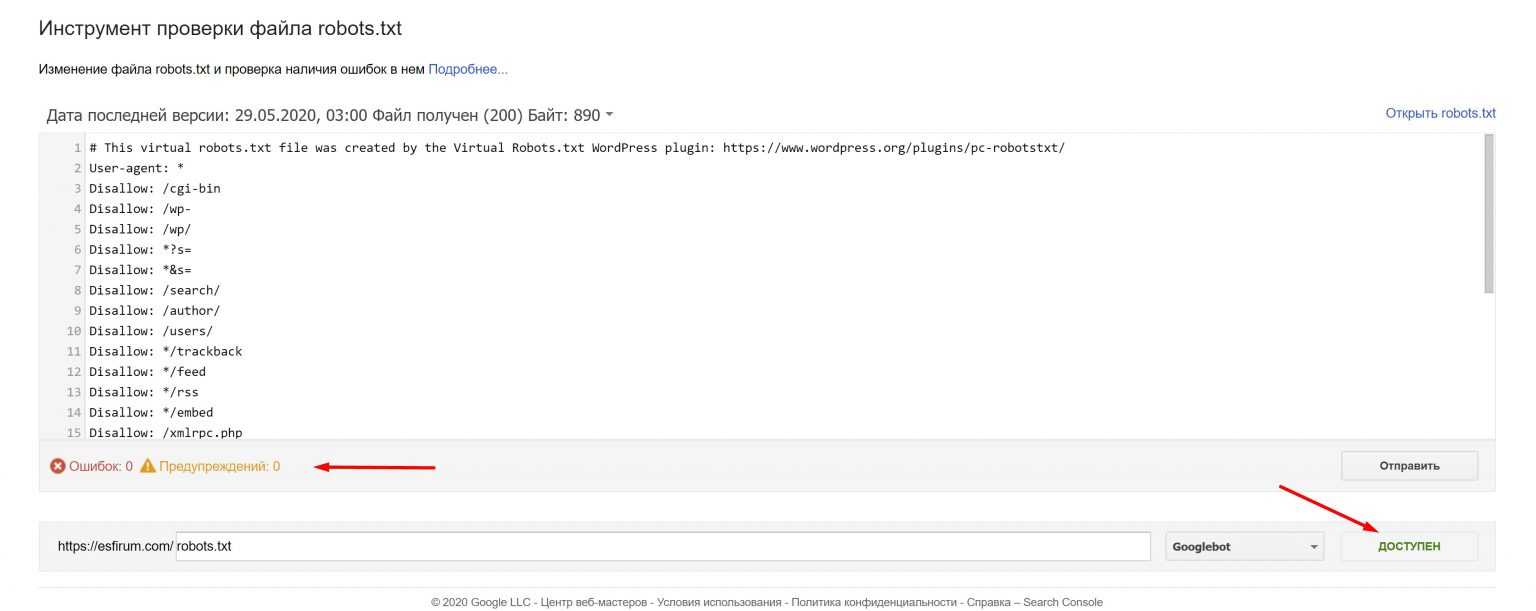
Для того, что бы избежать подобных ошибок, необходимо несколько раз перепроверить изменения, а так же воспользоваться инструментами валидации синтаксиса. К примеру, стандартным сервисом Яндекса.
Яндекс Вебмастер -> Инструменты -> Анализ robots.txt
-
Неверное использование масок.
Неверное использование масок может привести к исключению целого дерева страниц, документов и разделов. Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых
систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.

Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы
находитесь в стадии разработки (или доработки) ресурса. В таком случае его
лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в
индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной
готовности и наполненности контентом.

Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.

Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.

Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.

Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
Разберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам Блок с Disallow запрещает к индексу все технические страницы и дубли
обратите внимание что я заблокировал папки начинающиеся на wp- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен». Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress
Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
 Адрес в строке запроса
Адрес в строке запроса
Robots.txt в Яндекс и Google
У большинства оптимизаторов, которые первый раз сталкиваются с файлом robots.txt возникает вполне закономерный вопрос: «Почему нельзя указать User-agent: * и не прописывать для каждого робота одинаковые правила?». Конечно, так сделать можно, но возникает неопределенность. Во-первых, только Яндекс поддерживает директиву Host, которая указывает на главное зеркало сайта. Использование данной директивы для всех роботов бессмысленно (УСТАРЕЛО — https://yandex.ru/blog/platon/pereezd-sayta-posle-otkaza-ot-direktivy-host). Во-вторых, существует субъективное мнение, что поисковые системы Яндекс и Google приветствуют указание именно их робота в User-agent, а не использование директивы общего плана.
