
Elasticsearch

Elasticsearch — это система полнотекстового поиска и аналитики. Это система хорошо масштабируемый и распределенный, специально разработанный эффективно и быстро работать с системами больших данных, где одним из основных вариантов использования является анализ журналов.
Он способен выполнять расширенный и сложный поиск и обработку данных в режиме, близком к реальному времени, для расширенного анализа и оперативного интеллекта.
Elasticsearch написан на Java и основан на Apache Lucene, Elasticsearch основан на документе JSON со структурой без схемы, что упрощает его внедрение.
Это одна из ведущих поисковых систем бизнес-класса. Вы можете написать своего клиента на любом языке программирования; Elasticsearch официально работает с Java, .NET, PHP, Python, Perl и т. Д.
Frequently Asked Questions (FAQs)
1. What are the 5 Vs of Big Data?
Big Data is becoming popular among companies for the benefits it provides. Companies, governments, and the healthcare system are using Big Data to analyse various aspects of the field and develop innovative solutions using the insights received. The characteristics of Big Data can be defined with the help of 5 Vs, namely: Volume, which helps determine whether a particular data can be considered big or not; Velocity, which is the speed of accumulation of data; Variety, which defines the type of data, whether it is structured, semi-structured, or unstructured; Veracity, which relates to inconsistency and anomaly in data; and Value, which means the data have to convert into something valuable to draw insights.
2. What are the 3 main parts of the Hadoop infrastructure?
Hadoop is an open-source framework used to store data across many computers in a distributed environment. The 3 core components of Hadoop are Hadoop Distributed File System (HDFS), MapReduce, and Yet Another Source Negotiator (YARN). HDFS, a file system of the Hadoop cluster, handles large data and provides scalable data storage running on commodity hardware. It also facilitates compatibility across various underlying operating systems. MapReduce is basically a programming model used to process and generate large data sets across multiple machines. YARN was introduced as an improvement over Job Tracker. It facilitates many data processing engines to process data stored in HDFS.
Как узнать больше об инструментах исследования данных и их использовании
Существует множество инструментов для анализа данных и бесчисленное множество способов их использования. Для тех, кто хочет получить больше от своих данных, независимо от того, новичок вы в Data Science или опытный профессионал, практическое обучение работе с этими инструментами – лучший способ узнать, как они работают. На ODSC East 2023 у нас есть ряд сессий, связанных с визуализацией данных и инструментами исследования данных. Зарегистрировавшись сейчас со скидкой 60%, вы сможете увидеть эти сеансы и многое другое.
- Graph Viz: Изучение, анализ и визуализация графиков и сетей: Тамилла Трианторо, доктор философии | адъюнкт-профессор компьютерных информационных систем | Университет Квиннипиак
- Beyond the Basics: Визуализация данных на Python: Стефани Молин | Инженер-программист, специалист по обработке данных, руководитель отдела информационной безопасности, автор практического анализа данных с Pandas | Bloomberg LP
- Streamlining Your Streaming Analytics with Delta Lake & Rust: Гэри Наканелуа | управляющий директор по инновациям | Blueprint Technologies (BPCS)
- Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI: Джонас Мюллер | Главный научный сотрудник и соучредитель | Cleanlab
- How to build stunning Data Science Web applications in Python — Taipy Tutorial: Флориан Джакта и Альберт Ву | Менеджеры по успеху клиентов | Taipy
- Interactive Explainable AI: Мэг Курдзиолек, доктор философии | старший исследователь UX | Google
- Next-Level Data Visualization in Python:: Практическое руководство по улучшению ваших графиков за счёт максимального использования Matplotlib и многое другое: Мелани Вил, доктор философии | Архитектор решений для обработки данных | Anomalo
+1
+1
+1
+1
+1
Просмотры: 939
Types of Big Data Technologies
In general, Big Data Technology can be divided into two categories:
Operational Big Data Technologies
Operational big data refers to all the data we generate from day-to-day activities such as internet transactions, social media platforms, or any information from a particular company. This data serves as raw data to be analyzed by Operational big data technology. Some examples of Operational Big Data Technologies include:
- Online ticket booking system, such as for trains, flights, buses, movies, etc.
- Online trading or shopping on e-commerce websites such as Flipkart, Amazon, Myntra, etc.
- Online data from social networking sites such as Instagram, Facebook, Messenger, Whatsapp, etc.
- Employee data or executive details in multinational companies.
Analytical Big Data Technologies
Analytical Big Data may be viewed as a modified variant of Big Data Technologies, which is more complicated than Operational Big Data. Analytical Big Data is typically employed when performance metrics are involved, and when critical business decisions need to be taken on the basis of reports generated through operational big data analysis. Therefore, this type of big data technology pertains to analyzing big data relevant to business decisions. Some examples of Analytical Big Data Technologies include:
- Stock marketing data.
