
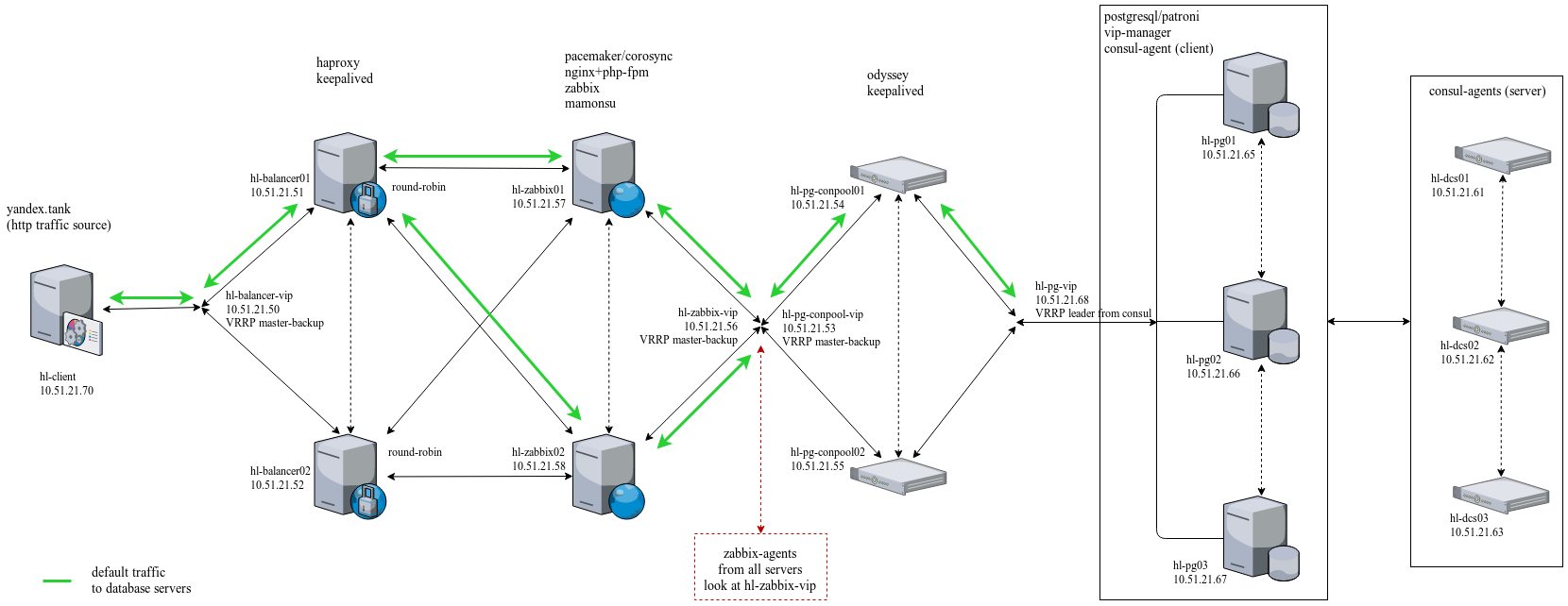
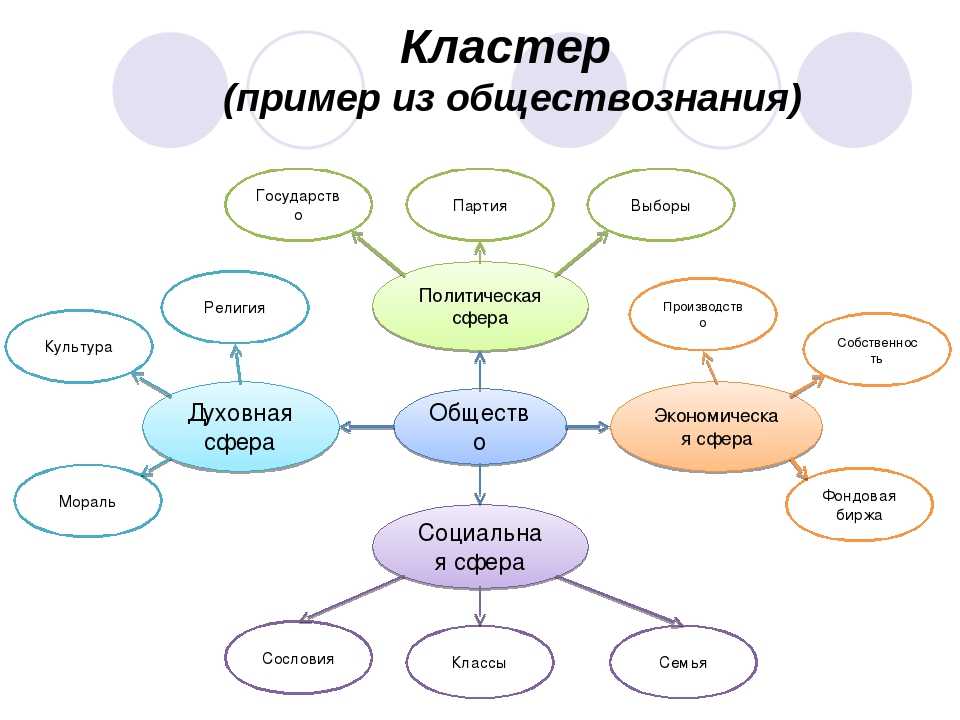
схожесть кластеров[]
Критерием для определения схожести и различия кластеров является расстояние между точками на диаграмме рассеивания. Это сходство можно «измерить», оно равно расстоянию между точками на графике. Способов определения меры расстояния между кластерами, называемой еще мерой близости, существует несколько. Наиболее распространенный способ — вычисление евклидова расстояния между двумя точками i и j на плоскости, когда известны их координаты X и Y:
Dij=(xi−xj)2+(yi−yj)2{\displaystyle D_{ij} = \sqrt{ (x_i — x_j)^2+ ( y_i — y_j )^2}}
Примечание: чтобы узнать расстояние между двумя точками, надо взять разницу их координат по каждой оси, возвести ее в квадрат, сложить полученные значения для всех осей и извлечь квадратный корень из суммы.
