
14.1.1. Ограничения реляционной модели данных. Не первая нормальная форма
Одним из наиболее важных принципов реляционной модели данных является
нормализация. Однако использование первой нормальной формы (1НФ) накладывает
ограничение атомарности на допустимые значения атрибутов (все используемые домены
отношения должны содержать только скалярные значения). Это снижает выразительность
реляционной модели данных при описании целого ряда предметных областей.
Наиболее часто такая проблема возникает, когда атрибут должен содержать множественные
значения или требуется внутренняя структура данных атрибута.
Таким образом, в ряде случаев нормализованная
реляционная модель предметной области несколько искусственна. Кроме того, нормализация в таких случаях заставляет разрабатывать
довольно сложные запросы для получения, казалось бы, простых данных.
В ряде случаев возможные значения
атрибута имеют внутреннюю структуру. Например, дата рождения, номер учебной
группы студента. Правила нормализации реляционной модели данных требуют
декомпозиции такого сложного (составного) атрибута на несколько простых
(атомарных). Это не всегда удобно и наглядно.
Для преодоления такого рода
недостатков реляционной модели данных была разработана постреляционная (post-relational) модель данных. Создание такой модели данных, допускающей не атомарность
значений атрибутов кортежей потребовало разработки новых правил нормализации.
Основой нормализации в постреляционной модели данных служит так называемая «не
первая нормальная форма» – НФ2 (NonFirstNormalForm – NF2). Суть заключается в расширенной трактовке понятия «атрибут». В
постреляционной модели атрибут может быть или атомарным (как в реляционной
модели), или множественным. Множественный атрибут описывается вложенным
отношением (множеством кортежей) со всеми вытекающими последствиями. Вообще
говоря, атрибуты такого вложенного отношения также могут быть множественными.
Это допущение не нарушает принципов реляционной алгебры.
Для манипулирования структурой и
данными в постреляционных СУБД производители создают расширения языка SQL. Стандарта такого расширения не существует, а в каждой постреляционной
СУБД используется свой синтаксис. Однако в любом случае множественные атрибуты
представлены либо как вложенные таблицы, либо как массивы данных (одномерные
или многомерные).
Разделите данные для получения двух подмножеств данных
Обучения модели недостаточно, чтобы утверждать, что у нас есть хорошая модель. Нам также необходимо оценить это с помощью метрики точности или ошибки для отдельного подмножества данных. В переводе нам нужно создать пару неперекрывающихся подмножеств – обучающий набор и тестовый набор – случайным образом извлеченные из исходного набора данных. Для этого мы используем узел Partitioning . Узел разделения случайным образом извлекает данные из таблицы входных данных в пропорции, указанной в его окне конфигурации, и создает два подмножества данных на двух выходных портах.
Обучающий набор будет использоваться для обучения модели узлом Logistic Regression Learner, а тестовый набор – для оценки модели узлом Logistic Regression Predictor, за которым следует узел Scorer. Узел Logistic Regression Predictor генерирует прогнозы оттока, а узел Scorer оценивает, насколько верны эти прогнозы.
Здесь мы не включаем операцию разделения среди операций подготовки данных, потому что она на самом деле не меняет данные. Однако это только наше мнение. Если вы хотите включить секционирование в операции подготовки данных, просто измените заголовок с «Четыре» на «Пять основных шагов в подготовке данных»
Что такое модель данных
В разных областях хозяйственной деятельности применяют информацию в том или ином формате. Все данные хранят в специальных банках и прочих системах, адаптированных под актуальные потребности современных предприятий и организаций. По мере увеличения объема хранимых и обрабатываемых информационных сведений требования к эффективности хранилищ растут, что сопровождается формированием запросов на инновационные и гибкие подходы к разработке инструментов управления данными.
По озвученным причинам важно осваивать принципы построения новых информационных систем, результативного использования технологий и программного обеспечения. Под базой данных понимают набор сведений, организованных тем или иным способом, размещаемых в памяти вычислительных систем и представляющих состояние объектов, связей между ними в изучаемой предметной области
Данные, помещенные в хранилище, структурированы. Такая логичная структура представляет собой модель данных.