- Weather forecasting data.
- Medical records allow doctors to monitor the health status of a patient.
- Maintaining space mission databases in which every detail about a mission is important.
Comparing Open Source ETL Tools
| ETL Tools | Format Supported | Integrations | Automation | Codeless/Code-based | Installation & Deployment | Subscription |
| Multiple data formats | More than 150 plug-and-play connectors—including file systems, databases, and SaaS applications. | Yes | Codeless | On-premises and cloud-based | Free for starter, the rest available on the website | |
| JSON, XML, SOAP, ZIP, and more (50+ types) | Spring, Quarkus, and CDI | Yes | Code-based | On-premises and as an embeddable library | Free | |
| CSV, JSON, Excel, Feather, Parquet and more | Can connect to > 30 protocols | Yes | Low Code/No Code | On-premises and cloud-based | Depeonds on the number of connectors | |
| Event-record format | connects to hundreds of event sinks and sources, such as Amazon S3, Postgres, JMS, Elasticsearch, and more. | Yes | Codeless | able to be implemented on cloud, on-premises, in virtual machines, and containers | Free | |
| XML, JSON, CSV, logs, and more | Cloud platforms, Kubernetes, Confluence, and CRMs | Yes | Codeless | On-premises and cloud-based | Free | |
| Multiple data formats | Java-based libraries | Yes | Codeless | On-premises | Enterprise Edition/community Project | |
| All big data formats | RDMS,SaaS connectors, CRMs | Yes | Codeless | On-premises and cloud-based | Free | |
| Multiple sources | Python-based libraries | Yes | Code-based | Virtual environment or on-premises | Free | |
| JSON, XML, AVRO, Parquet | variety of data sources | Yes | Codeless | On-premises and cloud-based | Available on the website | |
| JSON, XML, Avro, Parquet, Apache Thrift,CSV, HL7, Protocol Buffers,Apache ORC, Grok patterns | Apache Kafka, Apache Hadoop, Amazon S3, MongoDB, Elasticsearch | Yes | codeless | able to be implemented on cloud, on-premises, in virtual machines, and containers | Available on the website | |
| All data formats | All 3rd party Java libraries | Yes | Codeless | On-premises and cloud-based | Available on the website |
How to choose Big Data technology?
A tricky question. To sum up, it’s safe to say that there is no single best option among the data processing frameworks. Each one has its pros and cons. Also, the results provided by some solutions strictly depend on many factors.
In our experience, hybrid solutions with different tools work the best. The variety of offers on the Big Data framework market allows a tech-savvy company to pick the most appropriate tool for the task.
Which is the most common Big data framework for machine learning?
Clearly, Apache Spark is the winner. It’s H2O sparkling water is the most prominent solution yet. However, other Big Data processing frameworks have their implementations of ML. So you can pick the one that is more fitting for the task at hand if you want to find out more about applied AI usage, read our article on AI in finance.
Do you still want to know what framework is best for Big Data?
While we already answered this question in the proper way before. Those who are still interested, what Big Data frameworks we consider the most useful, we have divided them in three categories.
- The Storm is the best for streaming, Slower than Heron, but has more development behind it;
- Spark is the best for batch tasks, useful features, can do other things;
- Flink is the best hybrid. Was developed for it, has a relevant feature set.
However, we stress it again; the best framework is the one appropriate for the task at hand.
Although there are numerous frameworks out there today, only a few are very popular and demanded among most developers. In this article, we have considered 10 of the top Big Data frameworks and libraries, that are guaranteed to hold positions in the upcoming 2024.
The Big Data software market is undoubtedly a competitive and slightly confusing area. There is no lack of new and exciting products as well as innovative features. We hope that this Big Data frameworks list can help you navigate it.
What Big Data software does your company use? Here at Jelvix, we prefer a flexible approach and employ a large variety of different data technologies. We take a tailored approach to our clients and provide state-of-art solutions. Contact us if you want to know more!
BuiltWith
BuiltWith — невероятно мощный инструмент для поиска веб-сайтов, позволяющий пользователям узнавать о техническом стеке, фреймворках, плагинах и другой информации, используемой на популярных веб-сайтах. Это может быть полезно для тех, кто заинтересован в использовании подобных технологий для своих сайтов.
Кроме того, BuiltWith также перечисляет библиотеки JavaScript/CSS, которые могут использоваться веб-сайтом, обеспечивая дополнительную детализацию и понимание архитектуры определенных веб-сайтов. В результате BuiltWith полезен не только для случайных исследований, но также может использоваться для проведения разведки от имени предприятий или организаций, которым необходимо точно знать, как составлены различные веб-страницы.
