

#2 Pytorch

Популярная библиотека, построенная на базе Torch, которая, в свою очередь, сделана на C и завернута в Lua. Изначально создавалась Facebook, но сейчас используется в Twitter, Salefsorce и многих других организациях.
Преимущества:
- Содержит инструменты и библиотеки компьютерного зрения, натуральной обработки речи, глубокого обучения и другого.
- Разработчики могут выполнять вычисления на тензорах с помощью ускорения GPU.
- Помогает создавать вычислительные диаграммы.
- Процесс моделирования простой и прозрачный.
- Стандартный режим «define-by-run» больше напоминает классическое программирование.
- Использует привычные инструменты отладки, такие как pdb, ipdb или отладчик PyCharm.
- Использует массу готовых моделей и модулей, которые можно комбинировать между собой.
Недостатки:
- Поскольку PyTorch относительно новый, не так много онлайн-ресурсов. Это усложняет процесс обучения с нуля, хотя он все равно достаточно интуитивный.
- Не настолько готов к полноценной работе в сравнении с TensorFlow.
Официальная документация: https://pytorch.org/.
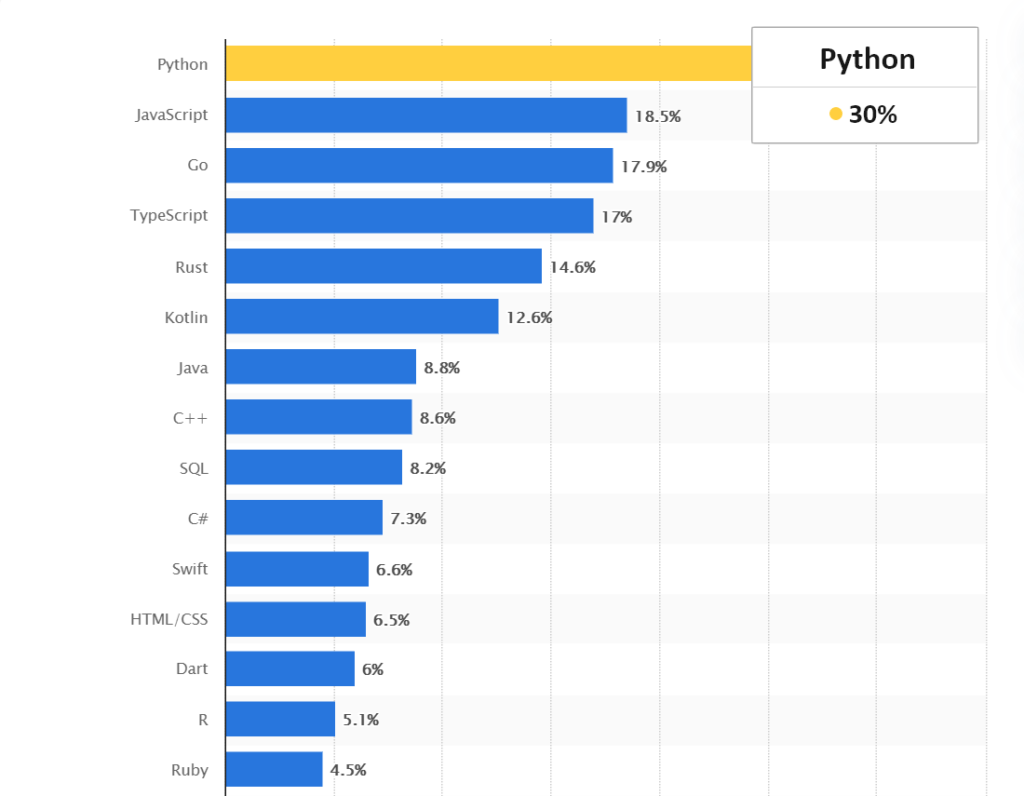
5 Библиотек Python для машинного обучения
1. NumPy
Представляет собой библиотеку общего назначения для обработки массивов. Имеет большой набор встроенных функциональных возможностей.
стандартный NumPy
результат
2. SciPy
SciPy — это усовершенствованный вариант NumPy. Если NumPy содержит функционал, предназначенный для базовых математических приложений, то SciPy беспроблемно работает даже с полиномами, подынтегральными функциями, различными преобразованиями, визуализацией данных и т. д.
SciPy для линейной алгебры, матриц и PnC
результат
3. Scikit-learn
Для разработки алгоритмов машинного обучения как нельзя лучше подходит библиотека Scikit-learn. Она помогает в предварительной обработке данных, создании модели и подгонки данных в ней. Здесь также имеются модули для прогнозирования, получения матрицы путаницы, точности модели и т. д.
SCIKIT-LEARN для предварительной обработки данных, подгонки модели и перекрёстной проверки
результат
4. Pandas
Пакеты Pandas содержат многочисленные инструменты для анализа данных, а также методы фильтрации данных. Здесь есть возможность считывать данные из различных форматов, таких как CSV, MS Excel и других.