Моделью данных называют средство абстракции для отображения обобщенной информационной структуры, состоящей из хранимых данных, без конкретизации их значений.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут
Возможности моделирования данных
Смоделированные данные можно использовать для проверки и тестирования сложных систем перед применением их к подлинным данным, так как они являются полными и редко имеют какие-либо пробелы или несоответствия.
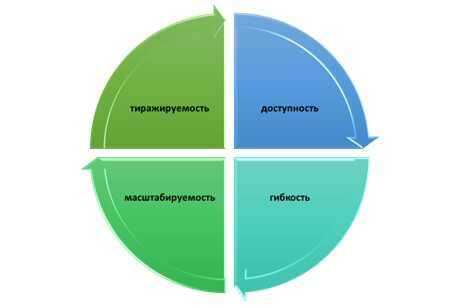
Моделирование данных привлекательно для многих команд, которые работают с данными по нескольким причинам:
- доступность
- гибкость
- масштабируемость
- тиражируемость
Доступность
Доступность данных достигается за счет использования понятных и общепринятых форматов данных, а также предоставления информации в удобном для восприятия виде.
Гибкость
Поскольку данные производятся, их можно корректировать для моделирования широкого спектра сценариев и условий без этических ограничений, что позволяет более глубоко изучить систему. Это особенно полезно при тестировании крупномасштабных имитационных и прогнозных моделей. Это также полезно при визуализации сложных данных, позволяя проверить точность в экстремальных ситуациях.
Масштабируемость
Помимо качества данных, объем данных играет решающую роль в обучении моделей машинного обучения и искусственного интеллекта. Масштабируемость смоделированных данных повышает их ценность для таких случаев использования: поскольку данные являются искусственными, их можно генерировать по мере необходимости, чтобы отразить случайность и сложность реальных систем.
Воспроизводимость
Подобные обстоятельства и условия могут быть воспроизведены в другом моделируемом наборе данных, чтобы обеспечить согласованность тестирования. Такая последовательность имеет решающее значение для проверки моделей и гипотез, поскольку позволяет многократно тестировать их и уточнять на основе результатов.
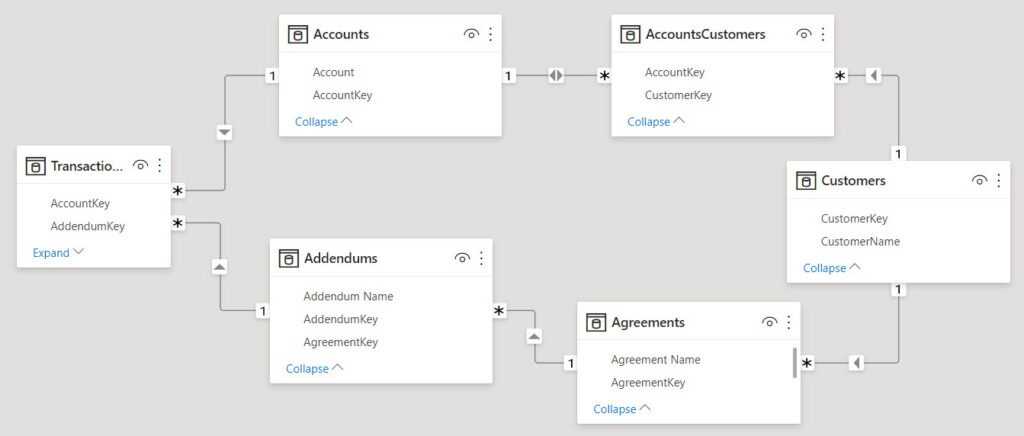
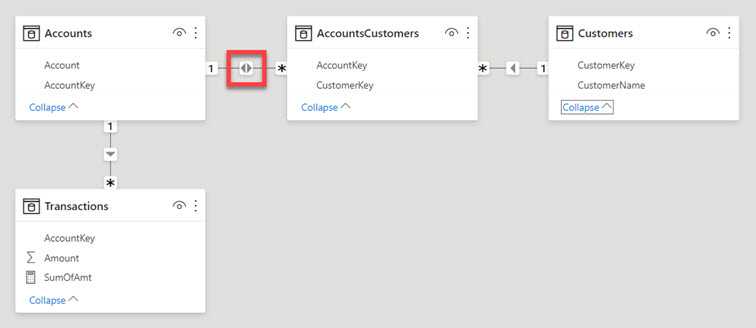
14.2.3. Пример структуры ОО базы данных
Ниже приведен пример ОО модели для задачи «Сессия». Для простоты модель
описывается только диаграммой классов.
