
Шаги для принятия правильных решений на основе данных
Эти шаги могут помочь вам определить «кто, что, где, когда и почему» данных для вас, ваших коллег и организации. Но имейте в виду, что цикл визуального анализа не является линейным. Один вопрос часто приводит к другому, что может потребовать от вас вернуться к одному из этих шагов или перейти к другому, что в конечном итоге приведет к полезным открытиям.
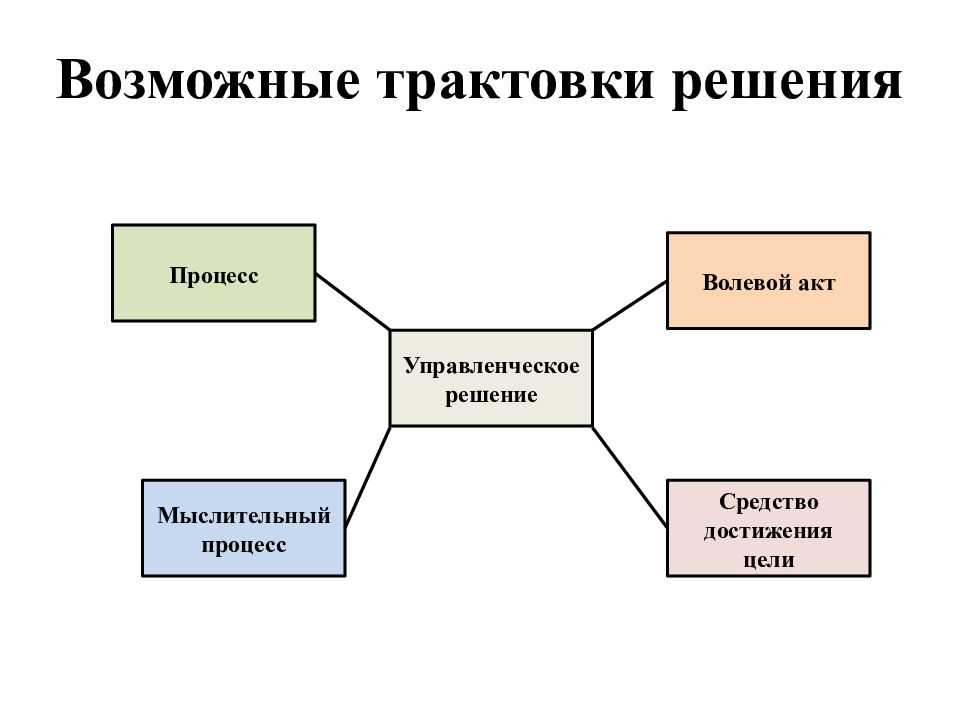
Шаг № 1: Определите свои бизнес-цели:
На этом этапе потребуется знание исполнительных и последующих целей вашей организации. Это может быть как узкое, например, увеличение продаж и трафика веб-сайта, так и более широкое, например, повышение узнаваемости бренда. Это поможет вам позже в процессе выбора ключевых показателей эффективности (KPI) и метрик, влияющих на решения, основанные на данных, а также поможет вам определить, какие данные изучать и какие вопросы задавать, чтобы ваш анализ поддерживал ключевые бизнес-цели.
Например, если маркетинговые усилия направлены на увеличение посещаемости веб-сайта, KPI может быть связан с количеством полученных контактов, чтобы продажи могли сопровождать потенциальных клиентов.
Шаг № 2. Запросите у бизнес-групп важные источники данных:
Для понимания краткосрочных и долгосрочных целей крайне важно получить информацию от сотрудников по всей организации. Эти входные данные влияют на вопросы, которые люди задают в своем анализе, а также на то, как вы расставляете приоритеты проверенных источников данных
Значимый вклад всей организации поможет определить направление развертывания вашей аналитики и ее будущее состояние, включая роли, обязанности, архитектуру и процессы, а также показатели успеха для анализа прогресса.
Шаг №3: Соберите и подготовьте необходимые данные:
Получение качественных и надежных данных может быть затруднено, если данные вашей компании разбросаны по нескольким источникам. После того как вы определили объем источников данных вашей организации, вы можете начать подготовку данных.
Начните с подготовки высокоэффективных и несложных источников данных. Выберите источники данных с наибольшим количеством людей, чтобы оказать немедленное влияние. Начните с этих ресурсов, чтобы создать высокоэффективную информационную панель.
Шаг № 4: Просмотрите и изучите данные:
Визуализация данных имеет решающее значение для принятия решений на основе данных. Визуально представляя свои мысли, у вас будет больше возможностей влиять на решения высшего руководства и других сотрудников.
Визуализация данных с ее различными визуальными функциями, такими как диаграммы, графики и карты, — это простой способ наблюдения и анализа тенденций, выбросов и закономерностей в данных. Существует множество популярных типов визуализации для успешного отображения информации, в том числе гистограмма для сравнения, карта для пространственных данных, линейная диаграмма для временных данных, точечная диаграмма для сравнения двух показателей и многое другое.
Шаг № 5: Получите информацию:
Находить идеи и выражать их в полезной и увлекательной форме — вот что влечет за собой критическое мышление с данными. Визуальная аналитика — это простой способ задавать вопросы о ваших данных и отвечать на них. Определите возможности и опасности, которые влияют на успех или решение проблем.