Если данные в формате CSV, используется pandas.read_csv(“csv_filename.csv”). А если в формате Excel, то для удобного импортирования данных задействуется pandas.read_excel(“excel_filename.xlsx”).
Для хранения данных вPandas имеются две основные структуры данных:
1) Series. Подобно одномерному массиву, который хранит данные любого типа, здесь меняются значения, но не размер series.
2) DataFrame. Размер dataframe можно поменять. Здесь данные отображаются в формате строк и столбцов с дополнительным индексом.
структуры данных PANDAS: SERIES и DATAFRAME
первые два — это SERIES O/P, а третий O/P показывает DATAFRAME
5. Matplotlib
А эта библиотека используется для визуализации данных. Данные в matplotlib визуализируются в форматах точечных, столбчатых, круговых диаграмм, гистограмм, линейных графиков и т. д.
MATPLOTLIB
результат
Matplotlib имеет в своём арсенале базовые инструменты графического отображения. Широкое применение нашла и работающая поверх matplot библиотека Seaborn, предоставляющая интерфейс, благодаря которому диаграммы и графики выглядят более эстетичными и привлекательными.
Чтобы подробнее узнать о Seaborn и его приложениях, загляните сюда.
- Суперсила индексов для оптимизации SQL-запросов
- Большой недостаток социальных сетей и его устранение
- Разбор 7 ошибок Python
Читайте нас в Telegram, VK и
Перевод статьи Rashmi Dinesh Thekkath: PYTHON LIBRARIES FOR ML
What is a Python library?
Python libraries are collections of modules that contain useful codes and functions, eliminating the need to write them from scratch. There are tens of thousands of Python libraries that help machine learning developers, as well as professionals working in data science, data visualization, and more.
Python is the preferred language for machine learning because its syntax and commands are closely related to English, making it efficient and easy to learn. Compared with C++, R, Ruby, and Java, Python remains one of the simplest languages, enabling accessibility, versatility, and portability. It can operate on nearly any operating system or platform.
For an introduction to Python libraries Numpy, SciPy, Matplotlib, Seaborn, check out this video from the University of Michigan’s Statistics with Python specialization:
Conclusion
We’ve just scratched the surface of the world of Python machine-learning libraries. Though we’ve covered some incredibly versatile and powerful tools, countless others are waiting to be explored.
These libraries are not just useful but indispensable for data scientists, machine learning enthusiasts, and software engineers serious about building cutting-edge machine learning models.
As the field evolves, so too will this list. Your insights matter to us—so if you’ve experimented with a library that you think deserves a spot here, don’t hesitate to mention it in the comments. We intend to update this guide regularly, incorporating tried-and-true tools that we and the community find invaluable for data science projects.
Python Libraries for Natural Language Processing
23. NLTK
NLTK is one of the main platforms for constructing Python programs to parse human language data. It provides easy-to-use interfaces to more than 50 corpora and lexical resources like WordNet, as well as a suite of text processing libraries; it also offers wrappers for industrial-strength NLP libraries.
NLTK has been called “a wonderful tool for teaching, and working in, computational linguistics using Python”. The library is open-source and available for use under the Apache License 2.0.
To learn more about NLTK, check out their official documentation or read this NLTK tutorial for beginners.
GitHub Stars: 12.7K | Total Downloads: 264 million
24. spaCy
spaCy is an industrial-strength, open-source natural language processing library in Python. spaCy excels at large-scale information extraction tasks. It is written from the ground up in carefully memory-managed Cython. spaCy is the ideal library to use if your application needs to process massive web dumps.
Features:
- spaCy supports CPU and GPU processing.
- Offers support for 66+ languages
- Has 73 trained pipelines for 22 languages
- Multi-task learning with pre-trained transformers like BERT
- Pretrained word vectors
- State-of-the-art speed
- Production-ready training system
- Components for named entity recognition, part-of-speech tagging, dependency parsing, sentence segmentation, text classification, lemmatization, morphological analysis, entity linking and more
- Support for custom TensorFlow and PyTorch models
- Built-in visualizers for syntax and NER
- Easy model packaging, deployment, and workflow management
To learn more about spaCy, check out their official website or the GitHub repository. You can also familarize yourself with its functionalities quicky using this handy spaCY cheat sheet.
GitHub Stars: 28K | Total Downloads: 81 million
25. Gensim
Gensim is a Python library for topic modeling, document indexing, and similarity retrieval with large corpora. Its principle usership is in the information retrieval and natural language processing communities.
Features:
- All algorithms are memory independent so Gensim can process input larger than RAM.
- Intuitive interfaces
- It facilitates the implementation of commonly used algorithms, including Latent Dirichlet Allocation, Random Projections, online Latent Semantic Analysis, and word2vec deep learning.