Основные принципы кластерного анализа
Кластерный анализ — это метод исследования данных, который позволяет выявлять группы или кластеры схожих объектов. Основные принципы этого анализа включают в себя следующие аспекты:
Выбор метрики: для определения схожести объектов необходимо выбрать подходящую метрику. Она может быть мерой Евклида, косинусным расстоянием или другой, в зависимости от типа данных и задачи исследования.
Постановка задачи: кластерный анализ может быть использован для различных целей. Целью может быть выявление групп в данных, определение наличия или отсутствия закономерностей, построение иерархической структуры и т.д. Корректная постановка задачи важна для достижения нужного результата.
Выбор алгоритма: существует множество алгоритмов кластерного анализа, каждый из которых имеет свои преимущества и ограничения
Важно выбрать подходящий алгоритм в соответствии с поставленной задачей и особенностями данных.
Предобработка данных: перед проведением кластерного анализа необходимо провести предобработку данных. Это может включать в себя удаление выбросов, заполнение пропущенных значений, масштабирование и нормализацию данных.
Определение числа кластеров: важным шагом в кластерном анализе является определение числа кластеров
Существуют различные методы и метрики, такие как индекс силуэта или метод локтя, которые помогают выбрать оптимальное число кластеров.
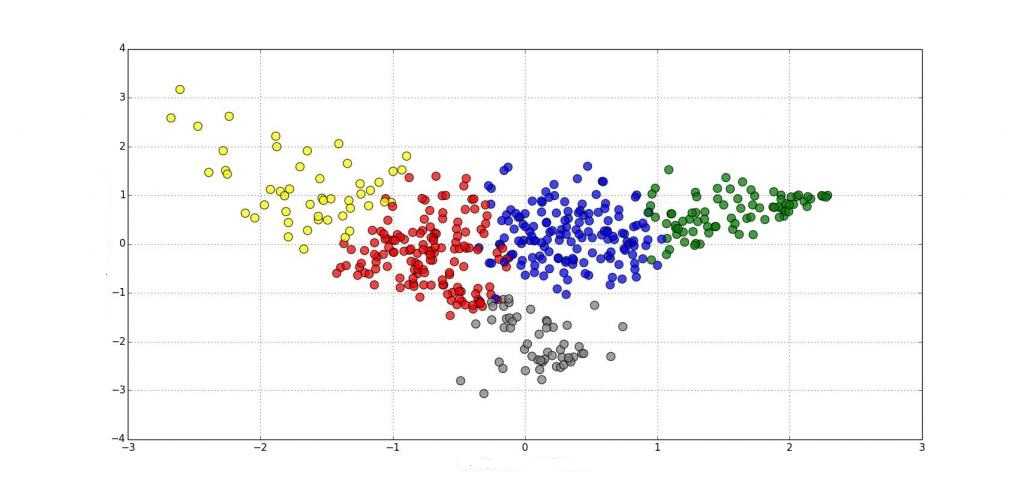
Визуализация результатов: после проведения кластерного анализа важно визуализировать результаты. Это позволяет наглядно представить структуру данных и взаимное расположение кластеров. Для визуализации можно использовать диаграммы рассеяния, тепловые карты, паутины и другие графические методы.
Интерпретация результатов: кластерный анализ позволяет выделить группы схожих объектов, но для полного понимания результатов необходимо их интерпретировать. Это может включать в себя анализ характеристик и свойств объектов в каждом кластере, сравнение кластеров между собой и изучение полученных закономерностей.
Важно отметить, что принципы кластерного анализа могут различаться в зависимости от задачи и выбранного метода. Правильный выбор метода и оценка результатов позволят получить ценные и интерпретируемые результаты, помогающие в изучении и понимании данных
Использование кластерного анализа
С помощью кластерного анализа можно проводить выборку по признаку, который исследуется. Его основная задача – разбиение многомерного массива на однородные группы. В качестве критерия группировки применяется парный коэффициент корреляции или эвклидово расстояние между объектами по заданному параметру. Наиболее близкие друг к другу значения группируются вместе.
Хотя чаще всего данный вид анализа применяют в экономике, его также можно использовать в биологии (для классификации животных), психологии, медицине и во многих других сферах деятельности человека. Кластерный анализ можно применять, используя для этих целей стандартный набор инструментов Эксель.
Пример использования
Имеем пять объектов, которые характеризуются по двум изучаемым параметрам – x и y.
-
Применяем к данным значениям формулу эвклидового расстояния, которое вычисляется по шаблону:
- Данное значение вычисляем между каждым из пяти объектов. Результаты расчета помещаем в матрице расстояний.
- Смотрим, между какими значениями дистанция меньше всего. В нашем примере — это объекты 1 и 2. Расстояние между ними составляет 4,123106, что меньше, чем между любыми другими элементами данной совокупности.
- Объединяем эти данные в группу и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента. Опять смотрим, между какими элементами расстояние минимально. На этот раз – это 4 и 5, а также объект 5 и группа объектов 1,2. Дистанция составляет 6,708204.
- Добавляем указанные элементы в общий кластер. Формируем новую матрицу по тому же принципу, что и в предыдущий раз. То есть, ищем самые меньшие значения. Таким образом мы видим, что нашу совокупность данных можно разбить на два кластера. В первом кластере находятся наиболее близкие между собой элементы – 1,2,4,5. Во втором кластере в нашем случае представлен только один элемент — 3. Он находится сравнительно в отдалении от других объектов. Расстояние между кластерами составляет 9,84.