Кроме того, допустимый размер файла в 32 кб позволяет практически каждому сайту уместить необходимые для индексирования директивы в отдельных User-agent для разных поисковых систем. Нет смысла экспериментировать со своим сайтом, если можно прописать для каждого поискового робота персональные директивы, уложившись в ограниченный лимит. К слову, редко, но все же случаются такие ситуации, когда оптимизаторы хотят закрыть определенные страницы для одной поисковой системы, при этом оставить их доступными для другой. В этом случае без директивы User-agent просто не обойтись.
Настройка файлов .htaccess: основные тезисы и правила
1. Названия файлов .htaccess всегда идентичны и начинаются с точки.
2. Действие правил (команд) .htaccess распространяется на директорию/каталог, в которую помещен файл, а также на вложенные папки и файлы.
3. На одном сайте может быть сколько угодно .htaccess, разнесенных по файловой структуре сайта. Но в одной директории/папке хостинга используется только 1 файл с командами.
4. Чтобы настройки файла распространялись на весь сайт, вложенные папки и файлы, необходимо поместить .htaccess в корневую директорию (верхнюю папку вашего сайта, главную директорию домена в файловом менеджере хостинга).
5. Файл .htaccess содержит пользовательские настройки, действующие только для веб-серверов Apache. С помощью этого файла настраиваются редиректы, серверные параметры и зеркала сайта, страницы авторизации и ошибок, кеширование и сжатие, особенности индексации поисковыми роботами и пр.
Перед настройкой директив убедитесь, что работа файла поддерживается на вашем хостинге/сервере с системой Apache!
Изменения .htaccess действуют только локально и не затрагивают конфигурационного файла веб-сервера.
6. Файлы .htaccess можно создавать и редактировать самостоятельно в стандартном «Блокноте» Windows, но лучше использовать специализированные программы вроде Notepad++. При сохранении кодировки UTF-8 в файле не должно быть BOM-сигнаруты, и поэтому применяется Notepad++.
Не пугайтесь сложной терминологии. Просто запомните, что для создания и редактирования .htaccess нужно использовать бесплатную программу Notepad++ (скачайте ее из интернета).
7. Если после создания, правки, размещения файла на сайте возникает ошибка 500, что-то не так с настройками .htaccess. Устраните ошибки, иначе сайт не сможет нормально работать.
8. Защитить содержимое файла от посторонних вмешательств можно через настройки прав доступа. Зайдите в файловый менеджер хостинга или по FTP, отыщите настройки прав доступа нужного файла .htaccess и установите атрибут «444» (только чтение для всех без исключения).
Но для внесения правок вам придется сменить атрибуты на «644» (администратор – возможность правки, все другие – только чтение). Права «444» полностью закрывают файл от несанкционированного редактирования или взлома.
9. Для каждого движка директивы и количество файлов .htaccess будет разным. Читайте документацию своей CMS.
10. По запросам «проверка .htaccess онлайн» и «генератор .htaccess онлайн» найдете в Яндексе/Google соответствующие сервисы проверки и генерации, работающие в реалтайме.
11. Отыскать настройки .htaccess для решения конкретных задач можно в любой поисковой системе.
12. После внесения изменений в файл обязательно сохранить результат, иначе настройки аннулируются.
13. При просмотре корневой структуры сайта по FTP вы можете не увидеть .htaccess, т.к. он скрыт. Зайдите в настройки FTP-клиента и активируйте показ скрытых файлов.
14. В корневом документе .htaccess настраиваются редиректы 301, а также страницы ошибок 401, 403, 404, 500.
При переезде на защищенный протокол HTTPS, смене домена, удалении страниц и изменении URL-структуры, вам также придется корректировать редиректы в «аштиакцесс».
15. После окончательной настройки сайта советуем скачать и сохранить корневой конфигурационный .htaccess на компьютере. Резервная копия (а лучше – полный архив файловой структуры вашего сайта) поможет восстановить веб-ресурс в случае краха или ошибок.
Большинство вирусов и мошенников вносят правки именно в корневом файле .haccess, и при возникновении проблем загляните сюда в первую очередь.
Разрешить индексацию robots.txt — Allow
Allow — это директива разрешающая поисковому роботу обход страниц. Она является противоположностью директиве Disallow. В ней, как и в Disallow возможно использование спецсимволов * и $.