ОО модель для задачи «Сессия» на уровне анализа приведена на слайде
11. Основными классами являются: Преподаватель, Дисциплина, Студент. К
связи Преподаватель – Дисциплина прикреплен класс-ассоциация «Читает», а к
связи Дисциплина – Студент прикреплен класс-ассоциация «Оценка». Эти классы
позволяют отразить семантику связей, а при необходимости описать атрибуты
связей.
На уровне проектирования ОО модель для задачи «Сессия» приведена на слайде
12. Классы Преподаватель и Студент являются наследниками более общего
родительского класса Персона, в котором описаны общие атрибуты (фамилия, имя,
отчество и т.д.). Связь Преподаватель – Дисциплина реализована с помощью класса
«Дисциплина в плане». Этот класс является наследником родительского класса
«Дисциплина». Связь Студент – Дисциплина реализована с помощью класса «Запись
сводной ведомости».
ОО модель уровня реализации будет в значительной степени зависеть от
языка программирования и способов решения инженерных задач, которыми владеет
разработчик. Поэтому модель для этого уровня здесь не приводится.
FAQs
Q1. What is data modeling?
The process of creating a visual representation of either part of a system or the entire system to communicate connections between structures and data points using elements, texts, and symbols.
Q2. What are the types of data models?
There are three types of data models: dimensional, relational, and entity relational. These models follow three approaches: conceptual, logical, and physical. Other data models are also there; however, they are obsolete, such as network, hierarchical, object-oriented, and multi-value.
Q3. What are the types of data modeling techniques?
The following are the types of data modeling techniques: hierarchical, network, relational, object-oriented, entity-relationship, dimensional, and graph.
Q4. What is the data modeling process?
The first step in the data modeling process is identifying the use cases and logical data models. Then create a preliminary cost estimation. Identify the data access patterns and technical requirements. Create DynamoDB data model and queries. Validate the model and review the cost estimation.
Q5. How can AWS help with data modeling?
You can use Amazon RDS (relational database service) to implement relational data models, Amazon Neptune to implement graph data models, and AWS Amplify DataStore for faster and easier data modeling to build web and mobile applications.
Q6. What are data modeling concepts?
Data modeling concepts answer the question of WHAT the system contains. A conceptual model helps to organize, scope, and define business concepts and rules. These concepts are created by data architects and business stakeholders.
Q7. Why is data modeling important?
An organized and comprehensive data modeling is crucial to create a simplified, logical, and physical database. It is necessary to eliminate storage requirements and redundancy and enable efficient data retrieval.
Q8. What are the types of data modeling?
The predominant data modeling types are hierarchical, network, relational, and entity-relationship. These models help teams to manage data and convert them into valuable business information.
Q9. What are the three levels of data abstraction?
Three levels of data abstraction are physical or internal, logical or conceptual, and view or external. The lowest form is physical, and the highest is the view. On a logical level, the information is stored in the database in the form of tables.
Адекватность модели
Поскольку модель является выражением конечного ряда и только важнейших для
конкретного исследования аспектов сущности, то она не может быть абсолютно
идентичной моделируемому объекту. Кроме этого, реальный объект бесконечен для
познания. Поэтому нет смысла стремиться к бесконечной точности при построении
модели. Для выяснения необходимой степени адекватности обычно строят ряд
моделей, начиная с грубых, простых моделей и двигаясь ко все более сложным и
точным. Как только затраты на построение очередной модели начинают превышать
планируемую отдачу от модели, то уточнение модели прекращают. Первоначальные
шаги производятся в каком-либо существующем универсальном моделирующем пакете.