Чтобы делать выводы, важные для здоровья банка, JPMorgan Chase внедрил современное аналитическое решение. JPMC получает всестороннее представление о пути клиента, анализируя деловые отношения (т. е. продукты, маркетинг и точки соприкосновения с услугами) с данными о клиентах. Например, отдел маркетинговых операций проводит оценки, влияющие на решения по дизайну веб-сайта, рекламных материалов и таких продуктов, как мобильное приложение Chase.
Шаг № 6. Действуйте и делитесь своими выводами:
Как только вы обнаружили озарение, вы должны действовать в соответствии с ним или поделиться им с другими для сотрудничества. Совместное использование информационных панелей — один из способов добиться этого. Использование информативного текста и интерактивной графики для выделения важных идей может повлиять на решения вашей аудитории и помочь им совершать более осознанные действия в своей повседневной работе.
TrendMiner

TrendMiner — это решение самообслуживания для многих стартапов, позволяющее напрямую передавать информацию в руки инженеров, устраняя необходимость в аналитиках данных.
Возможности TrendMiner включают
- Анализ: он может найти основную причину любого шаблона или поведения, обнаруженного в сохраненной истории, с помощью алгоритмов расширенной аналитики.
- Монитор: инструмент постоянно отслеживает процесс и предупреждает вас, когда обнаруживает что-либо информативное.
- Предсказание: прогнозирует будущие результаты и помогает вам предпринимать выгодные действия.
- Контекстуализировать: обрабатывать данные в соответствующем контексте.
- MLHub: разверните свой анализ в рабочей среде с помощью MLHub.
Он популярен для оптимизации производительности, снижения энергопотребления, создания моделей обнаружения аномалий, обнаружения утечек воды и многого другого.
Кроме того, он включает в себя виртуальные датчики, которые одновременно обрабатывают несколько измерений или функций и выдают настраиваемые параметры для прогнозирования будущего.
Программирование
Если вы планируете карьеру в области науки о данных, вам нужно изучить программирование на должном уровне. Именно по этой причине многие специалисты в области данных обладают бэкграундом в компьютерных науках: это большое преимущество. Однако, если вы читаете эту статью и не обладаете опытом в программировании — не волнуйтесь, как и большинству вещей, этому можно обучиться самостоятельно.
Программа обучения: «Профессия Python-разработчик»
Мы выяснили, что программирование — важный навык для специалистов в области данных независимо от того, в какой сфере вы находитесь. Однако программирование в целом — не совсем то, что нужно науке о данных. А вот если вы сможете писать программы для автоматизации задач, то не только сэкономите драгоценное время, но и значительно упростите использование кода в будущем.
![Data-driven decision making: a step-by-step guide [2024] • asana](https://triathlon21.ru/wp-content/uploads/6/0/2/602d7e53448fbdaca5cdbabf4e02264b.jpeg)






Перейдем к некоторым ключевым навыкам. В списке я уделил больше внимания практическим навыкам.
Что надо знать
Разработка. Специалисты в области данных, знакомые с практикой разработки программного обеспечения, обычно чувствуют себя более комфортно, чем ученые, работая над крупными коммерческими проектами.
Базы данных. Логично, что специалисты в области данных постоянно используют базы данных, поэтому нужно иметь опыт в этой области. По мере роста баз данных NoSQL и количества облачных вычислений число традиционных SQL-баз данных резко сокращается. Однако работодатели по-прежнему ожидают, что вы будете иметь базовые знания о командах SQL и практику проектирования баз данных.
Сотрудничество. Сотрудничество — ключевой момент в разработке программного обеспечения. Вы, несомненно, знакомы с выражением: «Сила команды определяется её самым слабым звеном». Хоть это и банально, но правдиво для любой команды, специализирующейся в науке о данных. Большая часть работы ведется в группах, поэтому необходимо налаживать связь с командой, а также поддерживать хорошие отношения, чтобы эффективность сотрудничества была максимальной.
Полезные советы
Если спросить любого разработчика программного обеспечения или дата сайентиста о том, какой самый важный аспект программирования в работе, они обязательно ответят одинаково: простота технического сопровождения. Простой, поддерживаемый код почти всегда превосходит пусть и гениальный, но сложный код — он в конечном счете не будет иметь значения, если другие программисты не смогут его понять, оценить, масштабировать и поддерживать в дальнейшем. Есть несколько способов легко улучшить код. Вот они.
Не нужно хардкодить: не указывайте постоянных значений для каких-либо параметризуемых элементов кода, вместо этого используйте переменные и входные данные, они динамичны по своей природе и будут масштабироваться в будущем, в отличие от статических значений. Это небольшое изменение в коде значительно облегчит вам жизнь.
Документируйте и постоянно комментируйте свой код: самый эффективный способ сделать код понятнее — это комментировать, комментировать и комментировать. Кратко и информативно комментируя происходящее, вы убережете себя от бесконечных изменений и объяснений с коллегами.
Проводите рефакторинг: помните, что окончание разработки кода — это еще не конец. Постоянно возвращайтесь к прошлым работам и ищите способы оптимизации и повышения эффективности.
Что почитать
Навыки разработки программного обеспечения для специалистов в области данных (англ.) — отличный обзор важных навыков программирования.
Пять измерений дата сайентиста (англ.) — интересный подход к различным ролям, которые может взять на себя специалист в области данных
Обратите особое внимание на «Программист-эксперт» и «Эксперт по базам данных»
9 навыков, необходимых для старта карьеры в области данных (англ.) — короткая, но интересная статья.