Давайте рассмотрим пример использования директивы Allow:
User-agent: * Disallow: / Allow: /blog
Данные инструкции разрешают обход раздела /blog, при этом весь остальной сайт остается недоступен для индексирования.
Пустой «Disallow: » = «Allow: /». Обе директивы разрешают полный обход сайтаПустой «Allow: » = «Disallow: /». Обе директивы полностью запрещают обход сайта.
Эта информация дана для справки. Широкого практического применения она не получает.
Как закрыть сайт от бота Google
Заблокировать поисковым роботам Google доступ к сайту можно также через robots.txt, HTML-разметку или указать инструкцию для Googlebot в HTTP-заголовке.
Как заблокировать доступ робота к странице через robots.txt
Основным поисковым роботом Google является Googlebot. Его задача – индексировать страницы и проверять их на адаптивность под мобильные устройства. Но также у Google есть десяток других ботов, каждый из которых выполняют свою задачу. Например, Googlebot-News сканирует страницу с новостями и добавляет их в Google Новости, Googlebot-Video индексирует видеоконтент на страницах сайта, а Googlebot-Image – изображения.
Управление индексированием сайта или отдельных его страниц для Googlebot в файле robots.txt происходит с помощью той же директивы Disallow, что и для поискового робота Яндекса.
То есть, для того чтобы закрыть обход всего сайта для бота Google, в файле укажите:
- User-agent: Googlebot
- Disallow: /
Если вам надо закрыть обход определенной страницы, пропишите такую директиву:
- User-agent: Googlebot
- Disallow: / page
Для закрытия обхода раздела прописывается директива:
- User-agent: Googlebot
- Disallow: / catalogue
Для закрытия раздела с новостями от индекса поисковым роботом Googlebot-News пропишите директиву:
- User-agent: Googlebot-News
- Disallow: / news
Если нужно закрыть сайт полностью от поисковых роботов Яндекса и Google, не обязательно прописывать для них разные директивы. Это можно сделать одной командой.








- User-agent: *
- Disallow: /
В первой строке вместо имени агента ставится знак «*».
Как запретить индексирование содержимого страницы через HTML-разметку
С помощью HTML-разметки можно закрыть от индексации роботом Google целую страницу или определенную ее часть. Для этого пропишите метатег «googlebot» с директивой noindex или none.
Для того чтобы ограничить боту Google доступ к странице вашего сайта, на HTML-странице вы можете прописать такие команды:
1. Если хотите скрыть определенный контент на странице и предупредить его появление на поиске и в Google News, пропишите команду:
2. Если хотите запретить индексирование определенных изображений на странице, пропишите команду:
3. Если на сайте очень быстро устаревает актуальность контента, например, у вас новостной портал, или вы проводите акции и не хотите, чтобы в индекс попадали страницы с неактуальной информацией, пропишите команду, когда страница должна быть удалена из индекса Google.
Например, вы разместили на сайте новость о проведении Черной пятницы. Срок окончания акции – 29 ноября. Команда будет выглядеть так:
Что касается индексирования ссылок, в Google есть два дополнительных параметра, которые указывают поисковику на происхождение линков:
- rel=»ugc» – используется в том случае, если у вас на ресурсе есть форум, где пользователи делятся отзывами и оставляют свои ссылки. В качестве таких ссылок сложно быть уверенным, и этот атрибут помогает роботу понять, откуда взялась ссылка.
- rel=»sponsored» – используется в том случае, если на сайте размещена рекламная ссылка, которая указывает на размещение в рамках партнерской программы.