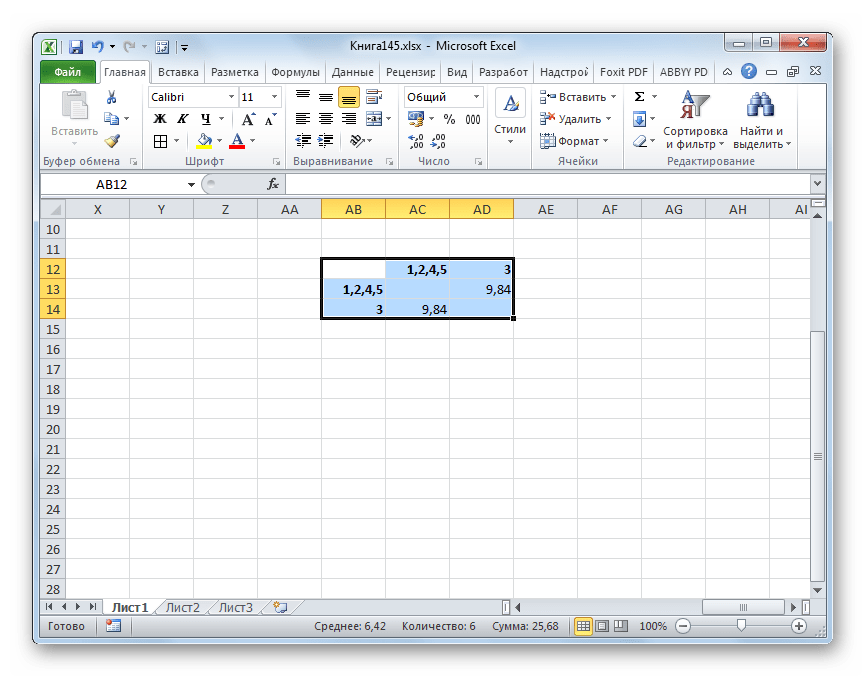
На этом завершается процедура разбиения совокупности на группы.
Как видим, хотя в целом кластерный анализ и может показаться сложной процедурой, но на самом деле разобраться в нюансах данного метода не так уж тяжело. Главное понять основную закономерность объединения в группы.
Помогла ли Вам статья?
Нет
Что это такое
Clustering analysis или кластерный анализ – своеобразный метод анализа данных, при котором объекты разделяются на группы по значимым (важным) критериям. Пример – супермаркет. В нем продукты располагаются по рядам, а каждый из них подписан как «мясо», «овощи», «заморозка», «хлеб» и так далее. Макароны не могут попасться среди «заморозки», а мясо – в конфетах. Подобное разделение – это и есть деление на кластеры.
Сегменты, которые получены после кластеризации данных, изучаются специалистами. Пример – алгоритм (algorithm) смог выделить несколько клиентских групп:
- люди, покупающие продукт 20 раз за год;
- лица, приобретающие ту или иную продукцию раз в год.
Маркетологи могут изучать каждый кластер, а затем понять, как повысить мотивацию «отстающих» покупателей на приобретение товара.
Математические характеристики кластера[]
Кластер имеет следующие математические характеристики:
Центр кластера — это среднее геометрическое место точек в пространстве переменных.
xkj=∑j=1nwjxijIk{\displaystyle x_{kj} = \frac {\sum_{j=1}^n w_jx_{ij}}{I_k}}
Дисперсия кластера — это мера рассеяния точек в пространстве относительно центра кластера:
Dk=∑i=1I1∑j=1nwj(xij−x¯kj)2Ik−1{\displaystyle D_k = \frac{\sum_{i=1}^{I_1} \sum_{j=1}^n w_j(x_{ij}-\overline x_{kj})^2}{I_k -1}}
Среднеквадратичное отклонение (СКО) объектов относительно центра кластера:
Sk=Dk{\displaystyle S_k = \sqrt{D_k}}
Радиус кластера — максимальное расстояние точек от центра кластера:
Rk=max∑j=1nwj(xij−x¯kj)2{\displaystyle R_k = max \sqrt{\sum_{j=1}^n w_j(x_{ij}-\overline x_{kj})^2}}
Спорный объект — это объект, который по мере сходства может быть отнесен к нескольким кластерам.
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным.
Неоднозначность данной задачи может быть устранена экспертом или аналитиком.
Работа кластерного анализа опирается на два предположения:
Первое предположение — рассматриваемые признаки объекта в принципе допускают желательное разбиение совокупности объектов на кластеры.
Второе предположение — правильность выбора масштаба или единиц измерения признаков.
Области применения
Кластеры данных широко применяются в современной жизни. Он может встречаться в:
- Маркетинге. Технология деления на кластеры способствует сегментированию клиентов, конкурентов, а также рынка.
- Медицине. Кластеры «классифицируют» заболевания, препараты и симптоматику.
- Биологии. Разделение животных и растений.
- Социологии. Используются кластеры данных для того, чтобы делить респондентов на однородные группы лиц.
- Финансах. Банки применяются данный тип анализа для «классификации» клиентов, услуг и процессов, финансовых операций.
- Компьютерных науках. За счет работы с кластерами получается в удобной форме представлять результаты поиска сайтов, файлов и других объектов. Они способствуют более быстрому анализу Big Data и машинному обучению.
Кластеризация (cluster analysis) может встречаться везде, где требуется структурировать и систематизировать информацию. Она активно используется специалистами для работы с данными.
Какие особенности и преимущества кластерного анализа?
Для применения КА также необходимо учитывать такие понятия как “дельта” и профиль рынка. Это позволит создать более комплексную картину рыночной ситуации.






Delta
“Дельта” — это разница между объемами сделок на покупку (Ask) и продажу (Bid) в одном кластере.
Если дельта положительна, это говорит о том, что на рынке доминируют покупатели.
Если отрицательна — это свидетельство того, что сделок на продажу больше.
В настройках графика можно выбрать режим отображения кластеров по дельте.

Отображение кластера по дельте
Значение дельта может быть нормальным (при тренде) и критическим. Последнее выделяется красным цветом на графике и чаще всего предшествует развороту.