Недостатки Data Driven-подхода
- Расходы на инфраструктуру. Чтобы собирать данные о клиентах, нужно внедрять новые инструменты. Действия в интернете, например, просмотры страниц, время на сайте, клики и переходы можно отслеживать с помощью классических сервисов Google Analytics или Яндекс.Метрика. Но иногда их функционала не хватает и приходится покупать дополнительные сервисы.
- Расширение штата сотрудников. Для анализа данных требуются компетентные специалисты, которые смогут не только настроить систему аналитики, но и вовлечь в процесс другие отделы. Поэтому, кроме найма новых работников, появляются затраты на обучение.
- Затраты ресурсов на очистку данных. Для корректных результатов данные на входе должны быть чистыми, то есть не содержать ошибочной информации, устаревшей или неактуальной для компании. Очистка данных — трудоемкий процесс, который может отнимать до 80% времени.
Ложно–положительный результат
Когда компания проверяет какой-либо вывод, есть высокий риск получить «ложно-положительный результат». Это происходит из-за психологических особенностей людей — мы стремимся создать самые благоприятные условия для положительного результата, и самые плохие для негативного. Причём, это может происходить неосознанно.В 1988 году Джон Мэддокс, редактор журнала Nature, попросил известного иллюзиониста Рэнди Джеймса присоединиться к наблюдению за экспериментом о проверке эффекта гомеопатических средств. Ранее команда Жака Бенвенитэ, популярного гомеопата, провела эксперимент так, что пробирки с гомеопатией давали положительную реакцию. Повторный эксперимент под наблюдение Рэнди расставил всё на свои места — положительные результаты повторить не удалось. Единственное, что он сделал — попросил о слепом тестировании, когда ни лаборанты, ни сам иллюзионист, не знали, в какой пробирке гомеопатия, а в какой — вода в качестве контрольной группы. То же самое происходит в бизнесе — команда очень хочет, чтобы их предположение о новой нише подтвердилось, поэтому аргументы «за» раздуваются, а аргументы «против» исключаются.Вывод #1: старайтесь работать вслепую — когда предлагаете обсудить решение, переведите исходные данные в абстрактный язык логики. Например, предыдущий пример о видео в соцсетях звучал бы так: компания X выпустила на своей странице в социальной сети публикацию, которая получила Y результатов A и B. Нормальный результат A и B — 1/2Y. Стоит ли компании масштабировать публикацию?Вывод #2: делитесь выводами и советуйтесь с людьми, которые не являются бенефициарами вашей компании. Люди со стороны обычно мыслят более трезво.Вывод #3: начинайте рассуждение на базе цифр с тезиса «Это ошибка, потому что…». Старайтесь доказать негативный результат.
Что такое data science?
Профессор Школы бизнеса Штерна Васант Дхар предложил следующее определение:«Data science — это исследование обобщаемого извлечения знаний из данных».Хотя это одно из самых популярных определений data science, оно требует более подробного объяснения.Data science — это непрерывно эволюционирующая научная дисциплина, нацеленная на понимание данных () и на поиск выводов из них. Data science использует big data и обширное множество различных исследований, методов, технологий и инструментов, в том числе машинное обучение, ИИ, глубокое обучение и data mining. Эта научная сфера сильно зависит от анализа данных, статистики, математики и программирования, а также от и интерпретирования данных. Всё это помогает дата-саентистам принимать обоснованные решения на основании данных и определять, как извлекать из них ценность и полезные для бизнеса выводы.
Процесс и примеры применения data science
Дата-саентисты работают с огромными объёмами данных, пытаясь добиться их понимания. Благодаря использованию нужных дата-саентисты могут собирать, обрабатывать и анализировать данные для того, чтобы делать суждения и прогнозы на основе полученных выводов.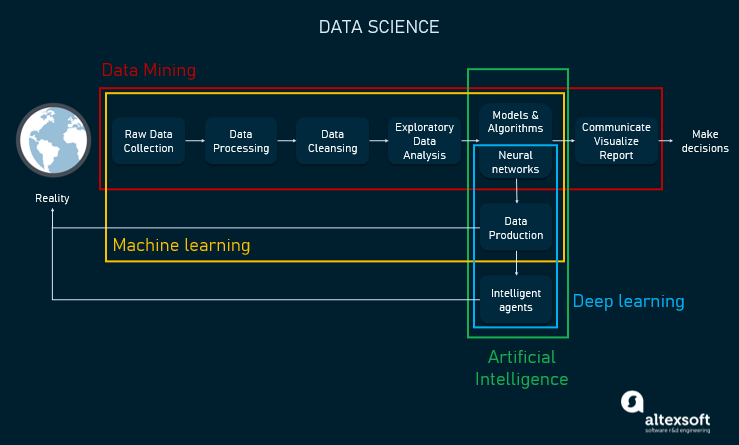 Иллюстрация взаимосвязей между data science, машинным обучением, искусственным интеллектом, глубоким обучением и data mining.Уже многие годы data science эффективно используется в различных отраслях для внедрения инноваций, оптимизации стратегического планирования и совершенствования производственных процессов. И огромные корпорации, и мелкие стартапы собирают, а затем анализируют данные для развития своих бизнесов и повышения прибылей. Логика проста ‒ чем больше данных вы можете собрать и обработать, тем больше вероятность того, что вы сделаете из этих данных важные выводы. При помощи предсказательной аналитики бизнесы могут выявлять паттерны данных, о которых они и не догадывались. Одним из примеров таких областей применения является .Например, финансовая компания может выяснить, что клиенты, правильно расставляющие в тексте заглавные буквы, более надёжны, когда дело касается выплаты кредитов онлайн.Ещё одним популярным примером использования data science является . Рассмотрим компанию, занимающуюся производством графических карт. Предположим, что компания знает о выпуске новых популярных видеоигр. Она знает приблизительные даты, а также то, каким из игр требуются мощные GPU. В наилучшем для компании случае она сможет выполнить точное предсказание спроса, чтобы спрогнозировать будущие продажи и оптимизировать прибыль. сначала собирают исторические данные, сравнивают схожие ситуации с ожидаемыми, производят вычисления, а затем планируют предложение, чтобы покрыть спрос.