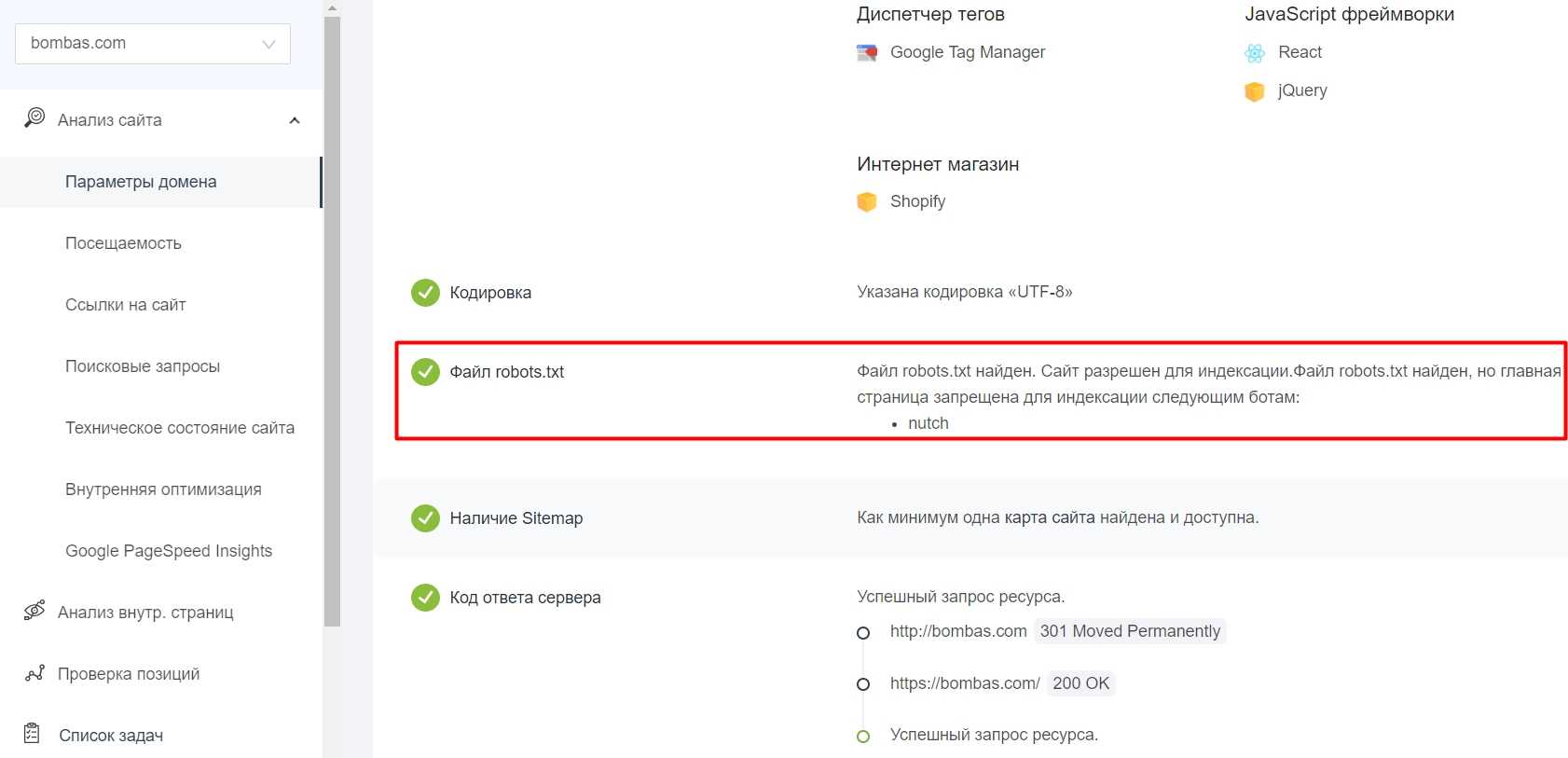
Как проверить статус страницы в Google Search Console
В Google Search Console также предусмотрена возможность проверки статуса страницы. Для этого в боковой панели выберите раздел «Инструмент проверки URL», введите нужный адрес и кликните на «Изучить просканированную страницу».
Если страница исключена из индексирования, в отчете будет сообщение о том, что URL нет в индексе Google.
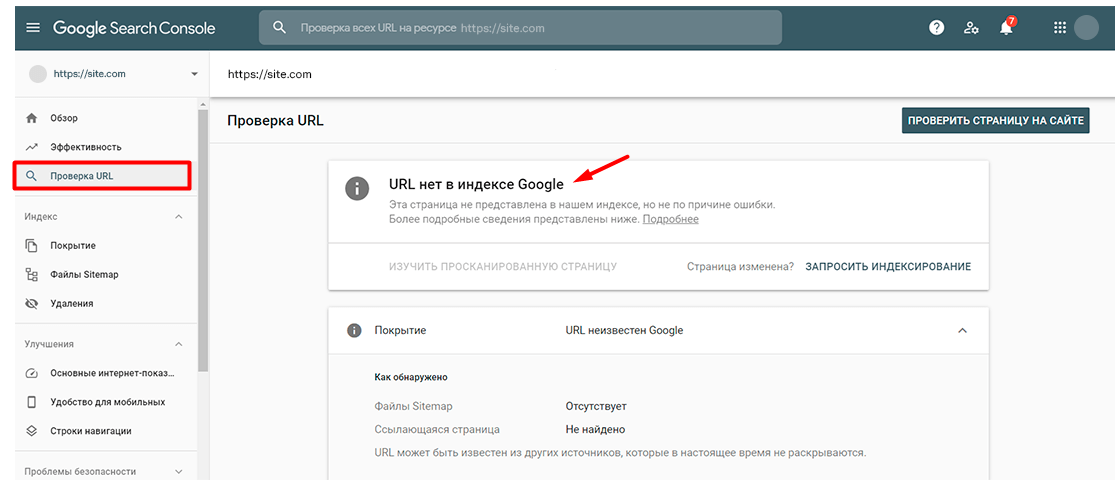
В Google Search Console также можно проверить все страницы сайта. Для этого перейдите в раздел «Статус индексирования» и сформируйте отчет с результатами сканирования. В отчете будут представлены результаты сканирования, сгруппированные по статусу (ошибка, предупреждение, без ошибок) и причине (код ответа HTTP).
