
Тарифы на использование
Цена программы весьма демократичная, особенно если учитывать, что платеж единоразовый, а лицензия – бессрочная.
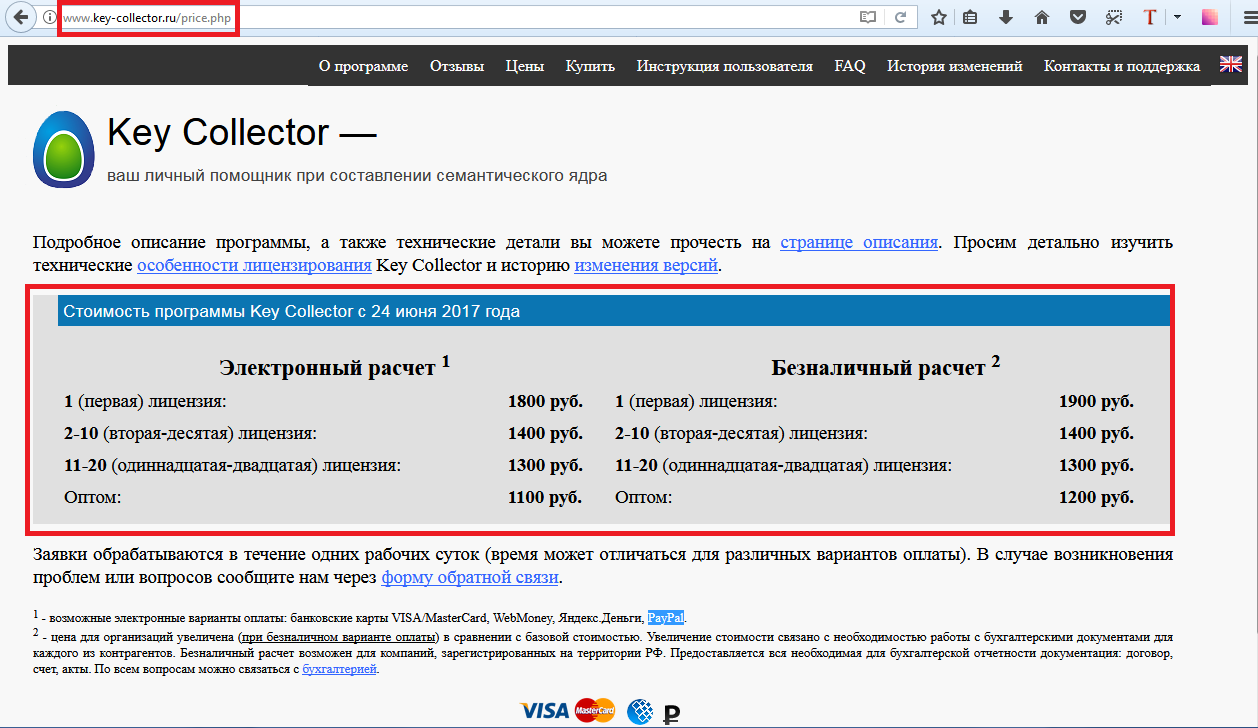
Лицензия на одно устройство стоит 1800 рублей. Если вы захотите поставить программу еще на одно свое устройство, то вторая лицензия уже будет стоить 1400 рублей. Минимальную цену можно получить при оптовой закупке (от 20 программ). В таком случае цена составит 1100 рублей.

В интернете можно найти версии различной давности с таблеткой и, возможно даже, не получить себе на жесткий диск ворох вирусов и троянов. Но с учетом полезности софта и его невысокой стоимости устраивать себе самостоятельно сложности на ровном месте не стоит. В интернете огромное количество отзывов от довольных пользователей, которые уже не один десяток раз окупили лицензию.