Иллюстрация взаимосвязей между data science, машинным обучением, искусственным интеллектом, глубоким обучением и data mining.Уже многие годы data science эффективно используется в различных отраслях для внедрения инноваций, оптимизации стратегического планирования и совершенствования производственных процессов. И огромные корпорации, и мелкие стартапы собирают, а затем анализируют данные для развития своих бизнесов и повышения прибылей. Логика проста ‒ чем больше данных вы можете собрать и обработать, тем больше вероятность того, что вы сделаете из этих данных важные выводы. При помощи предсказательной аналитики бизнесы могут выявлять паттерны данных, о которых они и не догадывались. Одним из примеров таких областей применения является .Например, финансовая компания может выяснить, что клиенты, правильно расставляющие в тексте заглавные буквы, более надёжны, когда дело касается выплаты кредитов онлайн.Ещё одним популярным примером использования data science является . Рассмотрим компанию, занимающуюся производством графических карт. Предположим, что компания знает о выпуске новых популярных видеоигр. Она знает приблизительные даты, а также то, каким из игр требуются мощные GPU. В наилучшем для компании случае она сможет выполнить точное предсказание спроса, чтобы спрогнозировать будущие продажи и оптимизировать прибыль. сначала собирают исторические данные, сравнивают схожие ситуации с ожидаемыми, производят вычисления, а затем планируют предложение, чтобы покрыть спрос.
Обзор базовых методов обработки данных
В Data Science существует множество методов и техник обработки данных, которые позволяют проводить анализ и получать ценные знания из имеющейся информации. В данном разделе мы рассмотрим несколько базовых методов обработки данных.
1. Очистка данных
Данные, полученные из различных источников, могут быть несогласованными, содержать ошибки или пропуски. Возможно, потребуется удалить дубликаты, заполнить пропущенные значения или исправить ошибки. Очистка данных позволяет получить надежные и точные данные для дальнейшего анализа.
2. Преобразование данных
Преобразование данных может включать в себя изменение формата, масштабирование или приведение в определенный вид. Например, числовые данные могут быть масштабированы для облегчения их сравнения, а категориальные данные могут быть закодированы числовыми значениями.
3. Агрегация данных
Агрегация данных включает суммирование, подсчет средних значений, нахождение минимума или максимума, группировку по определенным признакам и т. д. Это позволяет получить сводную информацию о данных и выявить общие закономерности.
4. Фильтрация данных
Фильтрация данных позволяет выбирать только те записи или переменные, которые отвечают определенным критериям. Например, можно выбрать только записи за определенный период времени или только те переменные, которые имеют определенные значения.
5. Объединение данных
Объединение данных позволяет комбинировать информацию из разных источников или таблиц в одну единую структуру. Например, можно объединить данные о клиентах из разных баз данных, чтобы анализировать их вместе.







Это лишь небольшой обзор базовых методов обработки данных в Data Science. Каждый из этих методов может иметь различные вариации и подходы в зависимости от специфики задачи и данных
Важно уметь выбрать и применить подходящие методы для конкретного исследования или анализа данных
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Cloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах Cloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер Cloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании Cloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Что такое разведочный анализ данных?
Разведочный анализ данных, Exploratory Data Analysis (EDA) — один из первых и определяющих шагов проекта науки о данных, который приводит в движение весь проект. Он придает проекту конкретное направление и формирует план его реализации.
Разведочный анализ данных означает изучение данных до самых глубин для получения из них практической информации. Он включает в себя анализ и обобщение массивных наборов данных, часто в форме диаграмм и графиков.
Следовательно и бесспорно это самый важный этап в проекте науки о данных, по собственному опыту знаю, что он всегда занимает 70-80% времени всего проекта. Чем лучше вы знаете свой набор данных, тем лучше вы сможете его использовать! Чтобы лучше понять, какое место EDA занимает во всем процессе анализа данных, вот вам иллюстрация:
Место EDA в процессе анализа данных
Думается, что теперь у вас появилось чёткое представление о месте, занимаемое EDA и вы готовы погрузиться в подробности!
Что такое машинное обучение?