Для дополнительной гарантии безопасности вы можете комбинировать BuiltWith со сканерами безопасности веб-сайтов, такими как WPScan, которые специализируются на выявлении распространенных уязвимостей, влияющих на веб-сайт.
Python

Уровень: начальный.Необходимые навыки: высокая самообучаемость, развитое аналитическое и абстрактное мышление.Области применения: веб-разработка, десктопные графические интерфейсы, бизнес-приложения, машинное обучение (ML) и глубокое обучение (DL), наука о данных (Data science), искусственный интеллект (AI), игры, микроконтроллеры, анализ и визуализация данных.


![7 лучших ии и систем машинного обучения с открытым исходным кодом [записки админа и инженера]](https://triathlon21.ru/wp-content/uploads/4/3/a/43a6af566875cebb86081d2be01ddb32.png)






Плюсы:
- Повышенная производительность.
- Интуитивно простое чтение и написание.
- Развитая официальная документация и учебные пособия.
- Динамическая типизация — компиляция скриптов происходит непосредственно во время выполнения.
- Интерпретируемый язык выполняет код построчно и сообщает об ошибках последовательно, что упрощает отладку.
- Простая интеграция с веб-службами.
- Обширная нативная библиотека и упрощенный экспорт со встроенным диспетчером пакетов Python (pip).
- Может масштабировать даже самые сложные приложения.
- Идеально подходит для создания прототипов и быстрого тестирования идей.
Минусы:
- Низкая скорость. Построчное выполнение кода часто приводит к его медленному выполнению.
- Большая нагрузка на память. Производительность Python требует компромисса — повышенного потребления системных ресурсов.
- Из-за повышенного потребления памяти и низкой скорости, не подходит для разработки мобильных и фронтэнд приложений.
- Плохо развитое взаимодействие с базами данных.
- Возможны ошибки выполнения (Runtime Error), связанные с динамическим изменением типа данных переменной. Из-за этого код на Python требует более тщательного тестирования.
- Не поддерживает многопоточность из-за встроенного механизма глобальной блокировки интерпретатора (GIL, Global Interpreter Lock)
Пример синтаксиса
print("Hello World!")
Почему нужно изучать Python
В последние годы Python возглавляет большинство крупнейших рейтингов самых популярных языков разработки. Это бесплатный язык разработки с открытым исходным кодом считается одним из лучших «входных билетов» в программирование для новичков. Ведь его отличает предельно простой синтаксис команд, схожий с английским языком и крайне высокая степень абстракции.
Python не только часто возглавляет список самых легких языков программирования, но и считается одним из наиболее универсальных. Он одинаково хорошо справляется с созданием веб-приложений и разработкой продуктов для обучения искусственного интеллекта, а также отлично подходит для игр и высокотехнологичных мультимедиа продуктов.
Python используется для разработки пакетов 2D-изображений и 3D-анимации, таких, как Blender, Inkscape и Autodesk. Он также применялся для разработки ряда высокобюджетных видеоигр, включая Civilization IV, Vegas Trike и Toontown. На Python написаны многие научные и вычислительные приложения, такие как FreeCAD и Abacus, а также такие популярные веб-сайты, как YouTube, Quora, Pinterest и Instagram.
Где изучать
- Официальная документация «The Python Tutorial».
- Руководство «Learn Python» от Berkeley Boot Camps.
- Видеокурс «Learn Python» от freeCodeCamp.
- Подкаст «The Real Python» от Real Python.
- Курс «Learn Python 2» от Codecademy.
- Курс «Intro to Computer Science» от Udacity.
- Курс «Поколение Python» от Stepik.
Сравнение возможностей и производительности систем
1. DLP система A
- Возможность контроля и защиты конфиденциальных данных в реальном времени;
- Анализ и фильтрация трафика сети;
- Отслеживание и блокировка пересылки конфиденциальных данных через электронную почту;
- Создание и применение политик безопасности для конкретных групп пользователей;
- Мониторинг и логирование всех активностей пользователей;
- Интеграция с существующими системами безопасности;
- Высокая производительность при обработке и анализе данных.
2. DLP система B
- Автоматическое нахождение и классификация конфиденциальных данных;
- Предотвращение утечки информации на локальных и удаленных устройствах;
- Блокировка нежелательных веб-сайтов и контента;
- Управление и защита сетевых сессий;
- Модульное расширение функциональности системы;
- Оптимизация использования системных ресурсов;
- Масштабируемость и высокая производительность при обработке больших объемов данных.
3. DLP система C
- Контроль и защита конфиденциальных данных на уровне файловой системы;
- Блокировка печати и копирования конфиденциальных документов;
- Механизмы криптографической защиты данных;
- Поддержка мультифакторной аутентификации и интеграция с Active Directory;
- Возможность создания отчетов и аналитики по активности пользователей;
- Централизованное управление и конфигурирование системы;
- Производительность при обнаружении и блокировке утечки данных.