При флэте, значение уровня дельта умеренное и переход к нормальному уровню может подсказать начало тренда.
Market profile
При анализе графика обращайте внимание на светло-серые зоны с указателем POC (Point of Control — точка контроля) и зона стоимости (Value Area). Вторая показывает, где рынок находится в состоянии баланса
Вторая показывает, где рынок находится в состоянии баланса.
РОС указывает на максимальный объем, прошедший на баре (свече).
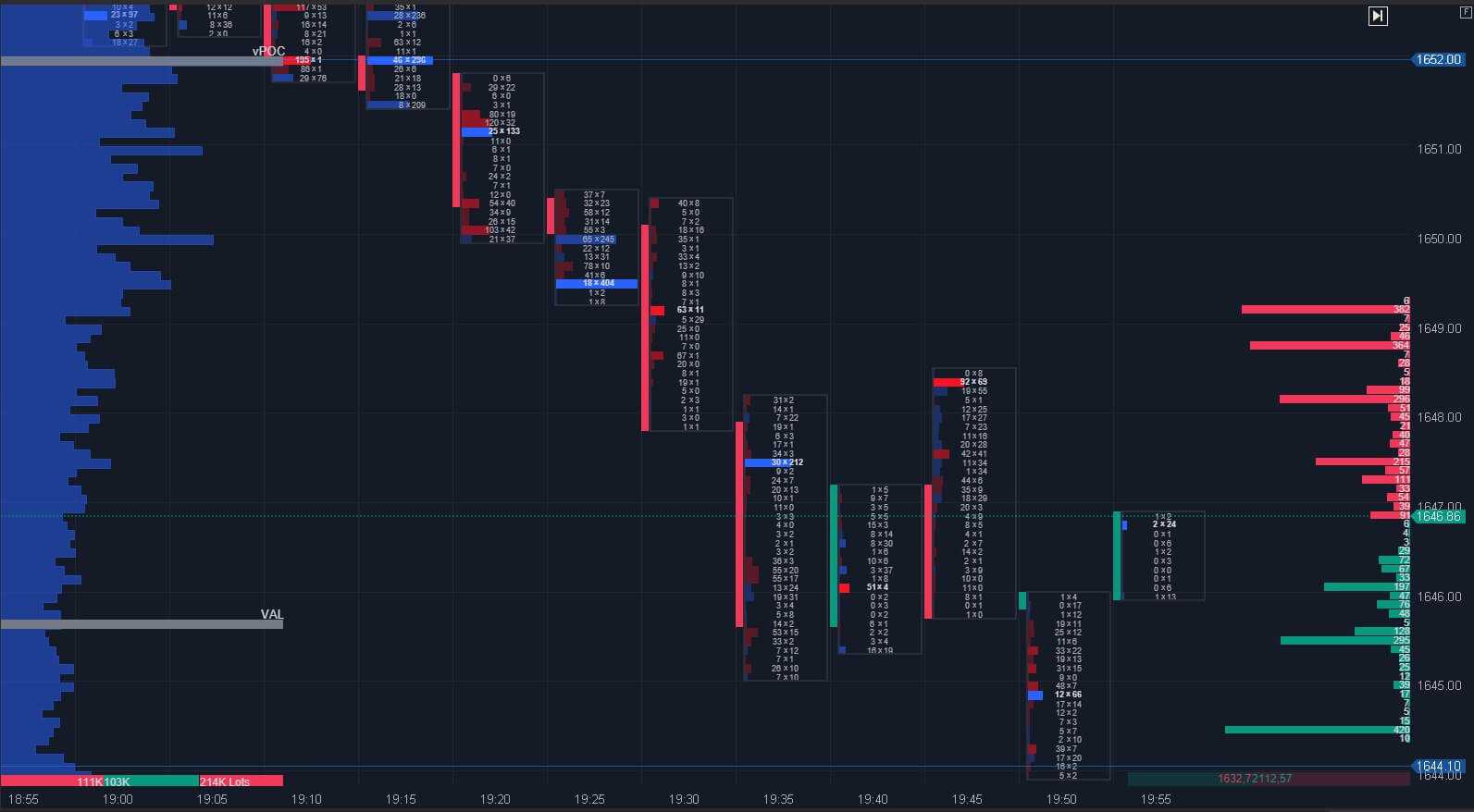
POC на графике ETHUSDT
POC на уровне поддержки или сопротивления говорит: здесь покупатель или продавец имеют контроль над рынком.
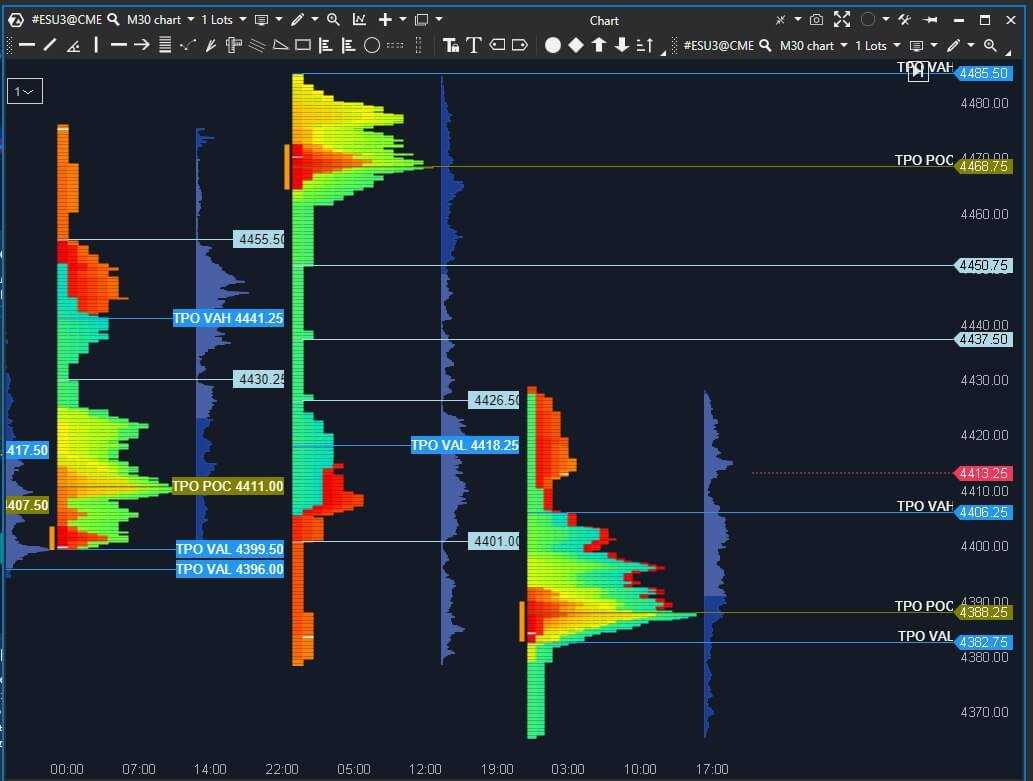
Market-profile
Кластерный анализ рынка имеет преимущества:
— показывает, где находится крупный игрок; скопление больших объемов возле определенного ценового уровня дает возможность определить сильные уровни поддержки и сопротивления;
— информирует, кто в данный момент доминирует на рынке — покупатели или продавцы; дельта помогает определить вероятное направление движения рынка.