Кроме Google Search Console и Яндекс Вебмастера существуют и другие инструменты и онлайн-сервисы, позволяющие проверить статус страниц сайта. Например, в PromoPult есть «Анализ индексации страниц», который быстро проверит индексацию всего сайта или отдельных страниц в Яндексе и Google. Нужно только загрузить XML-карту, XLSX-файл со списком URL или ввести нужные адреса страниц вручную. Подробная инструкция по работе с инструментом – здесь.
robots.txt в WordPress
Build In Post
ВАЖНО чтобы в корне вашего сайта НЕ было файла robots.txt! Если он там есть, то все описанное ниже просто не будет работать, потому что ваш сервер будет отдавать контент этого статического файла. В WordPress запрос обрабатывается нестандартно
Для него «налету» создается контент файла robots.txt (через PHP)
В WordPress запрос обрабатывается нестандартно. Для него «налету» создается контент файла robots.txt (через PHP).
Динамическое создание контента позволит удобно изменять его через админку, хуки или SEO плагины.
Изменить содержание robots.txt можно через:
- Хук robots_txt.
- Хук do_robotstxt.
Рассмотрим оба хука: чем они отличаются и как их использовать.
По умолчанию WP 5.5 создает следующий контент для страницы :
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: http://example.com/wp-sitemap.xml
Смотрите do_robots() — как работает динамическое создание файла robots.txt.
Этот хук позволяет дополнить уже имеющиеся данные файла robots.txt. Код можно вставить в файл темы functions.php.
// Дополним базовый robots.txt
// -1 before wp-sitemap.xml
add_action( 'robots_txt', 'wp_kama_robots_txt_append', -1 );
function wp_kama_robots_txt_append( $output ){
$str = '
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed # Все встраивания.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat
';
$str = trim( $str );
$str = preg_replace( '/^+(?!#)/mU', '', $str );
$output .= "$str\n";
return $output;
}
В результате перейдем на страницу и видим:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed # Все встраивания. Disallow: */page/ # Все виды пагинации. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat Sitemap: http://example.com/wp-sitemap.xml
Обратите внимание, что мы дополнили родные данные ВП, а не заменили их. Этот хук позволяет полностью заменить контент страницы
Этот хук позволяет полностью заменить контент страницы .
add_action( 'do_robotstxt', 'wp_kama_robots_txt' );
function wp_kama_robots_txt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "\r\n", $lines );
die; // обрываем работу PHP
}
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Последствия и риски закрытия сайта от индексации
Снижение трафика: Когда страницы сайта исключены из индекса поисковых систем, они перестают появляться в результатах поиска, что приводит к уменьшению органического трафика.
SEO: Закрытие сайта от индексации означает, что новый и обновленный контент также не будет индексироваться, что препятствует улучшению позиций сайта в поисковых системах.
Ухудшение доверия: Поисковые системы могут воспринимать сайты, закрытые от индексации, как менее доверительные или релевантные, что может отрицательно сказаться на рейтинге сайта.
Задержки в индексации: После того, как сайт вновь открыт для индексации, может пройти некоторое время, прежде чем поисковые системы полностью переиндексируют его содержимое и восстановят его видимость.
Советы по минимизации негативных последствий:
Используйте точечные методы: Вместо того чтобы закрывать весь сайт от индексации, старайтесь использовать более точечные методы, такие как метатеги noindex для отдельных страниц, которые действительно не должны индексироваться.
Ограничьте время закрытия: Если необходимо закрыть весь сайт (например, для технического обслуживания), делайте это на как можно более короткий период времени.
Информируйте пользователей: Если сайт временно закрыт от индексации, полезно сообщить об этом пользователям, используя статусные страницы или социальные сети, чтобы поддерживать вовлеченность и доверие.