- Distributed computing: it can run Latent Semantic Analysis and Latent Dirichlet Allocation on a cluster of computers.
To learn more about Gensim, check out their official website or the GitHub repository.
GitHub Stars: 14.9K | Total Downloads: 236 million
26. Hugging Face Transformers
Hugging Face Transformers is an open-source library by Hugging Face. Transformers allow APIs to easily download and train state-of-the-art pre-trained models. Using pre-trained models can reduce your compute costs, carbon footprint, and save you time from having to train a model from scratch. The models are suitable for a variety of modalities, including:
- Text: classifying text, extracting information, answering questions, translating, summarizing, and even generating text in more than 100 languages.
- Images: image classification, object detection, and segmentation.
- Audio: speech recognition and audio classification.
- Multimodal: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
The transformers’ library supports seamless integration between three of the most popular deep learning libraries: PyTorch, TensorFlow, and JAX. You can train your model in three lines of code in one framework, and load it for inference with another. The architecture of each transformer is defined within a standalone Python module, making them easily customizable for experiments and research.
The library is currently available for use under the Apache License 2.0.
To learn more about transformers, check out their official website or the GitHub repository and check out our tutorial on using Transformers and Hugging Face.
GitHub Stars: 119K | Total Downloads: 62 million
What Else are required?
on the other hand, Most of these Machine Learning Libraries are in Python. Therefore, I will suggest you take an overview of python. If you want to quickly revise or learn python essentials. You can refer to our article Learn Python essentials in 5 Minutes.
Still, If you have doubts in your mind why we should use python for data analysis. The article complete overview of python for data analysis will clear all your queries. In fact along with python, what other skills are required to become a full-stack Data Scientist are also mentioned in our article How to Become a Data Scientist – complete Guide.
Likewise Python, There are so many tremendous Machine Learning Libraries in java and other programming languages. Some of us call these Machine Learning library by the name of Machine Learning Framework. In General, both are similar but in deep context, there are so many differences. I will not speak much about it in this post except,” when the flow of control added with library then it becomes a framework “.






![7 лучших ии и систем машинного обучения с открытым исходным кодом [записки админа и инженера]](https://triathlon21.ru/wp-content/uploads/8/c/9/8c94e93ca2280dca9e73979645dbb6ad.png)


More Python Libraries for Machine Learning
As previously said, there are thousands of thousands of machine learning libraries. This means that there are other excellent Libraries besides those on the list. However, discussing them all would exceed the scope of this paper.
As a result, this section will go through some of the best machine learning libraries accessible. Here’s the rundown:
1. Numpy
Numpy is used to handle multidimensional data and complex mathematical functions. Numpy is a rapid computing package that can handle everything from fundamental algebra to Fourier transformations, random simulations, and shape manipulations. This library is developed in C, giving it an advantage over normal Python built-in sequencing. In terms of indexing, Numpy arrays outperform Pandas series, and Numpy performs better when the number of records is smaller than 50k.
To Learn More About Numpy: Numpy Tutorial in Hindi
2. Pandas
Pandas is a data manipulation tool for numerical and time series data. It defines three-dimensional and two-dimensional data using data frames and series, respectively. It also has tools for indexing vast amounts of data in order to do rapid searches across enormous datasets. It is well-known for its data reshaping capabilities, pivoting on user-defined axes, managing missing data, merging and connecting datasets, and data filtration features. Pandas are extremely handy and speedy for dealing with huge datasets. When the records are more than 50k, it beats the Numpy.
To Learn More About Pandas: LEARN PANDAS in about 10 minutes! A great python module for Data Science!
3. NetworkX
NetworkX is a Python package for graph and network analysis. It is intended for use in the real world, i.e., huge graphs. NetworkX is based on a Python-only “dictionary of dictionary” data structure. As a result, the machine learning library is an extremely fast, portable, and scalable solution for studying networks and social networks.
To Learn More About NetworkX: Introduction to NetworkX in Python
4. Shark
SHARK is a machine learning library that is both fast and modular. It provides a variety of ML approaches, including kernel-based learning algorithms, linear and nonlinear optimization, and neural networks. SHARK is a robust toolset for developing real-world ML-based applications as well as an outstanding ML library for academic purposes.
To Learn More About Shark: An Introduction into Machine Learning C++ Libraries: Envt Lib Characters of Shark| packtpub.com
5. Jblas
Jblas is a Java programming language cross-platform linear algebra library. It is based on BLAS and LAPACK. Since its first release in March 2009, the ML library has gained popularity in scientific computing. jblas includes precompiled binaries that are intended for use with native programs through the JNI (Java Native Interface). It is commonly seen in software packages such as JLabGroovy and UJMP (Universal Java Matrix Library).