Дельта в кластерном анализе
Помимо объема, кластера могу показывать нам и дельту. Это разница между проторгованными объемами продавцов и покупателей.
Дельта = ASK — BID

Если дельта положительная, это значит что покупателей больше, чем продавцов, если дельта отрицательная, то на оборот — продавцов больше, чем покупателей на данном ценовом уровне.
Трейдеры разделяют несколько видов дельты:
- Умеренная (возникает, как правило, во флете, примерно одинаковое количество покупателей и продавцов, так называем баланс).
- Нормальная (это обычно трендовая фаза, где видно сильно преобладание какой либо стороны).
- Критическая (разворот и зарождение нового тренда).
Определение и логика кластерного анализа
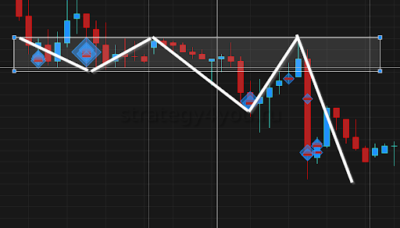 Кластеры состоят из однородных элементов. Их можно рассматривать в качестве самостоятельных единиц, обладающих заданными свойствами. В ходе торгов за интервал времени стороны совершают сделки, покупая и продавая активы. При этом образуются кластеры. По ним можно увидеть, сколько было куплено или продано актива по установленной цене за выбранный промежуток времени.
Кластеры состоят из однородных элементов. Их можно рассматривать в качестве самостоятельных единиц, обладающих заданными свойствами. В ходе торгов за интервал времени стороны совершают сделки, покупая и продавая активы. При этом образуются кластеры. По ним можно увидеть, сколько было куплено или продано актива по установленной цене за выбранный промежуток времени.
Для того чтобы было видно, в какую сторону направляется цена, специалисты изобрели кластерный график. На каждый его бар наносят объемы.
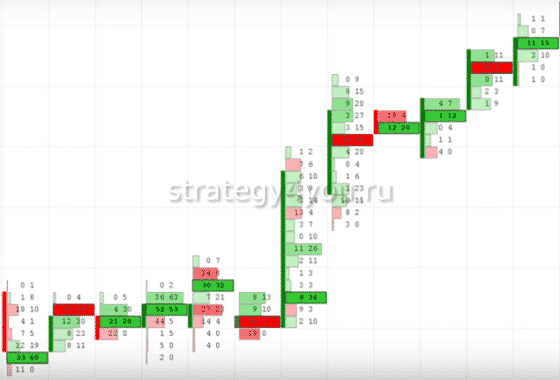
Начинающие трейдеры могут задать вопрос, откуда они берутся. Если работа на рынке осуществляется на терминале Quik, то используется таблица (лента) всех совершенных сделок. Ее можно посмотреть для любого торгуемого финансового инструмента. В ней указаны сделки, а также их объемы.
Их учитывают при формировании кластерного графика. С помощью такой информации трейдер лучше понимает, что было, когда происходило формирование свечи.
По этому признаку все заявки можно разделить на следующие категории:
- Поступившие от профессионалов. Это сделки большого объема.
- Принятые от мелких торговцев. В этом случае объем намного меньше.
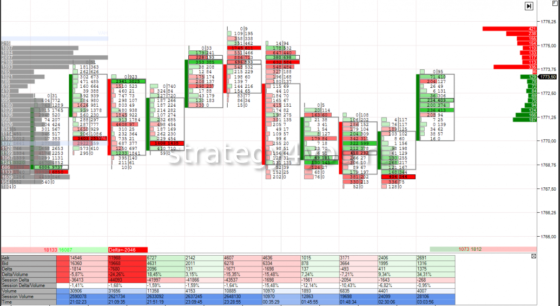
Кластерный анализ в трейдинге помогает рядовым участникам рынка понять, какие действия предпринимали крупные игроки: покупали они актив или продавали его. Какие объемы сделок были, где находилась ценовая отметка.