Все три DLP системы обладают схожими основными возможностями, позволяющими обнаруживать и предотвращать утечку конфиденциальной информации. Однако, каждая система также имеет свои особенности и дополнительные функции, которые могут быть важны в определенных случаях.
При выборе DLP системы необходимо учитывать специфику бизнеса, требования к безопасности данных и возможности системы в интеграции с другими существующими системами.
Также важным фактором является производительность системы при обработке и анализе данных. Все три упомянутые DLP системы обладают высокой производительностью, что позволяет комфортно работать с большими объемами информации.
Окончательный выбор DLP системы должен основываться на анализе особенностей и требований конкретной организации, а также проведении тестирования и сравнении разных решений.
Aircrack-нг
Aircrack-ng — это мощный и комплексный инструмент для тестирования на проникновение в систему безопасности, используемый профессионалами в области цифровой безопасности для проверки безопасности беспроводных сетей. Инструмент позволяет пользователям собирать информацию, связанную с мониторингом пакетов, включая захват кадров и сбор WEP IV вместе с положением точек доступа, если добавлен GPS.
Он также может проводить тесты на проникновение в сети и анализировать производительность с помощью атак с использованием токенов, поддельных точек доступа и повторных атак. Наконец, он может выполнять взлом паролей как для WEP, так и для WPA PSK (WPA 1 и 2). Aircrack-ng представляет собой незаменимый инструмент для оценки потенциальных уязвимостей в беспроводной сети, прежде чем они могут быть потенциально использованы.
Универсальность этого инструмента является основным преимуществом; он был разработан в первую очередь для Linux, но может быть адаптирован и для других систем, таких как Windows, OS X и FreeBSD. Кроме того, его возможности в качестве интерфейса командной строки (CLI) дают ему преимущество в настройке. Это означает, что более продвинутые пользователи могут легко создавать пользовательские сценарии для дальнейшей модификации инструмента и адаптации его к своим уникальным требованиям.
Kdenlive — альтернатива Adobe Premiere с открытым исходным кодом
Kdenlive — альтернатива Adobe Premiere с открытым исходным кодом
KDenLive — это программное обеспечение для редактирования видео с открытым исходным кодом, которое предоставляет мощную и гибкую платформу для создания, редактирования и производства высококачественного видеоконтента. Он поддерживает широкий спектр форматов и включает расширенные функции, такие как многодорожечное редактирование, коррекция цвета и визуальные эффекты. Благодаря удобному интерфейсу и активному сообществу, KDenLive является отличным выбором как для любителей, так и для профессиональных видеоредакторов.
Kdenlive GitHub
История получения звезд Kdenlive GitHub
RATH — альтернатива Tableau с открытым исходным кодом
Kanaries(k6s) RATH: альтернатива Tableau с открытым исходным кодом
RATH, будучи новичком, также имеет одно из самых быстрорастущих сообществ на GitHub. Благодаря передовым технологиям и новаторскому подходу к анализу и визуализации данных, RATH быстро завоевала популярность среди профессионалов по работе с данными.
История получения звезд RATH на GitHub
Сообщество RATH быстро растет: разработчики, специалисты по данным и бизнес-аналитики вносят свой вклад в его развитие и делятся идеями о том, как максимально использовать его потенциал. Независимо от того, являетесь ли вы опытным аналитиком данных или только начинаете, RATH является обязательным инструментом для всех, кто хочет улучшить свои навыки анализа и визуализации данных.
- Kanaries(k6s) RATH GitHub
- Больше информации о RATH: https://kanaries.net/
Качество данных
Теперь, когда вы узнали больше о своих данных и очистили их, пришло время убедиться, что качество ваших данных находится на должном уровне. С помощью этих инструментов анализа данных вы можете определить, являются ли ваши данные точными, непротиворечивыми и надёжными. Высококачественные данные необходимы для принятия обоснованных решений, а также для эффективной работы систем и процессов, которые на них полагаются. Поддержание высокого качества данных имеет решающее значение для организаций, чтобы избежать негативного воздействия на процесс принятия решений и бизнес-операции.
Cleanlab
GitHub | Website
Cleanlab сфокусирована на ИИ, ориентированный на данные (DCAI), предоставляя алгоритмы / интерфейсы, помогающие компаниям (во всех отраслях) улучшать качество своих наборов данных и диагностировать / устранять различные проблемы в них. Cleanlab автоматически обнаруживает проблемы в наборе данных ML. Этот пакет искусственного интеллекта, ориентированный на данные, облегчает машинное обучение с использованием беспорядочных реальных данных, предоставляя чёткие метки для надёжного обучения и помечая ошибки в ваших данных.