— это набор методик, инструментов и компьютерных алгоритмов, используемый для обучения машин анализу, пониманию и нахождению сокрытых паттернов в данных, а также для создания прогнозов. Конечная цель машинного обучения заключается в использовании данных для самообучения, устраняющего необходимость программирования машин вручную. После обучения на массивах данных машины могут применять запомненные паттерны к новым данным, делая благодаря этому более точные прогнозы.Машинное обучение бывает разных видов:При обучении с учителем машины обучаются находить решение нужной задачи при помощи людей, собирающих , которые затем передаются системам
Машине указывают, на какие характеристики данных нужно обращать внимание, чтобы она могла выявлять паттерны, помещать объекты в соответствующие классы и оценивать правильность своих прогнозов.При обучении без учителя машины учатся распознавать паттерны и тренды в неразмеченных данных обучения без надсмотра пользователей.При обучении с частичных привлечением учителя модели обучаются на небольшом объёме и гораздо большем объёме неразмеченных данных, используя обучение с учителем и без учителя.При модели, помещённые в незнакомое им окружение, должны найти решение задачи путём последовательных проб и ошибок. Аналогично системе, используемой во многих играх, машины получают наказание за ошибку и вознаграждение за успешную попытку
Таким образом они учатся находить оптимальное решение.
Процесс машинного обучения и примеры его использования
Для демонстрации работы машинного обучения мы возьмём классический пример фильтрации спама в электронной почте. Если вы откроете папку спама в своём аккаунте электронной почты, то увидите множество ненужных и раздражающих сообщений. Системы распознавания спама помогают в отфильтровывании неуместных сообщений от важных пользователям.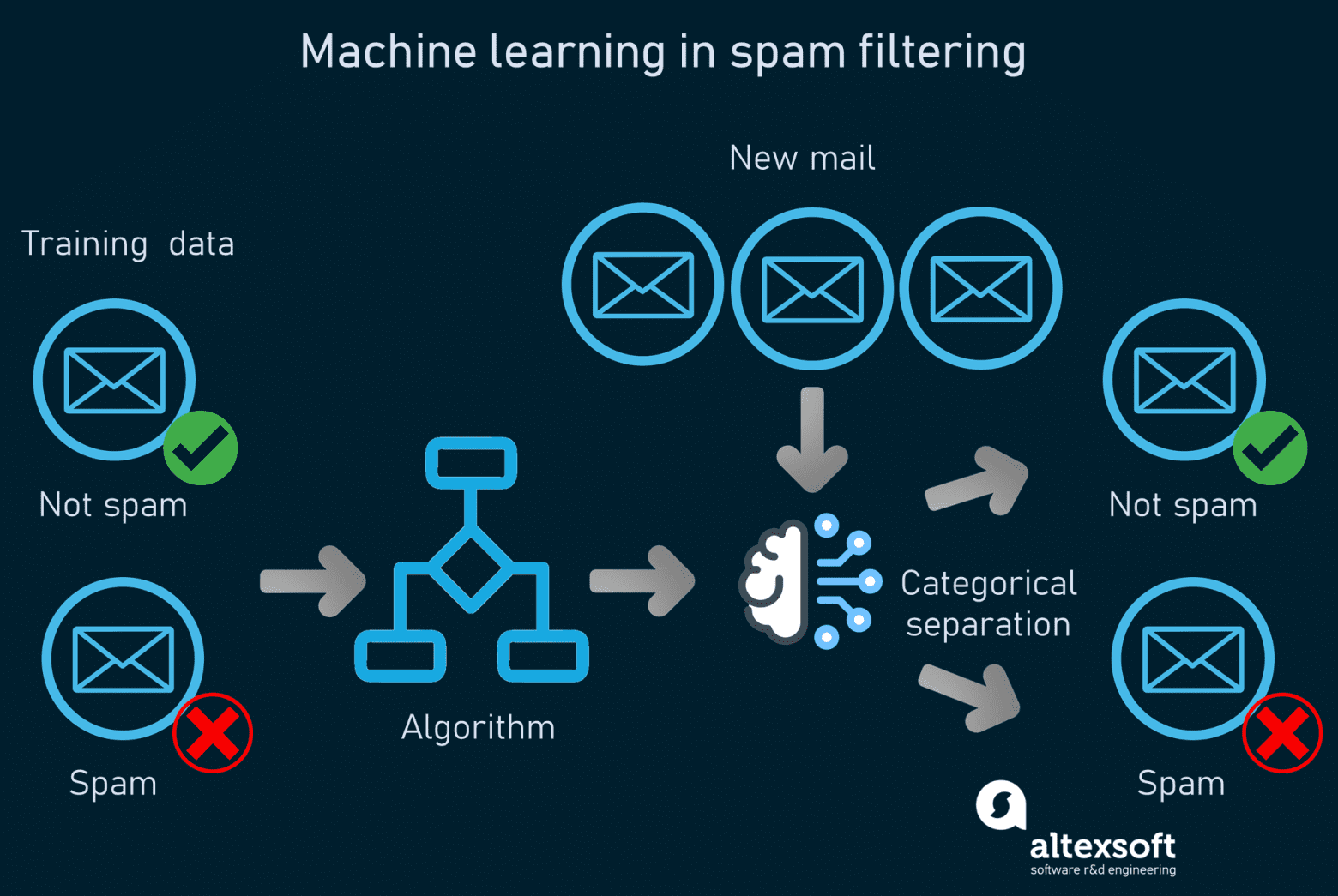 Как работает машинное обучение в распознавании спама.Системы анализируют содержимое электронных писем и классифицируют данные при помощи алгоритмов машинного обучения. Задача таких моделей — определять, является ли письмо спамом. Так как распознавание спама — задача для машинного обучения с учителем, модель сначала обучается на размеченных массивах данных — примерах спама и обычных сообщений, выбранных людьми. Подробнее о подготовке данных в машинном обучении можно узнать из нашей или из видео:
Как работает машинное обучение в распознавании спама.Системы анализируют содержимое электронных писем и классифицируют данные при помощи алгоритмов машинного обучения. Задача таких моделей — определять, является ли письмо спамом. Так как распознавание спама — задача для машинного обучения с учителем, модель сначала обучается на размеченных массивах данных — примерах спама и обычных сообщений, выбранных людьми. Подробнее о подготовке данных в машинном обучении можно узнать из нашей или из видео:
Основы подготовки данных для машинного обученияОдин из популярных способов обучения модели — это наивный байесовский алгоритм, вычисляющий вероятность событий или результатов на основании полученных ранее знаний. Этот способ выполняет корреляцию одних признаков с спам-сообщениями и других признаков — с обычной почтой. Признаки — это слова или фразы, находящиеся в теле и заголовке письма. Затем он вычисляет вероятность того, что конкретное сообщение является спамом.Вам известно, что сообщение с заголовком «Вы выиграли 1000000 долларов», скорее всего, является спамом, но машине сначала нужно этому научиться. В процессе изучения моделью паттернов она может точно присваивать каждому новому письму оценку. Письма, оценка которых превышает пороговое значение, попадают во входящие, а письма с более низкой оценкой помечаются как мусорные. При пользовании сервисами электронной почты люди вручную помечают некоторые входящие сообщения как спам, добавляя новые данные в массив данных обучения системы. Это часть называется переобучением модели, она гарантирует актуальность системы и обеспечение ею точных результатов.Ещё одним примером машинного обучения является медицинское прогнозирование того, какие пациенты имеют повышенную вероятность заболевания, при помощи анализа их электронных медицинских записей и жалоб. Замечательный пример машинного обучения — это . Они помогают сигнализировать о возможном мошенничестве, анализируя подозрительное поведение пользователей.