Эта информация находит отражение в кластере. Если на рынке одновременно заключались сделки по одинаковой цене, за это время формировалась 1 свеча, происходит суммирование объемов. В результате трейдер получает точную рыночную информацию
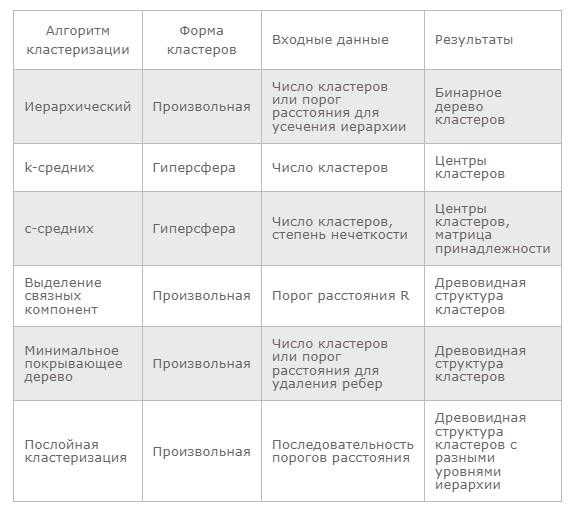
Сравнительная характеристика алгоритмов
Ниже можно увидеть таблицу, которая показывает основные сходства и различия рассмотренных ранее концепций разделения информации на сегменты:
Кластеры данных рекомендуется использовать в различных сферах деятельности. Этот прием особо важен для рекламы – когда требуется направить расходы в «нужное» русло и так, чтобы добиться максимальной эффективности. Именно сегментация позволит выяснить, на что потратиться.
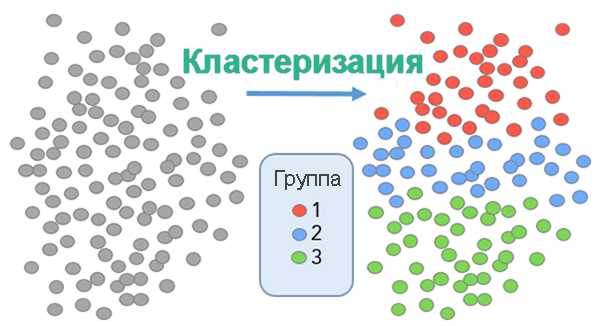
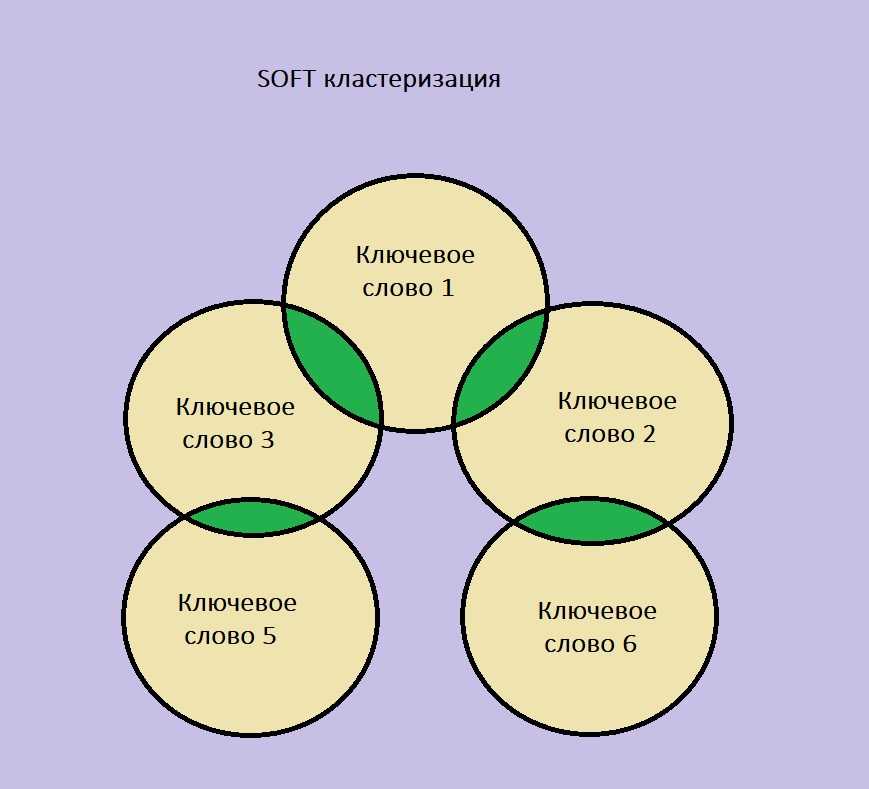
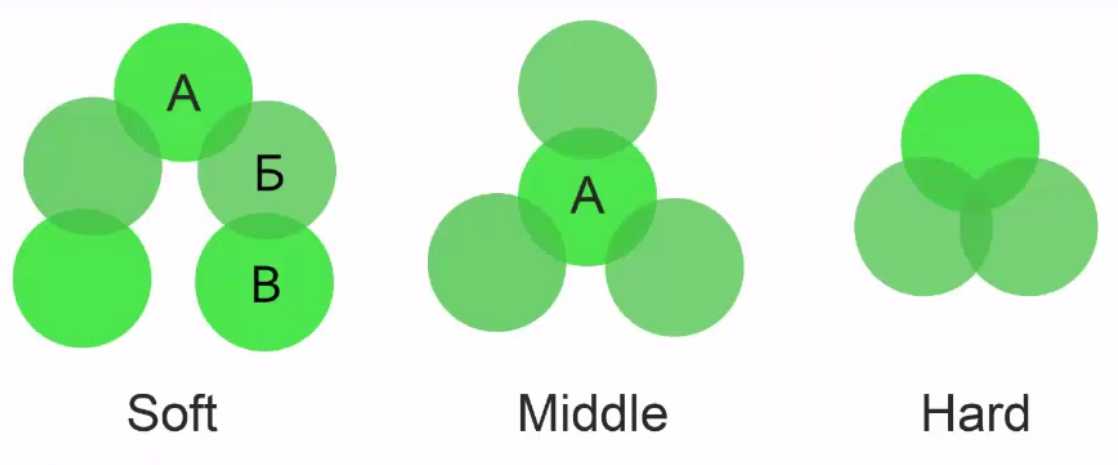


Самостоятельно разобраться с рассмотренной тематикой бывает проблематично, особенно если раньше человек не занимался анализом. Лучше и быстрее «с нуля» соответствующее направление помогут изучить специализированные дистанционные курсы. На них в срок до года пользователя обучат глубинному анализу информации или позволят получить инновационную IT-профессию. В конце курса ученику будет выдан электронный сертификат. С его помощью получится подтвердить приобретенные знания документально.