Key Collector
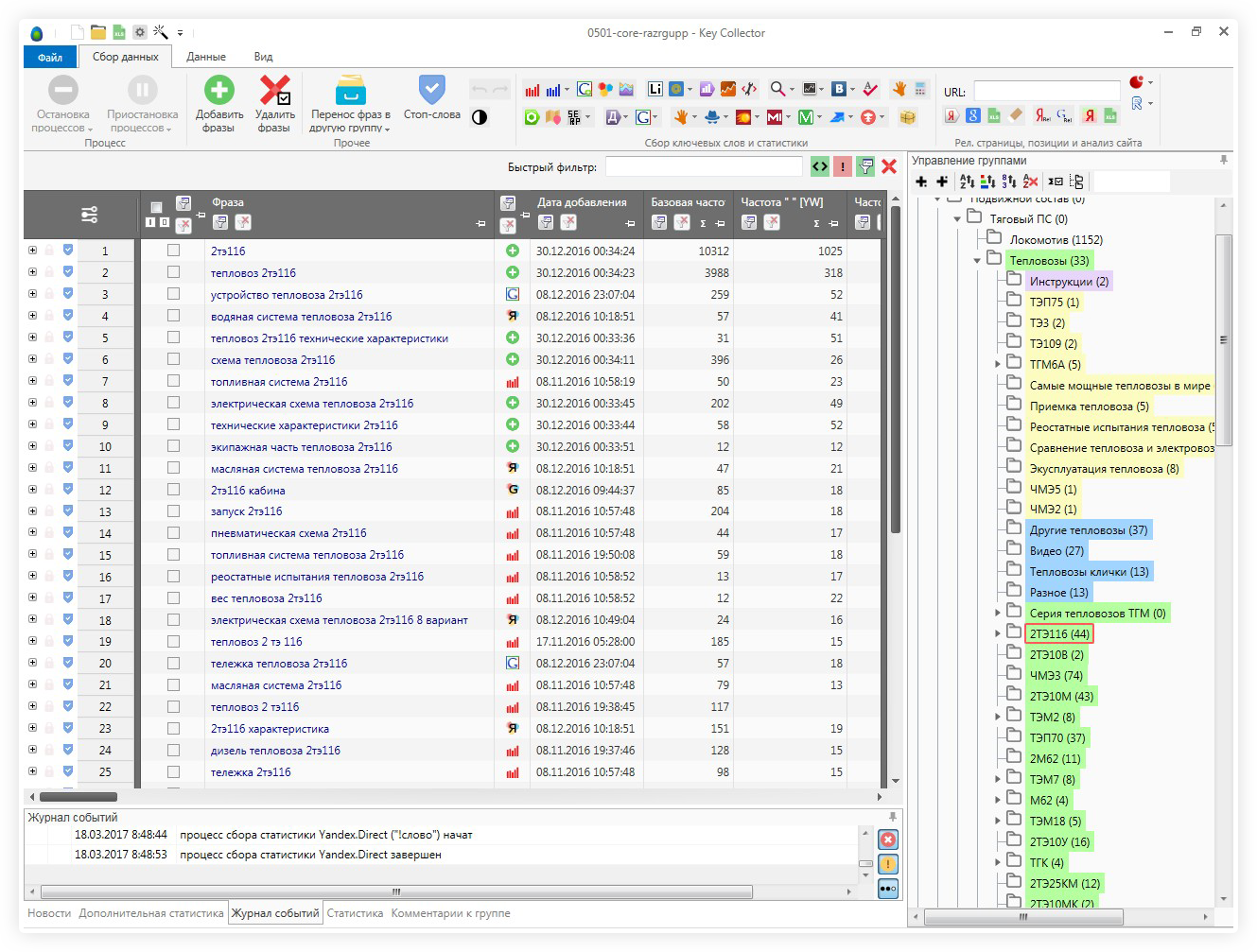
Key Collector – одна из программ занимающихся парсингом ключевых слов и статистики из различных сервисов включая такие, как Яндекс Wordstat, Google AdWords, Begun, и другие.
Интерфейс Key Collector
Key Collector – программа хоть и платная 1 800 за одну копию (без учета скидок), зато она не имеет платной ежемесячной подписки, а это явное преимущество над другими конкурентами.
Также хочется заметить, что она довольно быстро обновляется и реагирует на обновления сервисов.