Как начать работать с данными
Работа с данными начинается с команды. Например, Бернард Марр, публицист и автор книг о работе с данными, выгнать гиппопотама из комнаты. Вернее, take HiPPO out of the room. HiPPO — highest paid person’s opinion, или по-русски — мнение человека с самой высокой зарплатой. Авторитет, выраженный в более высокой должности или зарплате, невольно заставляет сознание окружающих деформироваться. Лучший способ это сделать — внедрить практику proof or die (докажи или умри). Согласно практике PoD, каждый важный тезис должен быть подтверждён ссылкой. Даже если это очевидный факт. Даже сказанный в курилке.Эрик Ларсон, основатель сервиса для командного принятия решений Cloverpop, завести ‘Decision Log’ — документ, где будет фиксироваться, кто принял решение, на чём решение основано, и мнение об этом решении остальных участников команды. Это снизит количество необдуманных решений — такой документ заставит команду перепроверять свои предложения многократно.Про найм и развитие навыков работы с данными внутри команды Марио Трескон, Старший Директор по Business Intelligence и Data Science в YMCA: «Компаниям стоит взять столько времени, сколько потребуется, чтобы удостовериться, что они нанимают правильных людей. Здорово иметь тренированных аналитиков-профессионалов в качестве ядра, но я бы рекомендовал строить команду с теми, у кого есть бизнесовый опыт — это поможет превратить анализ в действия. Также добавлю, что образование и опыт в сфере социальных наук поможет соединить человеческие и поведенческие факторы с данными».Сам процесс сбора и обработки данных начинается с аудита бизнеса и определения главных показателей роста бизнеса. Обычный минимальный набор для сбора данных: данные о клиентах, данные о рынке, данные о бизнесе и данные о продукте.Данные о клиентах — результат профилирования, сочетаемый с атрибуцией. Чем больше данных о клиентах мы знаем, тем точнее предложение и оптимальнее канал, а значит ниже издержки на привлечение.Данные о рынке — результат анализа спроса и конкурентной среды. Конкуренты дадут бенчмарки — эталонные цифры, которые помогут понять, где есть пространство для роста, а где результаты и так выше рыночных. Анализ спроса помогает составить представление о том, какие ниши в вашем рынке существуют, и насколько там высока конкуренция.Данные о продукте — результат анализа воронки, включая повторные транзакции и приглашения других пользователей. Поиск и расшитие узких мест — один из ключевых факторов роста. Данные о бизнесе — финансовый и процессуальный анализ организации. Главный фактор роста в этих данных — повышение возврата инвестиций. Добиться можно путём снижения издержек, как финансовых, так и временных, а также с помощью перераспределения ресурсов внутри организации.Идеальный сценарий — разработка data warehouse, куда стекаются все данные из разных источников. Сопоставление в одном интерфейсе данных из разных областей помогает ускориться.Вообще, выбор инструментов работы с данными — отдельная тема. Мы рекомендуем придерживаться простых правил:
- Защита «от дурака» — стоимость ошибки при работе с данными может быть очень велика, поэтому постарайтесь использовать инструменты, которые помогут команде снизить вероятность человеческой ошибки. Например, здорово, если при запуске A/B-тестирования в рассылках, отправщик писем сам посчитает размер выборки и предоставит вывод об успехе того или иного варианта.
- Сквозные дашборды — гораздо проще оценить эффективность решения, если не обращаться каждый раз к аналитикам за помощью. Чем больше визуальных и персональных дашбордов есть в компании, тем быстрее принимаются решения. Также дашборды помогают внедрить культуру работы с данными — людям нравится смотреть на графики и цифры.