Прокачать свои навыки владения инструментами и технологиями работы с большими данными можно онлайн на образовательной платформе OTUS:
Программы для кластерного графика
Представляю вам самые популярные программы для кластерного анализа на данный момент:
1) SBPro
Основные преимущества:
Кластеры Кластерные графики для отображения объемов, дельты и Bid-Ask.Симулятор Тестирование стратегий на истории.Лента сделок Лента сделок прямо на графике! Гибкая аккумуляция принтов.Профили Множество типов Profile графиков с фильтрацией по объему и дельте.Сайт — https://www.sb-professional.com/
2) ATAS
Основные преимущества:
Smart Tape “Умная Лента Принтов” агрегирует и фильтрует рыночные сделки, что позволит Вам увидеть реальных крупных игроков рынка.Графики 6 видов построения графиков, в том числе профильные и кластерные графики (25 вариантов футпринта).Smart DOM “Умный Стакан” позволит проводить анализ биржевой ликвидности и отслеживать заявки крупных игроков.Торговля Удобная торговля и управление позициями, как через торговый стакан, так и прямо с графика (Chart Trader).Сайт — https://orderflowtrading.ru/
3) Volfix
Основные преимущества:
Многоуровневая система алертов.Широкий набор инструментов для объемного и профильного анализа.Интегрированный DOM Analyzer можно адаптировать под любые Ваши торговые идеи.Более семи лет исторических данных — цена, Tick , Trade и Bid & Ask объем, Block Trades и др.Сайт — http://volfix.net/ru/
4) NinjaTrader
Основные преимущества:
Вам доступны самые крупные мировые рынки, включая: — Фьючерсы.— Форекс.— Опционы.— CFD’s.— Акции.Многочисленные встроенные индикаторы для принятия важных торговых решений.Большой выбор провайдеров данных.Сайт — https://ninjatrader.com/ru/
5) TigerTrade
Основные преимущества:
Свечные графики и футпринт.Динамический стакан.Лента сделок.Проигрыватель истории.Аналитические инструменты.Статистика сделок.История.Риск-менеджер.Сайт — https://tigertradesoft.ru/
Если вы не хотите использовать какие либо сторонние программы, то вы можете использовать индикаторы для MetaTrader, но как правило эти индикаторы показывают не реальный объем, а тиковый.
Типы данных для кластерного анализа
При проведении кластерного анализа обычно используются четыре типа данных:
1. Числовые данные
Числовые данные состоят из количественных величин, которые можно измерить или посчитать. Этот тип данных далее подразделяется на два подтипа:
-
Непрерывные данные : Непрерывные данные представляют собой переменные, которые могут принимать любое значение в определенном диапазоне. Примеры включают температуру, высоту или время.
-
Дискретные данные : Дискретные данные представляют собой переменные, которые могут принимать только разные значения. Примеры включают количество братьев и сестер, количество клиентов или количество проданных продуктов.
Числовые данные часто используются в кластерном анализе, поскольку они позволяют проводить математические расчеты и сравнивать различные точки данных.
2. Категориальные данные
Категориальные данные состоят из нечисловых переменных, которые представляют разные категории или группы. Этот тип данных обычно используется для описания характеристик или атрибутов. Примеры включают пол, семейное положение или категории продуктов. Категориальные данные в кластерном анализе обычно преобразуются в числовые представления с использованием таких методов, как горячее кодирование.
3. Двоичные данные
Двоичные данные — это особый случай категориальных данных, которые состоят из переменных, которые могут принимать только два значения, обычно представленных как 0 и 1. Примеры двоичных данных включают ответы да/нет, утверждения «истина/ложь» или индикаторы присутствия/отсутствия.
Двоичные данные часто используются в кластерном анализе при анализе предпочтений или закономерностей, связанных с определенной характеристикой.
Иерархический кластерный анализ в SPSS[]
Рассмотрим процедуру иерархического кластерного анализа в пакете SPSS (SPSS). Процедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), так и переменных (столбцов). Можно считать, что в последнем случае роль объектов играют переменные, а роль переменных — столбцы.
В этом методе реализуется иерархический агломеративный алгоритм, смысл которого заключается в следующем. Перед началом кластеризации все объекты считаются отдельными кластерами, в ходе алгоритма они объединяются. Вначале выбирается пара ближайших кластеров, которые объединяются в один кластер. В результате количество кластеров становится равным N-1. Процедура повторяется, пока все классы не объединятся. На любом этапе объединение можно прервать, получив нужное число кластеров. Таким образом, результат работы алгоритма агрегирования зависит от способов вычисления расстояния между объектами и определения близости между кластерами.
Для определения расстояния между парой кластеров могут быть сформулированы различные подходы. С учетом этого в SPSS предусмотрены следующие методы:
• Среднее расстояние между кластерами (Between-groups linkage), устанавливается по умолчанию.
• Среднее расстояние между всеми объектами пары кластеров с учетом расстояний внутри кластеров (Within-groups linkage).
• Расстояние между ближайшими соседями — ближайшими объектами кластеров (Nearest neighbor).
• Расстояние между самыми далекими соседями (Furthest neighbor).
• Расстояние между центрами кластеров (Centroid clustering) или центроидный метод. Недостатком этого метода является то, что центр объединенного кластера вычисляется как среднее центров объединяемых кластеров, без учета их объема.
• Метод медиан — тот же центроидный метод, но центр объединенного кластера вычисляется как среднее всех объектов (Median clustering).
• Метод Варда.
Цели и задачи
Задачи кластеризации – это:
- Сжатие информации. Кластеры актуальны, если исходные выборки слишком объемные. После применения соответствующего приема от каждого сегмента останется по одному типичному представителю. Количество кластеров может быть любым. Главным моментом при сжатии данных является обеспечение максимального сходства компонентов друг с другом внутри каждого «типа».