To Learn More About Jblas: http://jblas.org/
6. DyNet

DyNet is a neural network library that creates a computational graph on the fly. This streamlines and improves the implementation of variable input and variable-output models. DyNet is optimized for networks with dynamic architecture that vary with each training instance. Despite being built in C++, the ML library has Python bindings.
To Learn More About DyNet: https://github.com/clab/dynet
Seaborn
Итак, когда вы читаете официальную документацию по Seaborn, она определяется как библиотека визуализации данных на основе Matplotlib, предоставляющем высокоуровневый интерфейс для изображения интересных и информативных статистических графиков. Проще говоря, seaborn — это расширение Matplotlib с дополнительными возможностями.
Так в чем разница между Matplotlib и Seaborn? Matplotlib используется для основного построения столбцовых, круговых, линейных, точечных диаграмм и пр., в то время как Seaborn предоставляет множество шаблонов визуализации с меньшим количеством синтаксических правил, причем более простых.
Что можно делать с помощью Seaborn?
1. Определять отношения между несколькими переменными (корреляция);
2. Соблюдать качественные переменные для агрегированных статистических данных;
3. Анализировать одномерные или двумерные распределения и сравнивать их между различными подмножествами данных;
4. Построить модели линейной регрессии для зависимых переменных;
5. Обеспечить многоуровневые абстракции, многосюжетные сетки.
Seaborn — это отличный вариант для библиотек визуализации R, таких как corrplot и ggplot.
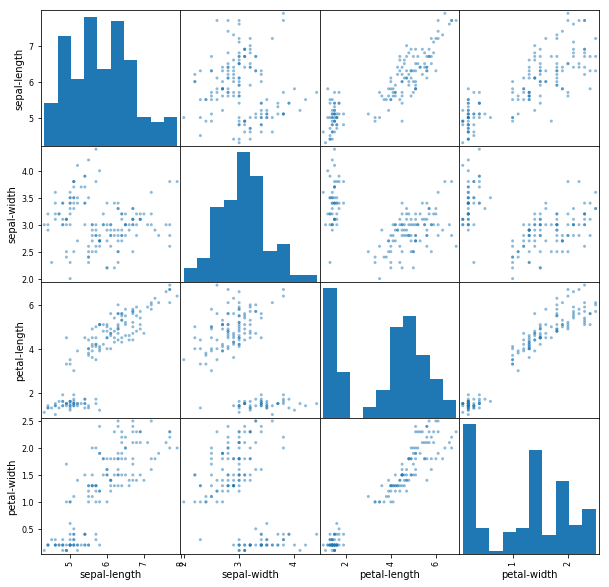
Top 25 Libraries You Need to Know
Now that you understand Python’s importance and versatility in the data science and machine learning landscapes, it’s time to dig deeper.
But with the vast number of libraries available, where do you start? Fear not because I’ve done the heavy lifting for you.
Whether you’re a novice dipping your toes into the machine learning pool or a seasoned data scientist searching for that perfect tool to optimize your workflow, I have something for everyone.
Below, I’ll walk you through 24 of Python’s most powerful machine-learning libraries, categorized by their core functionalities and applications.
Let’s dive in!
Note: This article was last updated on October 12, 2023.
Introduction
In today’s digital environment, artificial intelligence (AI) and machine learning (ML) are getting more and more popular. Because of their growing popularity, machine learning technologies and algorithms should be mastered by IT workers.
Specifically, Python machine learning libraries are what we are investigating today. We give individuals a head start on the new year by previewing the top libraries that ML experts will be utilizing in 2022.
Here is the list of top 15 Python Libraries For Machine Learning in 2022:
- TensorFlow
- Keras
- OpenCV
- Scikit-learn
- SciPy
- Matplotlib
- Seaborn
- NLTK
- PyTorch
- Theano
- PyCaret
- Caffe
- CNTK
- Fast.ai
- Nolearn
Scikit-Learn

Designed as an extension to the SciPy library, scikit-learn has become the de-facto standard for many of the machine learning tasks. Developed as part of Google Summer of Code project, it has now become a widely contributed open source project with over 1000 contributors.


Scikit-learn provides a simple yet powerful fit-transform and predict paradigm to learn from data, transform the data and finally predict. Using this interface, it provides capabilities to prepare classification, regression, clustering and ensemble models. It also provides a multitude of utilities for preprocessing, metrics, model evaluation techniques, etc. Official Link
Advantages
- The go-to package that has it all for classical Machine Learning algorithms
- Consistent and easy to understand interface of fit and transform
- Capability to prepare pipelines not only helps with rapid prototyping but also quick and reliable deployments
Downsides
- Inability to utilize categorical data for algorithms out of the box that support such data types (packages in R have such capabilities)
- Heavy reliance on the Scipy stack
6. XGBoost
XGBoost — это набор инструментов для распределенного повышения градиента, разработанный для обеспечения скорости, гибкости и портативности. Для разработки алгоритмов ML используется фреймворк Gradient Boosting. XGBoost — это быстрый и точный метод параллельного повышения дерева, который может решить широкий спектр задач науки о данных.