После одобрения модели под неё пишется специализированный пакет. Необходимость
в этом возникает в случае, если функционирование модели в универсальной среде
моделирования не удовлетворяет требованиям быстродействия (или каким-то другим).
В задачи данного курса входит изучение приёмов и способов, необходимых для
формализации, изучения и интерпретации систем.
Моделирование прикладная инженерная наука класса технологических.
Моделирование дисциплина, ставящая целью построение моделей и их
исследование посредством собственных универсальных методов, а также
специфических методов смежных с ней наук (математика, исследование операций,
программирование).
Предсказательная (предиктивная) модель
После изучения данных у вас есть вся необходимая информация для развития математической модели, которая кодирует отношения между данными. Эти модели полезны для понимания изучаемой системы и используются в двух направлениях.
Первое — предсказания о значениях данных, которые создает система. В этом случае речь идет о регрессионных моделях.
Второе — классификация новых продуктов. Это уже модели классификации или модели кластерного анализа. На самом деле, можно разделить модели в соответствии с типом результатов, к которым те приводят:
- Модели классификации: если полученный результат — качественная переменная.
- Регрессионные модели: если полученный результат числовой.
- Кластерные модели: если полученный результат описательный.
Простые методы генерации этих моделей включают такие техники:
- линейная регрессия,
- логистическая регрессия,
- классификация,
- дерево решений,
- метод k-ближайших соседей.
Но таких методов много, и у каждого есть свои характеристики, которые делают их подходящими для определенных типов данных и анализа. Каждый из них приводит к появлению определенной модели, а их выбор соответствует природе модели продукта.
Некоторые из методов будут предоставлять значения, относящиеся к реальной системе и их структурам. Они смогут объяснить некоторые характеристики изучаемой системы простым способом. Другие будут делать хорошие предсказания, но их структура будет оставаться «черным ящиком» с ограниченной способностью объяснить характеристики системы.
14.2.1. Основы объектно-ориентированного подхода
В последнее время при разработке автоматизированных информационных систем
широко применяется объектно-ориентированный (ОО) подход. В его основе лежит
предположение о том, что человек видит окружающий мир как множество объектов.
Поэтому такой подход должен быть наиболее близким разработчику, должен существенно
упростить анализ и проектирование систем.
Базовыми элементами ОО подхода служат понятия класса и объекта (слайд
7). Не вдаваясь в современные дискуссии, можно сказать, что класс – это
тип, а объект – это экземпляр типа. Класс описывает (данные) атрибуты объекта и
методы (процедуры) объекта для обращения к ним.
Базовыми механизмами ОО подхода являются (слайд 8):
1.Инкапсуляция
(encapsulation).
Объединение атрибутов и методов доступа к ним в одном объекте. Пользователю (в
широком смысле) предоставляется только спецификация объекта (описание класса),
а его реализация скрывается. В идеале, доступ атрибутам объекта – только через
его методы.
2.Наследование
(inheritance).
Наследования дочерним классом атрибутов и методов родительского класса.
Сопряжено с возможностью добавления собственных атрибутов и методов, а также с
модификацией некоторых унаследованных методов (определяется доступом). Бывает
единичное (не более одного родительского класса) и множественное (несколько
родительских классов).
3.Полиморфизм
(polymorphism).
Использование одного и того же имени метода для решения нескольких сходных
технических задач. Например, одноименная функция получения абсолютной величины
для целых и для вещественных чисел.
4.Абстракция
(abstraction). Спецификация методов класса на уровне вызова (без реализации).
Используется для объявления отдельных методов, которые должны быть реализованы
в дочерних классах, а также для создания интерфейсов (interface). Интерфейс это
– спецификация взаимодействия между объектами (поименованный перечень методов,
которые должны быть реализованы в объекте).
Существует три уровня ОО моделирования (слайд 9):
1)уровень
анализа;
2)уровень
проектирования;
3)уровень
реализации.