Интерфейс программы довольно простой, а на официальном сайте есть отличное руководство по всем тонкостям работы с ним.
Перед созданием нового проекта нам потребуется настроить программу, для этого перейдем в настройки.
Настройки Key Collector
Из всего многообразия параметров изменять лучше лишь те, в которых вы уже разобрались, так как при неправильном их задании обычно все сводится к бану прокси серверов и/или аккаунтов Яндекса, которые используются для парсинга.
Подготовка к работе:
Перед началом работы с кей-коллектором необходимо выполнить несколько важных шагов:
- Убедитесь, что у вас есть все необходимые компоненты для настройки кей-коллектора. Вам понадобится компьютер с доступом в интернет, кей-коллектор (желательно с актуальной версией программного обеспечения), а также соответствующие кабели и подключения.
- Ознакомьтесь с документацией к кей-коллектору. Прочтите инструкцию по установке и настройке устройства. Это поможет вам понять основные функции и возможности кей-коллектора, а также избежать ошибок при работе с ним.
- Установите программное обеспечение, необходимое для работы с кей-коллектором. Обычно данное ПО поставляется вместе с устройством или может быть скачано с официального сайта производителя. Убедитесь, что у вас установлена последняя версия ПО.
- Подключите кей-коллектор к компьютеру с помощью соответствующих кабелей. Убедитесь, что подключение произведено правильно и устройство успешно распознается компьютером.
- Настройте кей-коллектор в соответствии с вашими потребностями. В зависимости от задач, которые вы планируете решать с помощью кей-коллектора, может потребоваться настройка определенных параметров и параметров сбора данных.
- Проведите проверочные тесты перед началом работы. Убедитесь, что все компоненты правильно функционируют, исключив возможные ошибки до начала важных задач.
После выполнения всех этих шагов вы будете готовы к работе с кей-коллектором. Переходите к следующему этапу — настройке и запуску сбора данных.
Кей коллектор инструкция для начинающих
Всем доброго времени суток! Сегодня обсудим такой вариант составления семантического ядра и подбора ключевиков под конкретную статью, как использование платного софта, а конкретно самую популярную и мощную программу key collector. Программа дает пользователю огромный набор возможностей, в которых легко можно потеряться, при взгляде же на объем туториала на официальном сайте становится дурно. Так что в этой статье разберем самые основы, как проводится настройка key collector и как легко и быстро получить нужные нам данные, не трогая полезные, но чаще всего ненужные простому вэбмастеру функции.
Для начала — если для вас незнакомо понятие «семантическое ядро» и вы не в курсе для чего нужны ключевые слова, то вам нужно внимательно прочитать мои статьи Основы раскрутки сайта и Методы составления семантического ядра. Ничего особо сложного там нет, но без этой информации нет никакого смысла лезть работать с кейколектор.
Если же вы понимаете насколько семантическое ядро необходимо для развития сайта, то думаю вы много слышали про кейколектор. Я даже думаю, что вы, как и я в свое время, вполне вероятно уже приобрели эту программу и сейчас, запустив ее находитесь в легкой растерянности от объема доступных функций, кнопок и клавиш. Поэтому постараюсь подробно расписать основной алгоритм получения нужных нам данных, так сказать самые основы. Крошечную часть того, что программа предоставляет. После того, как вы освоите это, все остальные функции уже сами поймете, по мере надобности.
Сбор семантики
Вот мы и перешли к самому вкусному. Собирать ключи можно из левой и правой колонок Вордстата. Как вы наверняка знаете, в левой показываются запросы с вхождением ключевого слова. В правой же – похожие запросы.