Главный научный сотрудник и соучредитель Cleanlab, Йонас Мюллер, представит больше об инструменте на конференции ODSC East, которая состоится в мае этого года, на сессии под названием “Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI”.

Great Expectations
GitHub | Website
Great Expectations (GX) помогает группам обработки данных сформировать общее понимание своих данных с помощью качественного тестирования, документации и профилирования. Возлагая большие надежды, специалисты по обработке данных могут выразить то, чего они “ожидают” от своих данных, используя простые утверждения. Great Expectations обеспечивает поддержку различных серверных частей данных, таких как форматы файлов, базы данных SQL, фреймы данных Pandas и Sparks, а также поставляется со встроенной функцией уведомления и документирования данных.









![Top 10 open source big data tools in 2020 [updated] - whizlabs blog](https://triathlon21.ru/wp-content/uploads/5/6/c/56caba79b988e900a6b2d262d8b696c9.png)
Sam Bail, технический руководитель компании Superconductive (основные разработчики, на которых возлагаются большие надежды), выступил с докладом о создании надёжного конвейера передачи данных во время ODSC East 2021.
VisiData
GitHub | Website
VisiData – это бесплатный инструмент с открытым исходным кодом, который позволяет вам быстро открывать, изучать, обобщать и анализировать наборы данных в терминале вашего компьютера. VisiData работает с CSV-файлами, электронными таблицами Excel, базами данных SQL и многими другими источниками данных. Он сочетает в себе чёткость электронной таблицы, эффективность терминала и мощь Python в виде лёгкой утилиты, которая может с лёгкостью обрабатывать миллионы строк.
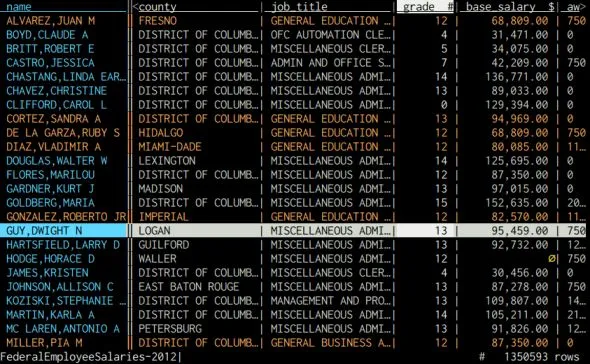
Типы инструментов ETL
Растущий спрос на эффективное управление данными, а также увеличение объема, разнообразия и скорости данных привели к взрывному росту количества инструментов ETL, в том числе:
Инструменты ETL с открытым исходным кодом
Когда инструменты ETL стали широко распространены, многие разработчики выпустили инструменты с открытым исходным кодом, которые можно использовать бесплатно. Вы можете легко получить доступ к их исходному коду и расширить его функциональность в соответствии с вашими требованиями к данным. Хотя инструменты ETL с открытым исходным кодом являются гибкими, им приходится долго учиться. Более того, они могут быть несовместимы с существующими конвейерами данных.
Пользовательские инструменты ETL
Многие компании разрабатывают свои инструменты ETL, используя такие языки программирования, как Python и SQL. Хотя они обеспечивают более широкие возможности настройки для удовлетворения конкретных требований к данным, создание этих инструментов требует много времени и значительных инвестиций и ресурсов. Более того, сложно поддерживать специальные инструменты ETL и обновлять их с учетом меняющихся требований к управлению данными.
Облачные инструменты ETL
Облачные инструменты ETL позволяют управлять данными из различных облачных приложений. Эти решения развертываются в облаке для обработки больших объемов данных без инвестиций в дополнительную инфраструктуру. Эти инструменты ETL просты в настройке и использовании, но им не хватает технических функций для выполнения сложных процессов ETL.
Корпоративные инструменты ETL
Инструменты Enterprise ETL — это специализированные решения для крупных организаций, позволяющие эффективно выполнять процессы ETL. Вы можете получать данные из разрозненных источников в централизованное хранилище данных для отчетности и аналитики. Эти решения обладают расширенными возможностями для выполнения сложных преобразований данных и обработки данных в любом масштабе.
Многие поставщики взимают ежегодную лицензионную плату или используют модель оплаты по мере использования. Лучшие поставщики предлагают обширное обучение и ресурсы. Эти корпоративные ETL-инструменты очень просты в использовании, особенно решения без программирования, которые позволяют бизнес-пользователям без опыта программирования управлять данными.
OSINT Framework

OSINT Framework — отличный ресурс для сбора информации с открытым исходным кодом. В нем есть все, от источников данных до полезных ссылок на эффективные инструменты, что значительно упрощает поиск по отдельности каждой программы и инструмента.