Используя структуру Gradient Boosting, эту библиотеку можно использовать для создания алгоритмов машинного обучения.
Он включает в себя параллельное повышение дерева, которое помогает командам решать различные проблемы науки о данных. Еще одно преимущество заключается в том, что разработчики могут использовать один и тот же код для Hadoop, SGE и MPI.
Он также надежен как в распределенных ситуациях, так и в ситуациях с ограниченной памятью.
Library #7. SciPy

Since SciPy is included in the eponymous stack, this library is also worth talking about a bit. This is an open-source library for scientific and engineering calculations. Among its capabilities, you can find the following mathematical and other operations: finding minimums and maxima of functions, calculating integrals, signal processing, image processing, and many others.







All of these useful features are supported by the following strengths:
- Good computing performance and speed. With this library, you can be sure that such complex calculations as numerical interpolation, integration, linear algebra, and many others will be performed extremely quickly, saving you time.
- User-friendly library. If you are looking to hire offshore developers who work with Python, you can be sure they all know this library. It is extremely easy to learn and very useful in developing machine learning algorithms.
- Enhanced calculations in synergy with NumPy. Since SciPy is based on the NumPy library, you can work with its datasets, thereby improving and speeding up computation operations.
Benefits of Learning Python for Non-Programmers
Learning machine learning with python holds numerous benefits for non-programmers, offering a gateway into the world of coding without overwhelming complexities. Whether you’re a student, professional, or hobbyist, machine learning modules user-friendly nature and versatility make it an ideal starting point for those new to programming.
Ease of Learning
Python’s syntax is designed to be clear and readable, resembling plain English. For non-programmers, this means a gentler learning curve. The simplicity of Python allows beginners to focus on understanding fundamental programming concepts without getting bogged down in convoluted syntax.
Versatility and Applicability
Python’s versatility extends across various domains, making it a valuable asset for non-programmers. From web development and data analysis to artificial intelligence and automation, Python finds applications in diverse fields. This adaptability ensures that learners can explore different areas of interest and tailor their programming journey according to their preferences.
Abundance of Resources
A vast and supportive community surrounds Python, providing an abundance of resources for learners. Numerous online tutorials, forums, and documentation make it easy for non-programmers to seek guidance and find solutions to challenges they may encounter. The wealth of resources fosters a collaborative learning environment, enhancing the overall learning experience.
Community and Collaboration
Python’s popularity has led to the formation of a vibrant and welcoming community. For non-programmers, this means access to a network of experienced developers willing to share knowledge and assist with problem-solving. Engaging with this community not only aids learning but also introduces individuals to the collaborative nature of programming.
Extensive Library Support
Python boasts an extensive collection of machine learning libraries and frameworks, simplifying complex tasks for non-programmers. These pre-built modules enable users to leverage powerful functionalities without delving into intricate code. This accessibility allows beginners to accomplish tasks efficiently, boosting confidence and motivation.
Applicability in Data Science and Analysis
For those interested in data science, Python’s popularity in this domain is a major advantage. Its libraries, such as NumPy and Pandas, provide robust tools for data manipulation and analysis. Non-programmers can easily grasp these tools, opening doors to opportunities in the rapidly growing field of data science.
Automation and Productivity
Learning Python introduces non-programmers to the world of automation. The language’s simplicity facilitates the creation of scripts to automate repetitive tasks, enhancing efficiency and productivity. This practical aspect is especially appealing to individuals seeking ways to streamline their workflows in various professional or personal settings.
Career Opportunities
Acquiring Python skills enhances non-programmers’ employability across industries. Many organizations value Python proficiency due to its widespread use and versatility. Learning Python provides individuals with a valuable skill set, making them competitive candidates in job markets where programming knowledge is increasingly in demand.
10. НЛТК
NLTK (Natural Language Toolkit) — популярный пакет Python для специалистов по данным. Пометка текста, токенизация, семантическое обоснование и другие задачи, связанные с обработкой естественного языка, могут выполняться с помощью NLTK.
NLTK также можно использовать для завершения более сложного ИИ (Artificial Intelligence) рабочие места. Первоначально NLTK был создан для поддержки различных парадигм обучения искусственному интеллекту и машинному обучению, таких как лингвистическая модель и когнитивная теория.

В настоящее время он управляет алгоритмом ИИ и разработкой модели обучения в реальном мире. Он получил широкое распространение в качестве учебного пособия и индивидуального учебного пособия, а также в качестве платформы для прототипирования и разработки исследовательских систем.
Поддерживаются классификация, синтаксический анализ, семантическое обоснование, выделение корней, теги и токенизация.