Модели, составленные для разных уровней, могут существенно отличаться
друг от друга. При построении ОО моделей нужно четко представлять, для какого
уровня она составляется. Смешивание уровней (вольное или невольное) существенно
затрудняет моделирование и часто приводит к проблемам концептуального плана.
На первом уровне моделирования описывается предметная область (в терминах
объектов). При этом допускается не описывать атрибуты и методы (или описывать
только наиболее существенные). Допускаются так называемые «классы-ассоциации».
На втором уровне – описывается способ решения задачи путем создания
автоматизированной информационной системы с помощью ОО подхода. Модель
разрабатывается без привязки к конкретному ОО языку программирования. При этом
необходимо описать все основные атрибуты и методы.
На третьем уровне – составляется спецификация автоматизированной
информационной системы с учетом конкретного ОО языка программирования. Описанию
подлежат все атрибуты и методы с указанием типов данных, программных
интерфейсов.
Наибольшее распространение получил язык ОО моделирования UML (UnifiedModelingLanguage). Он позволяет описывать ОО модель с
помощью диаграмм следующих видов (слайд 10):
–вариантов
использования (use-case);
–классов
(class);
–объектов
(object);
–взаимодействия
(interaction)
–последовательности
(sequence);
–кооперативных
(collaboration);
–пакетов
(package);
–состояний
(statechart);
–деятельностей
(activity);
–размещения
(deployment).
Каждая диаграмма использует свою нотацию. В общем случае ОО модель описывается
с помощью диаграмм нескольких видов (как минимум, одного; не обязательно всех).

Несколько примечательных скрытых вариативные дискриминативных моделей
Вариационный автоэнкодер
Вариационный автоэнкодер (VAE) — это генеративная модель, которая применяет априор к скрытым векторам, так что все они лежат на гауссовой плоскости или имеют гауссов профиль (предшествующий распределению представлений). Вместо того, чтобы наносить изображение на точку в пространстве, кодировщик VAE отображает изображение на все распределение (многомерное нормальное или гауссово распределение). Затем он произвольно выбирает точку из этого распределения для восстановления изображения. Это помогает ему узнать, как распределяются данные.
Сравнительное изображение — слева карта цифры 6, сопоставленная с одной точкой. А справа она отображается в распределение Гаусса.
На рисунке выше цифра 6 кодируется двумя способами:
- Слева цифра 6 соответствует одной точке (традиционный автокодировщик). Рассмотрим изображение, представленное столбцом чисел, где размер столбца равен измерению скрытого пространства.
- Справа цифра 6 отображается в распределение Гаусса,поскольку вы явно узнали о распределении.
Вы можете спросить, почему традиционные автоэнкодеры не генерируют новые образцы?
: представление скрытого пространства Autoencoder в данных MNIST
Это потому что:
Скрытое пространство в автоэнкодерах было нерегулярным и непостоянным. Было почти невозможно узнать, какую случайную точку выбрать и декодировать из скрытого пространства для создания реалистичного изображения, поскольку в кластерах было много пробелов. Если вы выбрали точку из разрыва и передали ее декодеру,он может дать произвольный вывод, не похожий ни на один класс.
Кроме того, распределение точек из скрытого пространства не определено должным образом, поскольку каждое изображение сопоставляется непосредственно с одной точкой
Принимая во внимание, что каждое изображение в VAE отображается на многомерное гауссово или нормальное распределение,неотъемлемое свойство которого — делать скрытые векторы непрерывными.
Введите изображение в кодировщик VAE. Он кодирует его в два отдельных вектора: среднее значение и логарифм дисперсии, соответствующие переменным скрытого пространства. Если вы возьмете случайную выборку из распределения и затем передадите ее декодеру, он восстановит изображение.
Обучив такую модель:
- Вы гарантируете, что представление скрытого пространства непрерывно.
- Изучите пул (100 пулов в случае VAE, который тренировался на 100 классах), чтобы они находились в четко определенном регионе.
В отличие от автоэнкодера, VAE не только гарантирует, что две близкие точки в скрытом пространстве дают одинаковые выходные данные,но также и то, что точка, выбранная отсюда, дает значимый результат.