Этот каталог также предоставляет варианты для операционных систем помимо Linux, предоставляя решения по всем направлениям. Единственной проблемой может быть разработка эффективной стратегии поиска, которая сужает результаты, такие как регистрация автомобиля или адреса электронной почты, но с такими организованными ресурсами это становится большим преимуществом, чем когда-либо.
OSINT Framework быстро становится одним из самых популярных решений для сбора данных, поиска информации и сортировки вещей.
Shodan
Shodan — это продвинутая поисковая система, которая позволяет пользователям быстро идентифицировать и получать доступ к информации о технологиях, используемых в любом бизнесе. Введя название компании, можно получить подробные сведения об их устройствах IoT, такие как местоположение, сведения о конфигурации и уязвимости, сгруппированные по сети или IP-адресу.
Кроме того, работодатели могут использовать Shodan для дальнейшего анализа используемых операционных систем; открытые порты; тип веб-сервера и язык дизайна, используемый с высокой точностью, достигаемой благодаря передовым наборам программных инструментов.
Types of ETL Tools
There are several types of ETL tools, including:
- Enterprise ETL Tools: Enterprise ETL tools are used by large organizations that handle a much larger volume of data from multiple sources. These tools have unique features that can handle complex data transformations and automate the ETL process.
- Open-source/Free ETL Tools: Open-source ETL tools are freely available and accessible tools that can be used and tailored for specific requirements. The source code of such tools is publicly accessible, and data analysts can analyze and modify the tool to enhance their ETL process.
- Custom ETL Tools: Custom ETL tools are tailored to an organization’s needs and crafted using general-purpose programming languages such as Python, SQL, and Java, along with technologies like Kafka, Hadoop, and Spark. While offering flexibility, they demand substantial effort, involving the manual creation of data pipelines. Organizations using custom ETL tools are responsible for maintenance, documentation, testing, and ongoing development.