Анализ датасета
Теперь пришло время взглянуть на данные более детально. На этом этапе мы погрузимся в анализ данные несколькими способами:
- Размерность датасета
- Просмотр среза данных
- Статистическая сводка атрибутов
- Разбивка данных по атрибуту класса.
Не волнуйтесь, каждый взгляд на данные является одной командой. Это полезные команды, которые можно использовать снова и снова в будущих проектах.
3.1 Размерность датасета
Мы можем получить быстрое представление о том, сколько экземпляров (строк) и сколько атрибутов (столбцов) содержится в датасете с помощью метода shape.
Вы должны увидеть 150 экземпляров и 5 атрибутов:
3.2 Просмотр среза данных
Исследовании данных, стоит сразу в них заглянуть, для этого есть метод head()
Это должно вывести первые 20 строк датасета.
3.3 Статистическая сводка
Давайте взглянем теперь на статистическое резюме каждого атрибута. Статистическая сводка включает в себя количество экземпляров, их среднее, мин и макс значения, а также некоторые процентили.
Мы видим, что все численные значения имеют одинаковую шкалу (сантиметры) и аналогичные диапазоны от 0 до 8 сантиметров.
3.4 Распределение классов
Давайте теперь рассмотрим количество экземпляров (строк), которые принадлежат к каждому классу. Мы можем рассматривать это как абсолютный счет.
Мы видим, что каждый класс имеет одинаковое количество экземпляров (50 или 33% от датасета).
4. Визуализация данных
Теперь когда у нас есть базовое представление о данных, давайте расширим его с помощью визуализаций.
Мы рассмотрим два типа графиков:
- Одномерные (Univariate) графики, чтобы лучше понять каждый атрибут.
- Многомерные (Multivariate) графики, чтобы лучше понять взаимосвязь между атрибутами.
4.1 Одномерные графики
Начнем с некоторых одномерных графиков, то есть графики каждой отдельной переменной. Учитывая, что входные переменные являются числовыми, мы можем создавать диаграмма размаха (или «ящик с усами», по-английски «box and whiskers diagram») каждого из них.
Это дает нам более четкое представление о распределении атрибутов на входе.
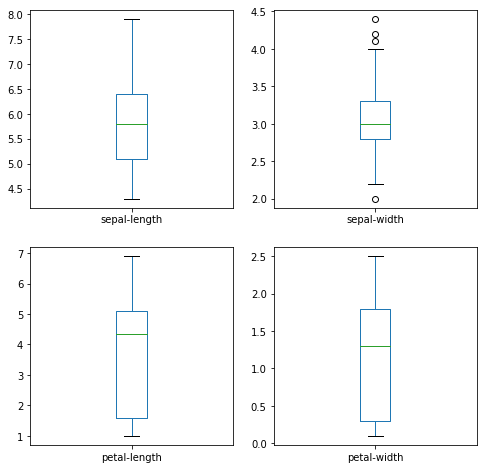 Диаграмма размаха атрибутов входных данных
Диаграмма размаха атрибутов входных данных
Мы также можем создать гистограмму входных данных каждой переменной, чтобы получить представление о распределении.
Из графиков видно, что две из входных переменных имеют около гауссово (нормальное) распределение. Это полезно отметить, поскольку мы можем использовать алгоритмы, которые могут использовать это предположение.
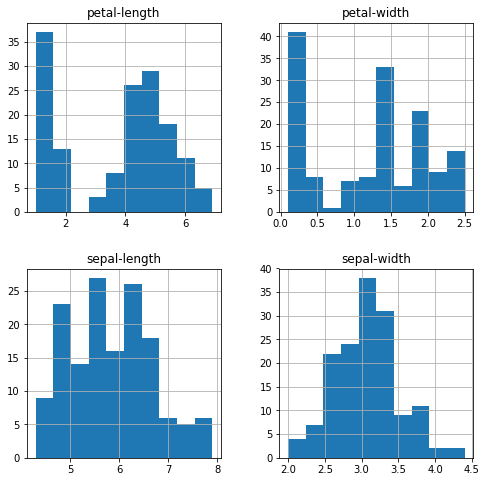 Гистограммы входных данных атрибутов датасета
Гистограммы входных данных атрибутов датасета
4.2 Многомерные графики
Теперь мы можем посмотреть на взаимодействия между переменными.
Во-первых, давайте посмотрим на диаграммы рассеяния всех пар атрибутов. Это может быть полезно для выявления структурированных взаимосвязей между входными переменными.