Что делает вариационный автоэнкодер генеративной моделью? После обучения модели во время тестирования вы в основном избавляетесь от кодировщика и выбираете точку из нормального распределения. При прохождении через декодер генерируются разнообразные реалистичные изображения.
Вы все еще можете задаться вопросом, что мы оптимизируем в VAE? Хорошо, в отличие от традиционных автоэнкодеров, VAE оптимизирует потерю реконструкции (евклидову) плюс скрытую потерю (KL-дивергенцию). KL-дивергенция измеряет расхождение между парой распределений вероятностей. Скрытая потеря заставляет скрытое представление быть непрерывным и ограничивает пулы, полученные сетью, в одном регионе. Это гарантирует, что распределение, изученное вашей моделью, четко определено и похоже на нормальное распределение.
Чтобы подробнее узнать о вариационных автоэнкодерах, прочтите .
Генеративная состязательная сеть
- Хотя модель VAE использует как генеративную модель, так и модель вывода и изучает базовое распределение данных неконтролируемым образом, генерируемые ею изображения размыты. Генеративная состязательная сеть (GAN) дает четкие и лучше воспринимаемые изображения.
- В VAE оптимизирована нижняя вариационная оценка. В GAN такого предположения не существует. Фактически, GAN не имеют дело с какой-либо явной оценкой плотности вероятности.
Неспособность VAE генерировать четкие изображения означает, что модель не может узнать истинное апостериорное распределение, то есть P(x|z), где x — сгенерированная выборка, а z — скрытое пространственное представление должно быть близко к нормальному распределению.
В следующем посте мы подробно рассмотрим генеративную состязательную сеть и дадим вам интуитивное понимание архитектуры GAN, функции состязательных потерь и ее стратегии обучения. Вы также кодируете ванильный GAN для создания модных изображений в PyTorch и TensorFlow. Прочтите это!
Процесс моделирования данных
Моделирование данных начинается с договоренности о том, какие символы используются для представления данных, как размещаются модели и как передаются бизнес-требования. Это формализованный рабочий процесс, включающий ряд задач, которые должны выполняться итеративно. Сам процесс обычно выглядят так:
- Определите сущности. На этом этапе идентифицируем объекты, события или концепции, представленные в наборе данных, который необходимо смоделировать. Каждая сущность должна быть целостной и логически отделенной от всех остальных.
- Определите ключевые свойства каждой сущности. Каждый тип сущности можно отличить от всех остальных, поскольку он имеет одно или несколько уникальных свойств, называемых атрибутами. Например, сущность «клиент» может обладать такими атрибутами, как имя, фамилия, номер телефона и т.д. Сущность «адрес» может включать название и номер улицы, город, страну и почтовый индекс.
- Определите связи между сущностями. Самый ранний черновик модели данных будет определять характер отношений, которые каждая сущность имеет с другими. В приведенном выше примере каждый клиент «живет по» адресу. Если бы эта модель была расширена за счет включения сущности «заказы», каждый заказ также был бы отправлен на адрес. Эти отношения обычно документируются с помощью унифицированного языка моделирования (UML).
- Полностью сопоставьте атрибуты с сущностями. Это гарантирует, что модель отражает то, как бизнес будет использовать данные. Широко используются несколько формальных шаблонов (паттернов) моделирования данных. Объектно-ориентированные разработчики часто применяют шаблоны для анализа или шаблоны проектирования, в то время как заинтересованные стороны из других областей бизнеса могут обратиться к другим паттернам.
- Назначьте ключи по мере необходимости и определите степень нормализации. Нормализация — это метод организации моделей данных, в которых числовые идентификаторы (ключи) назначаются группам данных для установления связей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ можно связать как с его адресом, так и с историей заказов, без необходимости повторять эту информацию в таблице с именами клиентов. Нормализация помогает уменьшить объем дискового пространства, необходимого для базы данных, но может сказываться на производительности запросов.
- Завершите и проверьте модель данных. Моделирование данных — это итеративный процесс, который следует повторять и совершенствовать под потребности бизнеса.