- ETL Cloud Services: Cloud ETL services empower organizations to swiftly and effectively execute ETL operations within a cloud computing environment. Certain ETL cloud services are proprietary and exclusive to the respective cloud vendor’s framework, making them incompatible with other cloud platforms.
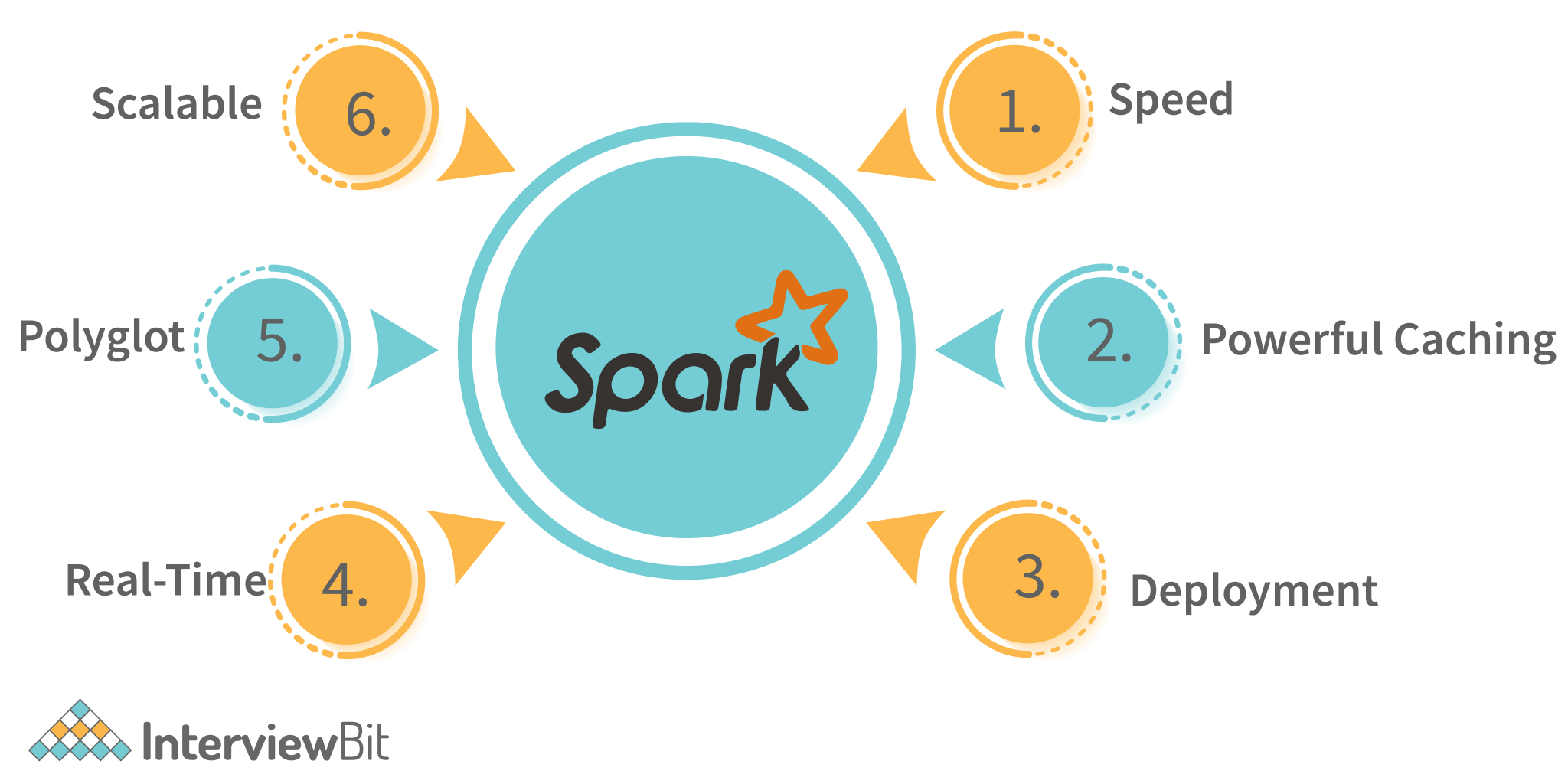
Spark. Is it still that powerful tool it used to be?
Our list of the best Big Data frameworks is continued with Apache Spark. It’s an open-source framework, created as a more advanced solution, compared to Apache Hadoop. The initial framework was explicitly built for working with Big Data. The main difference between these two solutions is a data retrieval model.

Apache Spark — Computerphile
Hadoop saves data on the hard drive along with each step of the MapReduce algorithm. While Spark implements all operations, using the random-access memory. Due to this, Spark shows a speedy performance, and it allows to process massive data flows. The functional pillars and main features of Spark are high performance and fail-safety.
It supports four languages:
- Scala;
- Java;
- Python;
- R.
It has five components: the core and four libraries that optimize interaction with Big Data. Spark SQL is one of the four dedicated framework libraries that is used for structured data processing. Using DataFrames and solving of Hadoop Hive requests up to 100 times faster.
Spark has one of the best AI implementation in the industry with Sparkling Water 2.3.0. Spark also features Streaming tool for the processing of the thread-specific data in real-time. In reality, this tool is more of a micro-batch processor rather than a stream processor, and benchmarks prove as much.
Fastest Batch processor or the most voluminous stream processor?
Well, neither, or both. Spark behaves more like a fast batch processor rather than an actual stream processor like Flink, Heron or Samza. And that is OK if you need stream-like functionality in a batch processor. Or if you need a high throughput slowish stream processor. It’s a matter of perspective.
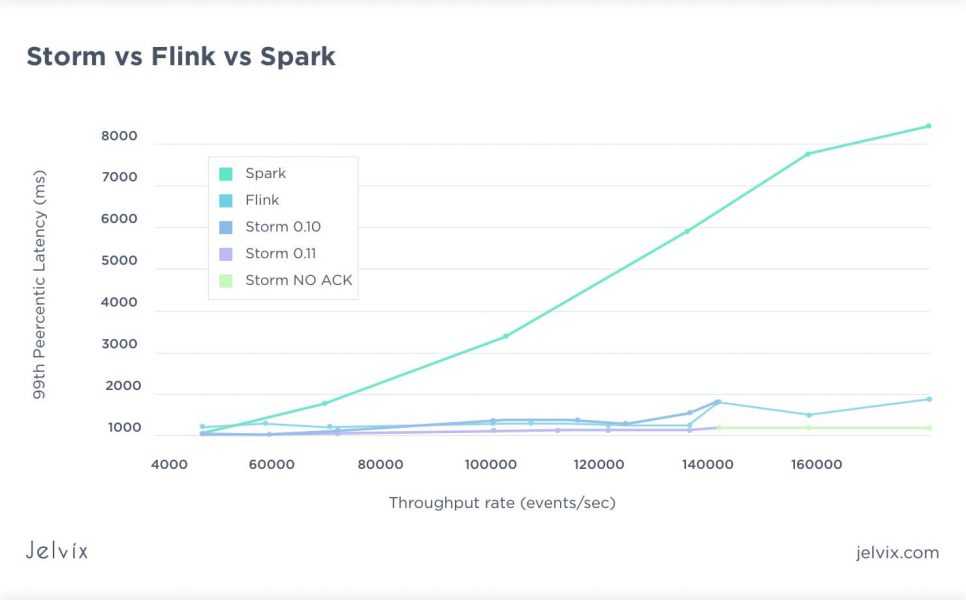
Spark founders state that an average time of processing each micro-batch takes only 0,5 seconds. Next, there is MLib — a distributed machine learning system that is nine times faster than the Apache Mahout library. Also, the last library is GraphX, used for scalable processing of graph data.