- Доступный клиентский сервис — это кажется ерундой, но на самом деле у вас будет много вопросов. Очень много. На них помогает отвечать комьюнити, документация и прочие вспомогательные ресурсы, но если у вас есть доступ к локальной поддержке — это очень сильный бонус.
Истоки
Несмотря на десятилетия разработки решений системы поддержки и методологии (например, анализ решений ), они все еще менее популярны, чем электронные таблицы в качестве основных инструментов для принятия решений. Интеллектуальная система принятия решений стремится восполнить этот пробел, создавая критическую массу пользователей общей методологии и языка для основных сущностей, включенных в решение, таких как предположения, внешние ценности, факты, данные и заключения. Если модель из предыдущих отраслей верна, такая методология также будет способствовать внедрению технологий за счет уточнения общих моделей зрелости и дорожных карт, которыми можно поделиться от одной организации к другой.


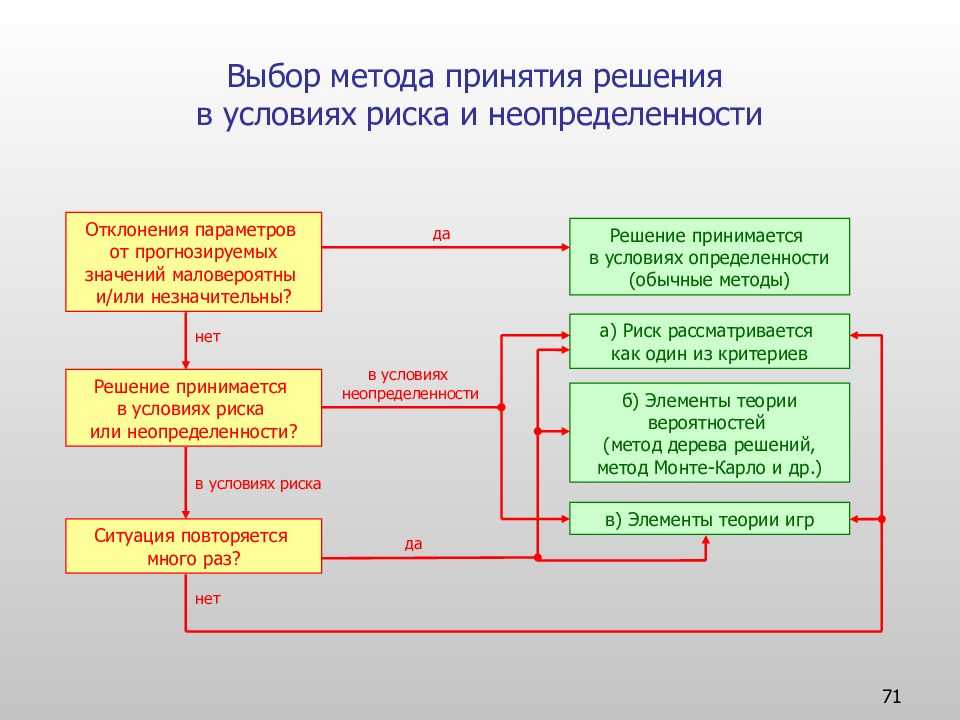



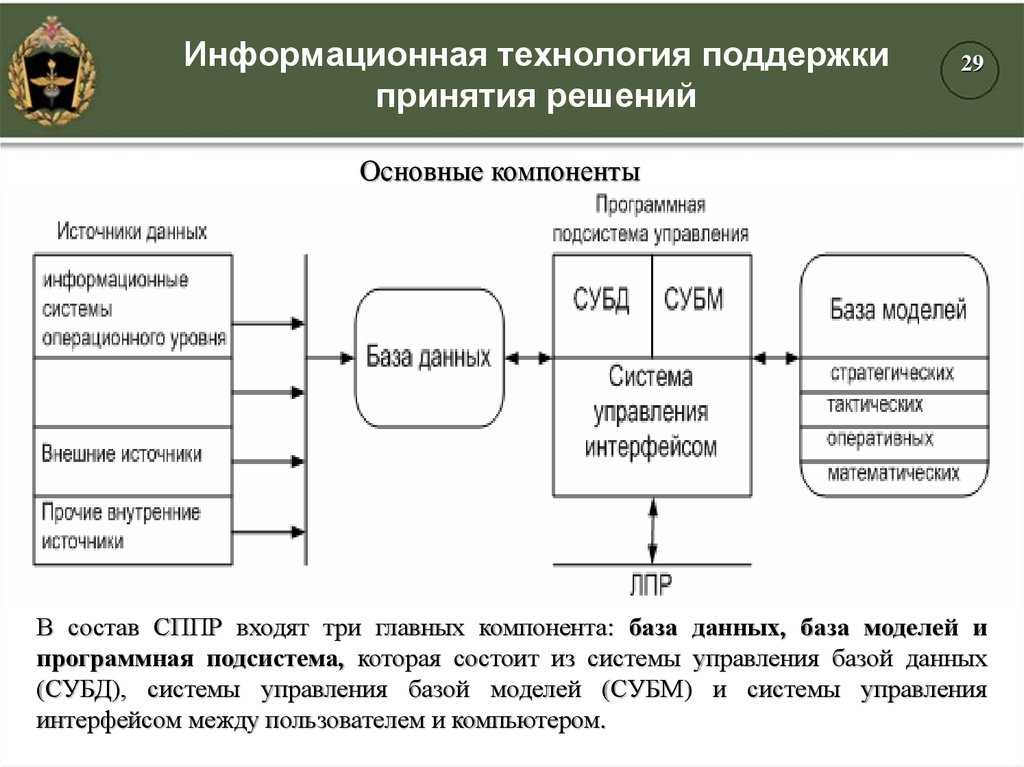

Подход к анализу решений является междисциплинарным, объединяющим результаты по когнитивному искажению и принятию решений, ситуационной осведомленности, критическому и творческому мышление, сотрудничество и организационное проектирование, с инженерными технологиями.