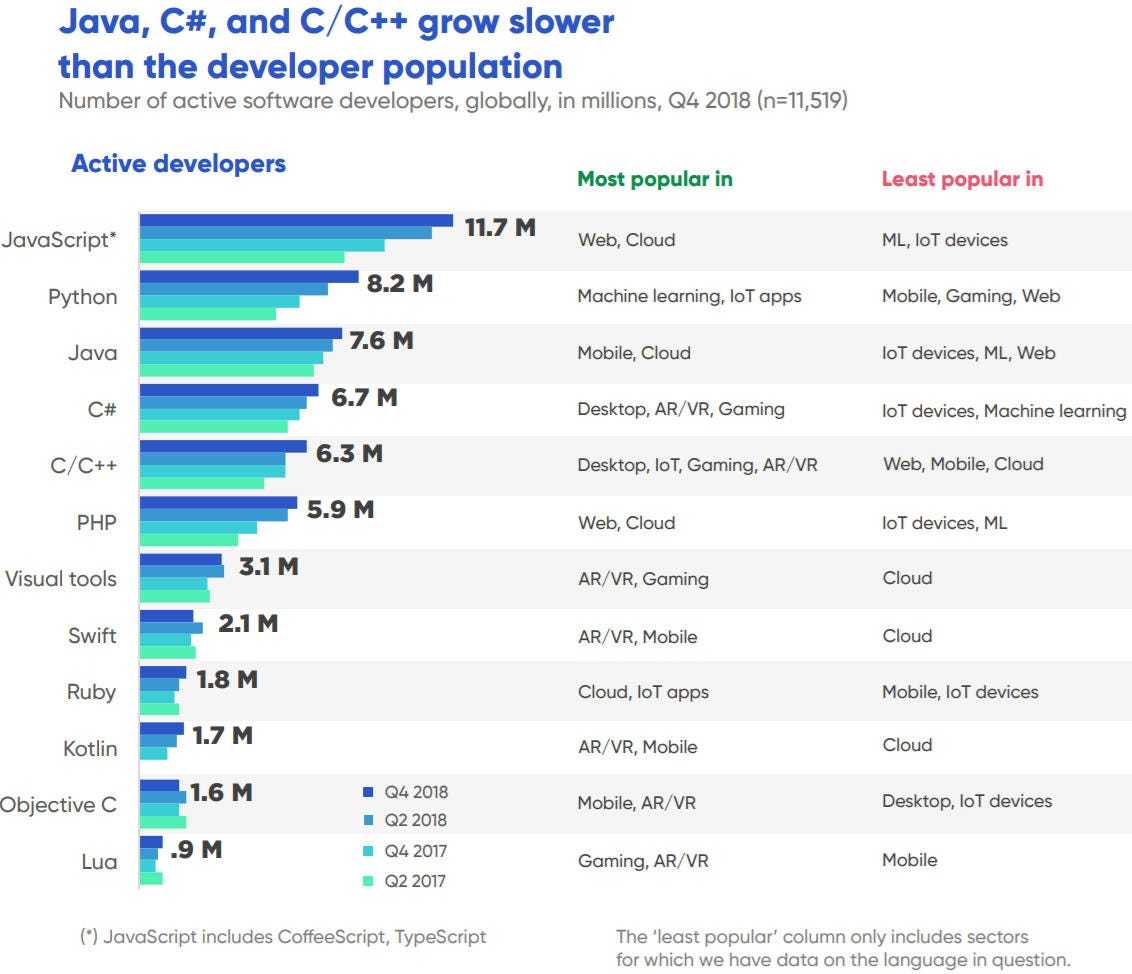


Обратите внимание на диагональ некоторых пар атрибутов. Это говорит о высокой корреляции и предсказуемой взаимосвязи
What is a machine learning library?
There is a common confusion between libraries and frameworks. So before we move on to introducing the top 15 machine learning libraries and their benefits, let’s explore the key distinction between libraries and frameworks.
Libraries provide specific functionalities, while frameworks offer a complete set of tools for developing a fully-fledged application. So when designing a software solution, you might use many libraries, but typically only one or a few frameworks.
A library is a collection of prewritten codes, predefined methods, and classes that programmers can use to simplify and accelerate development and solve a specific problem. It includes functions, class definitions, important constants, etc. As a result, you can skip writing code to achieve specific features.
Most programming languages include a standard library, but developers can create their own customized ones. Python has a large set of special-purpose libraries for scraping information, visualizing data, designing ML models, etc.
A framework is a package of code libraries, compilers, APIs, and other supporting programs that provides standard functionality for programmers to speed up the software development process. Frameworks give you a structure for building an app and often include pre-built code that can be used to accomplish common tasks or modified to better fit the needs of a specific project.
In this article, we give an overview of the most popular ML libraries written in Python and other programming languages. If you are not yet familiar with the process of using external libraries in Python, we recommend reading this step-by-step guide.
Now that we have clarified the definitions, it’s time to get to the list of top open-source ML libraries that we have compiled in collaboration with our AI experts.
Другие популярные языки программирования для программирования ИИ
Конечно, вы можете использовать другие языки для ИИ. Технически вы можете использовать любой язык для программирования ИИ — просто некоторые делают это проще, чем другие. Давайте взглянем на некоторые другие лучшие языки для ИИ.