![Top 10 hadoop tools to make your big data journey easy [2024] | upgrad blog](https://triathlon21.ru/wp-content/uploads/3/8/f/38f701c94a80580c284a32d8d37b7729.jpeg)






Spark is often considered as a real-time alternative to Hadoop. It can be, but as with all components in the Hadoop ecosystem, it can be used together with Hadoop and other prominent Big Data Frameworks.
Apache Cassandra
Apache Cassandra is one NoSQL database that is written in java. It was originally developed by Facebook to handle their inbox search feature. Cassandra database does not need the matching of a column with a row. Apache Cassandra provides high availability and is consistent. Cassandra has a decentralized structure where any node can respond to requests, thus enabling it to avoid single node failure.
Some of the features and advantages of Apache Cassandra are:
- Apache works with a wide column store.
- AP on CAP
- Cassandra performs fast reads and writes.
- No multiple secondary indexes are required in Apache Cassandra
Apache Cassandra’s disadvantages:
- When the architecture is distributed, replicas may become inconsistent.
- When scanning day, it suffers when the primary key is not known.
- Another drawback of Cassandra is the aggregation. They must be provided by the clients.
Hive. Big data analytics framework.
Apache Hive was created by Facebook to combine the scalability of one of the most popular Big Data frameworks. It is an engine that turns SQL-requests into chains of MapReduce tasks.
The engine includes such components as:
- Parser (that sorts the incoming SQL-requests);
- Optimizer (that optimizes the requests for more efficiency);
- Executor (that launches tasks in the MapReduce framework).
Hive can be integrated with Hadoop (as a server part) for the analysis of large data volumes. Here is a benchmark showing Hive on Tez speed performance against the competition (lower is better).
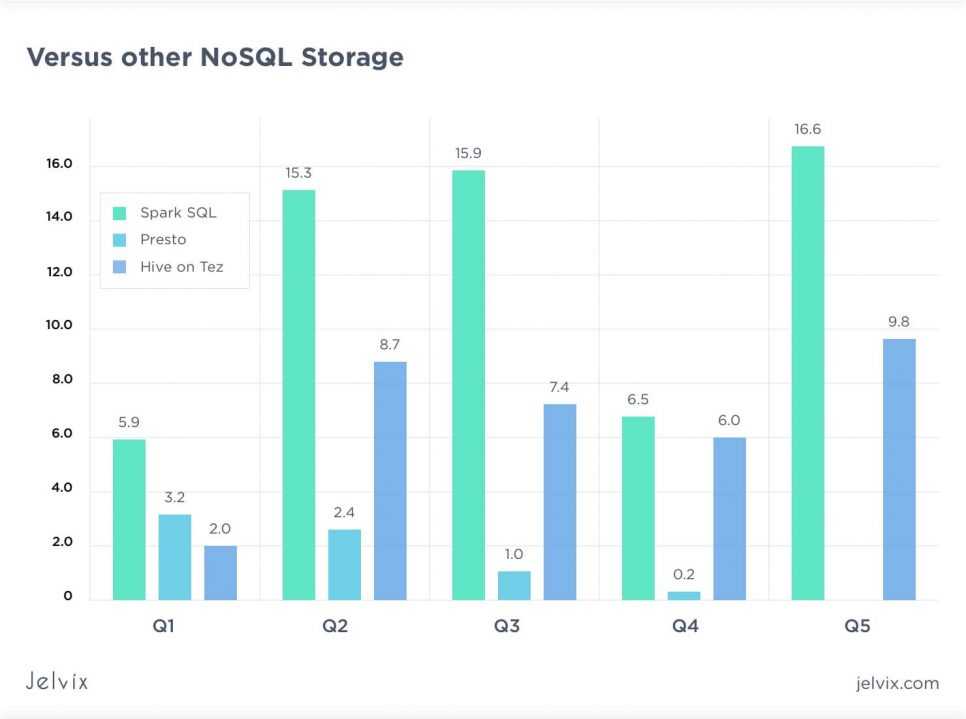
Hive remains one of the most used Big data analytics frameworks ten years after the initial release.
Hive 3 was released by Hortonworks in 2018. It switched MapReduce for Tez as a search engine. It has machine-learning capabilities and integration with other popular Big Data frameworks. You can read our article to find out more about machine learning services.
However, some worry about the project’s future after the recent Hortonworks and Cloudera merger. Hive’s main competitor Apache Impala is distributed by Cloudera.