Регулярно проверяйте индексацию: После того как сайт снова открыт для индексации, регулярно проверяйте его статус с помощью инструментов вебмастера, чтобы убедиться, что процесс индексации восстановлен.
SEO-оптимизация: Воспользуйтесь периодом закрытия сайта для улучшения SEO, например, оптимизируя метаданные, улучшая структуру сайта или обновляя контент. Таким образом, когда сайт вновь станет доступен для индексации, он будет лучше подготовлен к продвижению.








Соблюдение этих рекомендаций поможет минимизировать риски, связанные с закрытием сайта от индексации, и обеспечить, что ваш сайт сохранит свою видимость и эффективность в поисковых системах.
Закрытие от индексации с помощью файла Robots.txt
Самым распространенным способом указать поисковым роботам страницы, представленные или, наоборот, закрытые для посещения, является robots.txt. Это обычный текстовый файл, размещенный в корневом каталоге интернет-ресурса, в котором описаны инструкции для поисковых ботов.
Чтобы закрывать сразу весь сайт от индексации, вам понадобится прописать в файле robots.txt всего две строчки:
В данной инструкции вы сообщаете, что она распространяется на все поисковые системы (User-agent: *); вторая строка (Disallow: /) означает, что запрет касается всех страниц сайта.
В случае необходимости закрыть ресурс только от одной поисковой системы, в строке User-agent: указываем, для какой именно. Чаще всего прописывают поисковые системы Yandex или Google:
User-agent: Yandex Disallow: /
User-agent: GoogleBot Disallow: /
Строка Disallow может также содержать инструкции относительно отдельных частей, разделов или папок сайта, которые нежелательны для обхода роботов.
Для запрета индексации:
User-agent: * Disallow: файл1.htm Disallow: файл2.htm Disallow: файл3.htm
Следует учитывать, что robots.txt воспринимается поисковиками по-разному, и роботы Google не всегда следуют его указаниям, воспринимая содержимое файла как рекомендацию.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида .

WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Директива во второй строке закроет доступ по всем каталогам, начинающимся на , в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Служебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Далее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент
Такие страницы с параметрами следует запрещать аналогичным образом:
Это правило распространяется на простые постоянные ссылки , страницы с поисковыми запросами и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску , тем самым запрещая индексирование архивов по годам:
Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива — указывает на главное зеркало для Яндекса:
При работе сайта по HTTPS необходимо указать протокол:
С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
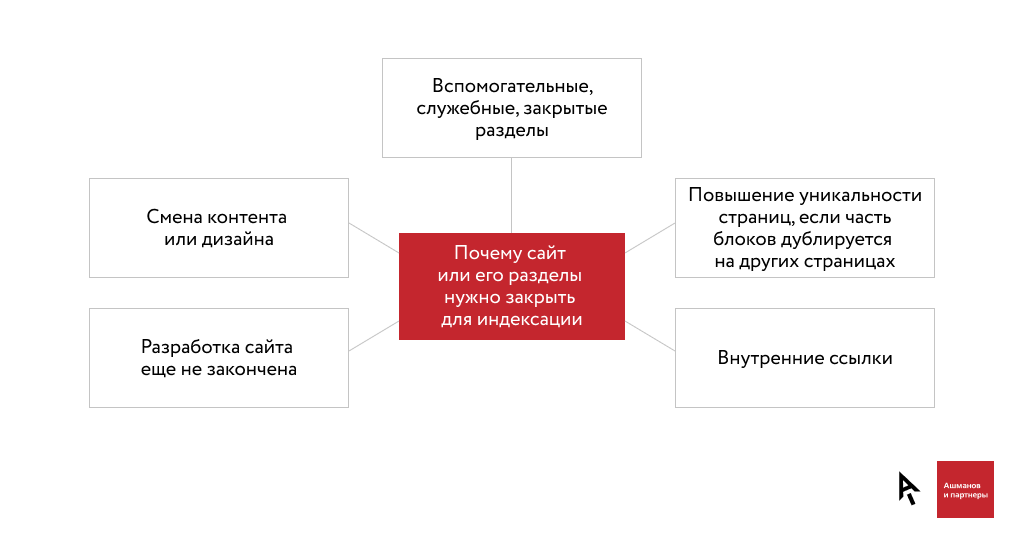
Зачем закрывать сайт или его страницы от индексации
Отображение нового сайта или только что добавленных страниц на поиске происходит не мгновенно. Причина простая – новые страницы еще не проиндексированы поисковыми роботами. Только после того как поисковые роботы проиндексировали добавленные страницы и информация о них поступила в базу данных поисковой системы, страница будет отображаться в поиске Яндекса или Google.