1. Ява
- Плюсы: Java — популярный язык общего назначения с большим сообществом разработчиков. Он статически типизирован, что означает, что вы можете раньше отлавливать ошибки и быстрее запускать программы.
- Минусы: Java может быть многословным и имеет крутую кривую обучения. У него очень мало функций качества жизни; программистам придется делать довольно много вручную.
2. Julia
- Плюсы: Julia была разработана для высокопроизводительных численных вычислений и имеет надежную поддержку машинного обучения.
- Минусы: Julia — молодой язык и, следовательно, не имеет большой поддержки сообщества. Изучение этого языка может быть трудным.
3. Хаскелл
Плюсы: Haskell — это функциональный язык программирования, в котором особое внимание уделяется корректности кода. Его можно использовать для разработки ИИ, хотя чаще он используется в обучении и исследованиях.
Минусы: Haskell сложен в изучении
Это также может быть очень запутанным, так как язык очень нишевый.
4. Лисп
- Плюсы: Lisp уже много лет используется для ИИ. Он известен своей гибкостью и символическим, логически ориентированным подходом.
- Минусы: Lisp может быть трудно читать и писать. У него также есть небольшое сообщество разработчиков.
5. Р
- Плюсы: R — популярный статистический язык программирования среди специалистов по данным. Он хорошо интегрируется с другими языками и имеет множество доступных пакетов. Он отлично подходит для ИИ с надежными потребностями в обработке данных.
- Минусы: R может быть медленным и имеет крутую кривую обучения. Это также не очень хорошо поддерживается.
6. JavaScript
- Плюсы: JavaScript — популярный язык для веб-разработки. Разработчики используют JavaScript в библиотеках машинного обучения, таких как TensorFlow.js .
- Минусы: JavaScript сложнее и сложнее в изучении, чем Python. Он надежен и имеет так много опций, что может запутать не-разработчиков.
7. С++
- Плюсы: C++ — быстрый и мощный язык, популярный среди разработчиков игр. Он хорошо продуман и хорошо задокументирован, и его можно использовать для самых разных целей. Это также очень эффективно.
- Минусы: C++ может быть трудным для изучения и не имеет большого количества качественных функций — многие вещи должны обрабатываться программистом вручную.
8. Пролог
- Плюсы: Prolog — это декларативный язык программирования, который хорошо подходит для разработки ИИ. Он в основном используется для логического программирования — основы разработки ИИ.
- Минусы: Пролог может быть трудным для изучения и имеет небольшое сообщество разработчиков.
9. Скала
- Плюсы: Scala — это язык общего назначения со многими функциями, подходящими для разработки ИИ. Он хорошо интегрируется с Java и имеет большое сообщество разработчиков.
- Минусы: Scala может быть сложной и трудной для изучения. Scala в основном используется для продвинутых разработок, таких как обработка данных и распределенные вычисления.
Предположим, вы знаете любой из вышеперечисленных языков кодирования для ИИ. В этом случае может быть проще разрабатывать приложения ИИ на одном из этих языков, чем изучать новый. В конечном счете, лучший язык ИИ для вас — тот, который вам легче всего выучить.
Keras
Keras — это высокоуровневый API TensorFlow для создания и обучения кода глубоких нейронных сетей. Это библиотека нейронных сетей с открытым исходным кодом на Python. С Keras статистическое моделирование, работа с изображениями и текстом намного легче с упрощенным кодированием для глубокого обучения.
В чем разница между Keras и TensorFlow?
Keras — это нейросетевая библиотека, написанная на языке Python, а TensorFlow — это библиотека с открытым исходным кодом для различных задач машинного обучения. TensorFlow предоставляет как высокоуровневые, так и низкоуровневые API, в то время как Keras предоставляет только высокоуровневые API. Keras создан для Python и делает его более удобным, модульным и компонуемым, чем TensorFlow.
Что можно делать с помощью Keras?
1. Определить процентную точность;
2. Функция вычисления потерь;
3. Создать пользовательские функциональные слои;
4. Встроенные функции обработки данных и изображений;
5. Функции с повторяющимися блоками кода: глубиной 20, 50, 100 слоев.
#3 SciPy

Популярная библиотека с разными модулями для оптимизации, линейной алгебры, интеграции и статистики.
Преимущества:
- Подходит для управления изображениями.
- Предоставляет простую обработку математических операций.
- Предлагает эффективные математические операции, включая интеграцию и оптимизацию.
- Поддерживает сигнальную обработку.
Недостатки:
Под названием SciPy скрываются как стек, так и библиотека. При этом библиотека является частью стека. Это может сбивать с толку.
Официальная документация: https://www.scipy.org/.Введение в SciPy на русском: Руководство по SciPy: что это, и как ее использовать.