Топ-5 проблем моделирования и управления данными
Ниже представлены самые большие проблемы, с которыми сталкиваются организации, пытающиеся управлять процессом моделирования:
1. Современные рабочие процессы моделирования требуют совместной работы, но компаниям все еще сложно обеспечить обмен данными моделирования и их прослеживаемость. Уведомления об обновлении или поступлении новых данных часто настраиваются вручную, а проверка носит формальный характер, что только усугубляет проблему.
2. Организация и мониторинг процессов моделирования нередко осуществляются с помощью неподходящих инструментов, например, электронных таблиц. Эти инструменты затрудняют сбор ценной информации, включая распределение задач между пользователями или группами пользователей, время выполнения задач и взаимосвязи между входом и выходом наборов данных, которые были использованы и/или произведены в ходе моделирования.
3. Отсутствие наглядности истории завершенных проектов и статуса текущих проектов. Зачастую организациям даже трудно найти ответственного за выполнение той или иной проектной задачи.
4. Отсутствие взаимосвязанности, что приводит к потере времени на поиск назначенных задач и препятствует синхронизации с другими системами и командами.
5. Отсутствие контекста из-за отсутствия прослеживаемости требований к проектированию. Это приводит к потере времени на обратное проектирование и воссоздание прошлой работы.
Для решения этих задач корпоративное решение для управления процессом моделирования должно объединять команды и эффективно осуществлять передачу данных, предоставляя возможности настройки уведомлений, а также организации рабочих процессов бизнес- и технического моделирования для обеспечения совместной работы. Ansys Minerva на базе платформы Aras представляет собой инструмент для централизованного управления данными численного моделирования (SPDM), позволяющий организациям планировать и контролировать деятельность и проекты. Он дает возможность повысить эффективность сотрудничества между командами и членами команд, а также поддерживает прослеживаемость связей между различными артефактами, участвующими в процессе моделирования.
Выбор модели
При выборе модели вы должны принять во внимание, интерпретируемость и простоту отладки, объем данных, ограничения на обучение и прогнозирование
- Интерпретируемость и простота отладки- Почему модель приняла решение, которое она приняла? Как исправить ошибки?
- Количество данных- Сколько данных у вас есть? Это изменится?
- Ограничения на обучение и прогнозирование- Это связано с вышеизложенным, сколько времени и ресурсов у вас есть для обучения и прогнозирования?
Чтобы решить эти проблемы, начните с простого. Современная модель может быть заманчивой для достижения. Но если для обучения требуется в 10 раз больше вычислительных ресурсов, а время прогнозирования в 5 раз больше, а показатель оценки увеличится на 2%, это может быть не лучшим выбором.
Линейные модели, такие как логистическая регрессия, обычно легче интерпретировать, они очень быстры для обучения и прогнозируются быстрее, чем более глубокие модели, такие как нейронные сети.
Но, скорее всего, ваши данные взяты из реального мира. Данные из реального мира не всегда линейны.

Что тогда?
Глубокие модели, такие как нейронные сети, обычно лучше всего работают с неструктурированными данными, такими как изображения, аудиофайлы и текст на естественном языке. Тем не менее, компромисс в том, что они обычно занимают больше времени на обучение, их сложнее отлаживать и время прогнозирования занимает больше времени. Но это не значит, что вы не должны их использовать.
Трансферное обучение — это подход, который использует преимущества глубоких моделей и линейных моделей. Это включает в себя взятие предварительно обученной глубокой модели и использование шаблонов, которые она изучила, в качестве входных данных для вашей линейной модели. Это значительно экономит время тренировки и позволяет вам экспериментировать быстрее.
Где я могу найти предварительно обученные модели?
А как насчет других видов моделей?
Для создания концепции концепции вряд ли вам когда-нибудь понадобится создать собственную модель машинного обучения. Люди уже написали код для них.
То, на чем вы будете сосредоточены, — это подготовка ваших входов и выходов таким образом, чтобы их можно было использовать с существующей моделью. Это означает, что ваши данные и метки должны быть строго определены и понимать, какую проблему вы пытаетесь решить.