Пользователи видят только те страницы сайта, которые содержат полезный для них контент. Эти страницы открыты для поиска и проиндексированы. Однако каждый ресурс содержит рабочие документы и файлы, которые не несут пользы для посетителей, а нужны разработчикам, администраторам, SEO-специалистам. Сюда относятся временные файлы, рабочая документация, внутренние ссылки, страницы в разработке и другая служебная информация. Попадание таких файлов в индекс только усложнило бы поиск по сайту, сделало бы его структуру непонятной и снизило юзабилити ресурса.
Также от индекса могут закрываться сайты. Это актуально в таких ситуациях: когда разработка сайта еще не окончена, происходит смена контента или дизайна ресурса, меняется структура сайта и т. д.
Четыре причины, почему сайт лучше не индексировать полностью:
- Чтобы не потерять позиции в поисковой выдаче. Не вся информация на сайте полезна для пользователей. Если служебные файлы, страницы в разработке и прочий «мусор» попадет в поиск, бесполезный контент в выдаче приведет к понижению позиций сайта.
- Чтобы выполнить требования к уникальности контента. Поисковые системы требуют, чтобы на ресурсах был уникальный контент. Поэтому если вы, например, тестируете сайт на другом домене, его нужно закрыть от индексации. В противном случае бот воспримет такие страницы как дубли.
- Чтобы ускорить индексацию полезных материалов. Поисковые системы выделяют на каждый ресурс краулинговый бюджет, то есть определенное количество страниц для сканирования. Лучше, чтобы этот лимит был израсходован на полезный для пользователей контент.
- Чтобы не навредить юзабилити. Если меняете структуру или дизайн сайта, лучше на это время скрыть ресурс от поисковых роботов. В противном случае, бот может зафиксировать снижение юзабилити площадки и понизить позиции сайта в выдаче.
Управлять процессом индексирования страниц на сайте помогают два файла:
- sitemap.xml. Карта сайта, которая помогает поисковым роботам ориентироваться среди папок и документов сайта. В этом файле можно прописать частоту обновления контента и приоритет для каждой страницы, тем самым управляя индексом. Карта сайта нужна для больших многостраничных ресурсов и сайтов с глубокой вложенностью. Лендингам и сайтам-одностраничникам карты сайта не нужны;
- robots.txt. В этом файле задаются правила для роботов. Именно здесь указываются параметры сканирования сайта или устанавливается запрет для индексации определенных страниц.
Также для этих целей используется HTML-разметка и консоли вебмастеров – Яндекс Вебмастер и Google Search Console.
.htaccess и robots.txt для WordPress
Свежеустановленный WordPress имеет в своей корневой директории файл .htaccess примерно такого содержания:
# BEGIN WordPress
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^index\.php$ -
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php
</IfModule>
# END WordPress
# BEGIN WordPress
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^index\.php$ -
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php
</IfModule>
# END WordPress
# Custom PHP Settings
#php_value post_max_size 30M
#php_value upload_max_filesize 30M
#php_value memory_limit 256M
#php_value max_execution_time 180
# Output ERROR information
#php_flag display_startup_errors on
#php_flag display_errors on
#php_flag html_errors on
# BEGIN WP Performance Score Booster Settings
## BEGIN GZIP Compression ##
<IfModule mod_deflate.c>
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/xml
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE application/rss+xml
AddOutputFilterByType DEFLATE application/javascript
AddOutputFilterByType DEFLATE application/x-javascript
AddOutputFilterByType DEFLATE application/x-httpd-php
AddOutputFilterByType DEFLATE application/x-httpd-fastphp
AddOutputFilterByType DEFLATE image/svg+xml
SetOutputFilter DEFLATE
</IfModule>
## END GZIP Compression ##
## BEGIN Vary: Accept-Encoding Header ##
<IfModule mod_headers.c>
<FilesMatch "\.(js|css|xml|gz)$">
Header append Vary: Accept-Encoding
</FilesMatch>
</IfModule>
## END Vary: Accept-Encoding Header ##
## BEGIN Leverage Browser Caching (Expires Caching) ##
<IfModule mod_expires.c>
ExpiresActive On
ExpiresByType text/css "access 1 month"
ExpiresByType text/html "access 1 month"
ExpiresByType image/jpg "access 1 year"
ExpiresByType image/jpeg "access 1 year"
ExpiresByType image/gif "access 1 year"
ExpiresByType image/png "access 1 year"
ExpiresByType image/x-icon "access 1 year"
ExpiresByType application/pdf "access 1 month"
ExpiresByType application/javascript "access 1 month"
ExpiresByType text/x-javascript "access 1 month"
ExpiresByType application/x-shockwave-flash "access 1 month"
ExpiresDefault "access 1 month"
</IfModule>
## END Leverage Browser Caching (Expires Caching) ##
## BEGIN Disable ETag header ##
Header unset Pragma
Header unset ETag
FileETag None
## END Disable ETag header ##
# END WP Performance Score Booster Settings
Файл robots.txt:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-json/ Allow: /wp-admin/admin-ajax.php Host: https://mastykov.by Sitemap: https://mastykov.by/sitemap_index.xml
Можно скачать архив с этими двумя файлами .htaccess и robotx.txt.