- Поиск паттернов в информационном пространстве. Кластер данных позволит добавить дополнительный признак каждому компоненты. Если в результате analysis (анализа) выяснилось, что тот или иной покупатель относится к одному сегменту потребителей, а также известно, что это – категория людей с самыми крупными расходами по средам, можно сделать вывод о том, когда именно человек совершает покупки.
- Обнаружение аномалий. При кластеризации объектов удается выделить нетипичные элементы. Такие, которые не подходят ни к одному сформированному сегменту.
- Анализ цен. Кластеры данных – это отправные точки для более глубокого ценового анализа. Способствуют грамотному ценообразованию и формированию адекватной конкурентоспособности.
- Продвижение. Рассматриваемый процесс – верный помощник любого маркетолога. На основе сегментации продукции продавцы получают возможность идентификации продуктовых наборов для повышения продаж. Сюда же можно отнести принятие мер для увеличения количества заказанных предметов каждым покупателем.
- Понимание. Важная задача кластеризации – это повышение уровня понимания «ситуации». Деление разрозненных данных на отдельные сегменты дает возможность понять, какие именно сведения собраны. Все это благоприятно сказывается на дальнейшей обработке. Пример – применять к каждой получившейся «группе» определенные методы анализа.
- Расширение. Рассматриваемая «технология» приводит к тому, что при сборе информации каких-то общих признаков больше, а каких-то – меньше. При кластеризации данных удается предположить отсутствующие признаки у других компонентов «сегмента». Пример – известно, что клиенты-мужчины проводят на сайте 15 минут в среднем. Если на сервисе появляется человек с неизвестным временем, можно предположить, что для него тоже время пребывания на веб-проекте составляет 15 минут.
Существуют различные алгоритмы кластеризации данных. Википедия указывает на то, что они применяются для самых разных ситуаций на практике. Если знать, как грамотно кластеризовать информацию, аналитик сможет быстро добиться колоссальных успехов.




Кластеризация в Data Mining
Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель на всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
Очень часто данные, с которыми сталкивается технология Data Mining, имеют следующие важные особенности:
- высокая размерность (тысячи полей) и большой объем (сотни тысяч и миллионы записей) таблиц баз данных и хранилищ данных (сверхбольшие базы данных);
- наборы данных содержат большое количество числовых и категорийных атрибутов.
Все атрибуты или признаки объектов делятся на числовые (numerical) и категорийные (categorical). Числовые атрибуты – это такие, которые могут быть упорядочены в пространстве, соответственно категорийные – которое не могут быть упорядочены. Например, атрибут «возраст» – числовой, а «цвет» – категорийный. Приписывание атрибутам значений происходит во время измерений выбранным типом шкалы, а это, вообще говоря, представляет собой отдельную задачу.
Большинство алгоритмов кластеризации предполагают сравнение объектов между собой на основе некоторой меры близости (сходства). Мерой близости называется величина, имеющая предел и возрастающая с увеличением близости объектов. Меры сходства «изобретаются» по специальным правилам, а выбор конкретных мер зависит от задачи, а также от шкалы измерений. В качестве меры близости для числовых атрибутов очень часто используется евклидово расстояние, вычисляемое по формуле:
D(x, y)=\sqrt{\sum_{i}{(x-y)^2}}
Для категорийных атрибутов распространена мера сходства Чекановского-Серенсена и Жаккара ( \mid t_1 \cap t_2\mid/\mid t_1\cup t_2 \mid).
Потребность в обработке больших массивов данных в Data Mining привела к формулированию требований, которым, по возможности, должен удовлетворять алгоритм кластеризации. Рассмотрим их:
- Минимально возможное количество проходов по базе данных;
- Работа в ограниченном объеме оперативной памяти компьютера;
- Работу алгоритма можно прервать с сохранением промежуточных результатов, чтобы продолжить вычисления позже;
- Алгоритм должен работать, когда объекты из базы данных могут извлекаться только в режиме однонаправленного курсора (т.е. в режиме навигации по записям).
Алгоритм, удовлетворяющий данным требованиям (особенно второму), будем называть масштабируемым (scalable). Масштабируемость – важнейшее свойство алгоритма, зависящее от его вычислительной сложности и программной реализации. Имеется и более емкое определение. Алгоритм называют масштабируемым, если при неизменной емкости оперативной памяти с увеличением числа записей в базе данных время его работы растет линейно.
Но далеко не всегда требуется обрабатывать сверхбольшие массивы данных. Поэтому на заре становления теории кластерного анализа вопросам масштабируемости алгоритмов внимания практически не уделялось. Предполагалось, что все обрабатываемые данные будут умещаться в оперативной памяти, главный упор всегда делался на улучшение качества кластеризации.
Трудно соблюсти баланс между высоким качеством кластеризации и масштабируемостью. Поэтому в идеале в арсенале Data Mining должны присутствовать как эффективные алгоритмы кластеризации микромассивов (microarrays), так и масштабируемые для обработки сверхбольших баз данных (large databases).
Подготовка данных для кластерного анализа
После того, как соответствующий тип данных был определен для кластерного анализа, крайне важно предварительно обработать и подготовить данные перед применением любого алгоритма кластеризации. Подготовка данных обычно включает следующие этапы:
-
Очистка данных : удалите все ненужные или зашумленные данные, которые могут помешать процессу кластеризации.
-
Нормализация : Масштабируйте данные, чтобы гарантировать, что переменные с разными величинами или единицами измерения обрабатываются одинаково.
-
Выбор функции : Определите наиболее важные функции или переменные, которые будут использоваться для кластеризации.
-
Преобразование данных : Преобразуйте данные, если необходимо, чтобы они соответствовали предположениям выбранного алгоритма кластеризации.
Тщательно подготавливая данные, мы можем гарантировать, что кластерный анализ даст точные и значимые результаты.