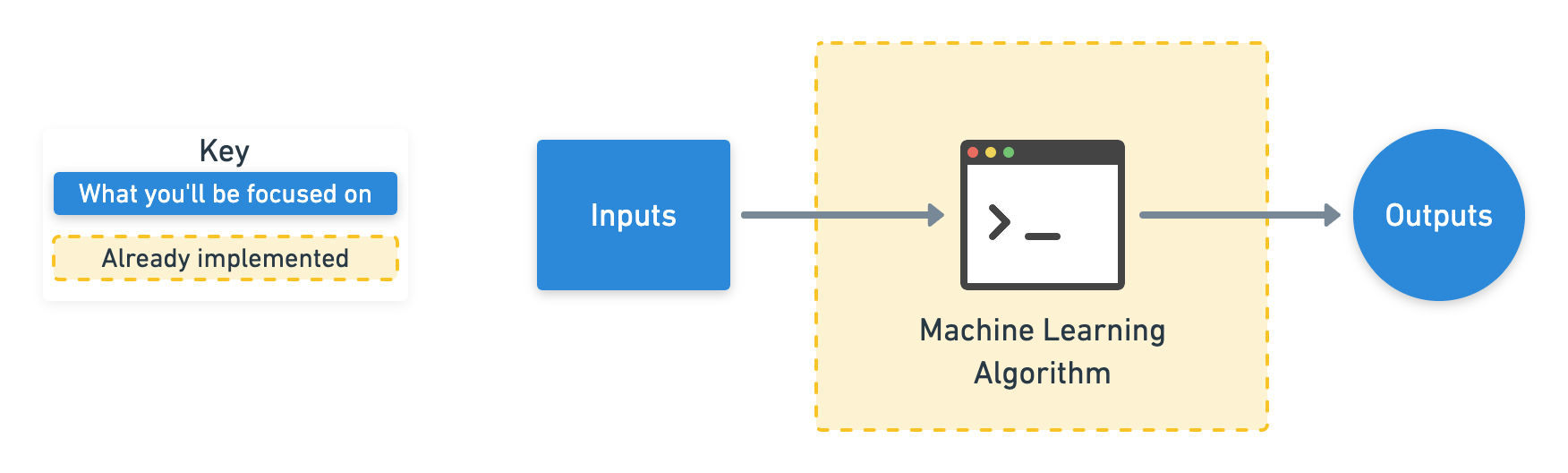 Начнем с того, что вашей основной работой будет обеспечение соответствия ваших входных данных (данных) тому, как их ожидает существующий алгоритм машинного обучения. Ваша следующая цель будет заключаться в том, чтобы результаты соответствовали определению вашей проблемы и соответствовали ли они вашей оценке.
Начнем с того, что вашей основной работой будет обеспечение соответствия ваших входных данных (данных) тому, как их ожидает существующий алгоритм машинного обучения. Ваша следующая цель будет заключаться в том, чтобы результаты соответствовали определению вашей проблемы и соответствовали ли они вашей оценке.
Заключение
- Моделирование данных — это процесс разработки модели данных для хранения данных в базе данных.
- Модели данных обеспечивают согласованность соглашений об именах, значений по умолчанию, семантики и безопасности, обеспечивая при этом качество данных.
- Структура модели данных помогает определить реляционные таблицы, первичные и внешние ключи и хранимые процедуры.
- Существует три типа: концептуальный, логический и физический.
- Основная цель концептуальной модели — установить сущности, их атрибуты и отношения.
- Логическая модель данных определяет структуру элементов данных и устанавливает связи между ними.
- Физическая модель данных описывает реализацию модели данных для конкретной базы данных.
- Основная цель проектирования модели данных — обеспечить точное представление объектов данных, предлагаемых функциональной группой.
- Самый большой недостаток заключается в том, что даже небольшие изменения в структуре требуют модификации всего приложения.
- Прочитав это руководство по моделированию данных, вы изучите основы concepts например, «Что такое модель данных?» Введение в различные типы моделей данных, преимущества, недостатки и пример модели данных.