Интеллектуальная система принятия решений считается улучшением текущей практики принятия решений в организации, которая включает использование электронных таблиц, текста (последовательного по своей природе, поэтому не подходит для того, как информация проходит через структура решения) и вербальный аргумент. Переход от этих в значительной степени неформальных структур к структуре, в которой решение документируется на хорошо понятном визуальном языке, перекликается с созданием общих методологий blueprint в строительстве с обещанием аналогичных преимуществ.
Интеллект принятия решений — это одновременно очень новая и очень старая дисциплина. Многие из его элементов, такие как язык оценки предположений, использование логики для поддержки аргумента, необходимость критического мышления для оценки решения и понимание воздействия bias — древние. Тем не менее осознание того, что эти элементы могут образовывать единое целое, которое обеспечивает значительные преимущества организациям за счет сосредоточения на общей методологии, является относительно новым.
В 2018 году процессы и учебные программы Google в области прикладной науки о данных были переименованы в «интеллектуальный анализ решений», чтобы указать на центральную роль действий и решений в применении науки о данных. Степень, в которой теоретические основы опирались на управленческие и социальные науки в дополнение к науке о данных, была дополнительным мотивом для объединения интеллекта принятия решений в область исследования, отличную от науки о данных.
Современный интеллект принятия решений очень важен. междисциплинарный и академически инклюзивный. Исследования, сосредоточенные на решениях, определяемых в широком смысле как биологические и небиологические выбор действия, считаются частью дисциплины. Однако интеллектуальный анализ решений не является общим термином для науки о данных и социальных наук, поскольку он не охватывает компоненты, не связанные с решениями.
Что такое Data Science
Data Science (DS) — это междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях.
Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию.
Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким.
В 2010-х годах объемы данных по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).
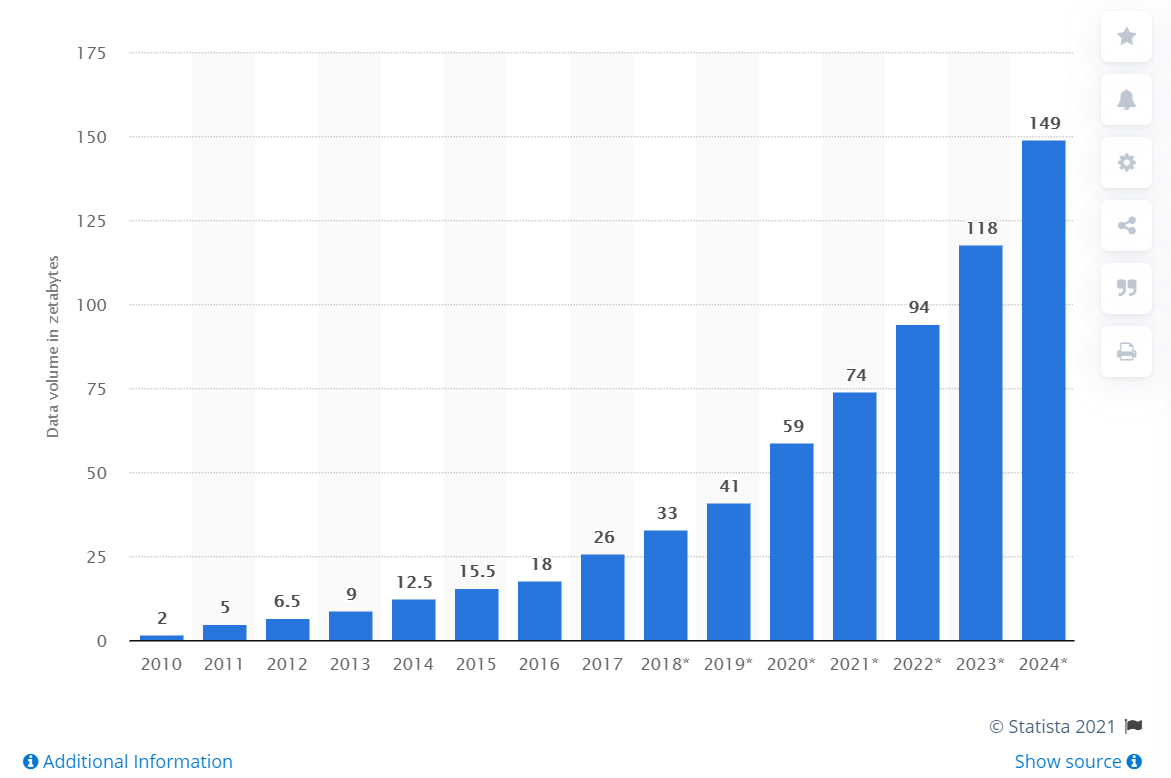
Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах)
(Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.