Как изменить профиль сети в Windows 10?
Как узнать тип процессора и версию системы FreeBSD?
Почему стандартный robots.txt бесполезен
У WordPress нет стандартного robots.txt, но его создает в частности плагин YoastSEO (за другие не знаю). В этом, автоматически созданном, robots.txt имеется всего две директивы для всех роботов:
User-agent: *Disallow: /wp-admin/Disallow: /wp-includes/
Удивительно что создатели плагина для SEO-оптимизации не смогли подготовить универсальный robots.txt. Я не понимаю зачем закрывать от индексации эти две директории, если там нечего индексировать. И многие владельцы сайтов почему-то втыкают «Disallow: /wp-admin» без малейшей попытки пораскинуть мозгами и понять что админка редиректит на страницу авторизации если ты не авторизован и индексировать там нечего. Также и «wp-includes» бессмысленно закрывать, поисковики там ничего не найдут полезного для себя поскольку нечего там индексировать.
Наша с вами задача не описать в robots.txt куда можно, а куда нельзя поисковику используя директивы «disallow» и «allow» налево и направо, а исключить из индекса страницы, которых там быть не должно. Для этого вам самим кроме копипаста придется ещё и информацию из кабинетов для веб-мастеров поизучать на предмет ненужных страниц в индексе поисковиков.
Я вам дам совет исходя из своего опыта на базе моего сайта, по-этому скопировав мой пример, дополните его своими директивами, наверняка у вас есть на сайте не совсем стандартные для WrdPress страницы, которые поисковикам нет смысла индексировать.
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т. д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
От предыдущего отличается более детальной проработкой под роботы Яндекса и Гугла. Кто-то считает, что таким образом эти ПС будут реагировать на правила лучше. Также здесь закрыты дополнительные технические страницы, фиды.
Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей
Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Итоги — или что сделать, чтобы стало все круто?
Наконец-то я могу подвести итог сегодняшнего огромного поста, и он будет кратким.
Чтобы улучшить качество индексации сайта, необходимо:
- Скрыть от гостей (к ним относятся и роботы) ссылки, которые им не нужны или не предназначены.
- Ссылки, которые нельзя удалить или спрятать от живых посетителей, стоит скрыть и выводить через JavaScript.
- Если ничего из перечисленного невозможно или не получается, то хотя бы необходимо закрыть ссылки на ненужные страницы атрибутом rel=”nofollow”. Хоть польза от этого и сомнительная, но все же…
- Страницы, которые не должны быть проиндексированы и не должны попасть в индекс поисковых систем, стоит запрещать при помощи метатега robots и параметра noindex:
- Страницы, содержащие тег robots не должны быть запрещены к индексации через robots.txt
Что даст нам весь этот «улучшайзинг»:
- Во-первых, чистота индекса сайта, что в наше время очень редко и почти не встречается.
- Во-вторых, быстрота индексации/переиндексации сайта увеличится за счет того, что робот не будет загружать страницы, которые закрыты для него.
- В-третьих, сохранится какая-то часть статического веса сайта, которая раньше утекала по ссылкам на закрытые страницы, а это может положительно отразится на ранжировании сайта.
- В-четвертых, это просто круто и говорит об уровне профессионализма вебмастера.
Фуф, два дня (а точнее — две ночи) писал этот пост и никак не мог дописать, но я это сделал! Потому жду ваших отзывов и комментариев.
Если у кого-то есть практический опыт по теме, обязательно поделитесь им со мной и другими читателями, это будет очень интересно и полезно.
Всем спасибо за внимание и до скорой встречи!