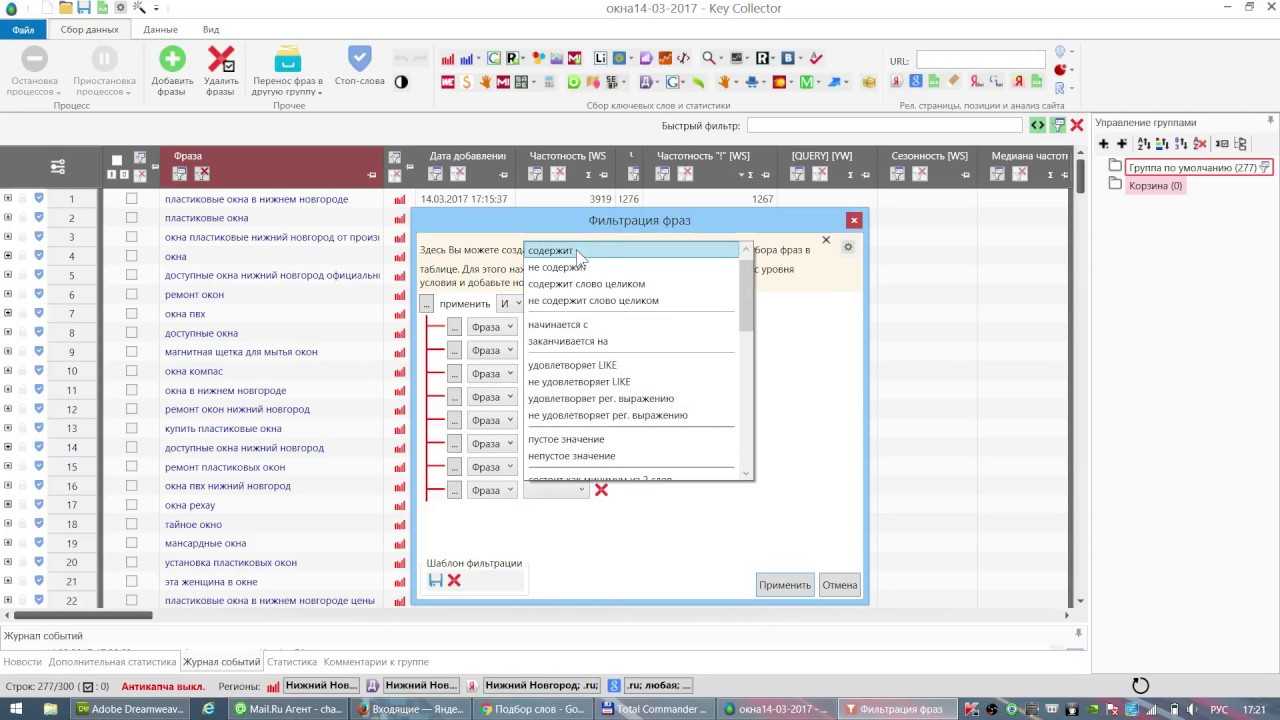
В этом материале мы рассмотрим именно сбор из левой колонки. Итак, нажимаем на красную иконку, после чего у нас открывается такое окно.
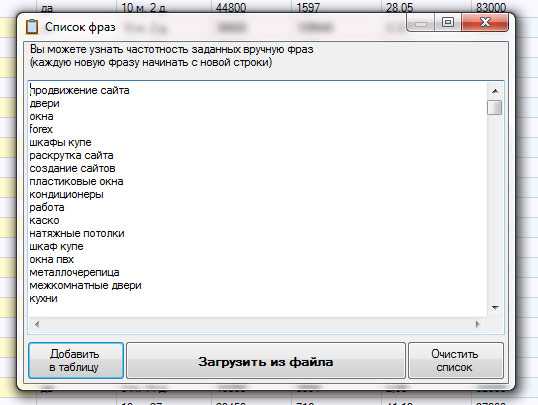
Здесь мы можем ввести все ключевые слова, которые нам нужны. Их можно разбить на вкладки и группы. Ключи можно вводить вручную, а можно просто выгрузить из файла.
После нажатия кнопки “Начать сбор” программа начнет свою работу. В зависимости от настроек и количества ключей этот процесс может занять определенное время. Иногда и по несколько часов. В конечном итоге вы получите список всех ключевых слов и фраз из левой колонки Вордстата.
Далее мы можем снять более точную частотность, потому как та, что будет доступна сразу после сбора, – ложная. Не стоит ей доверять и уж тем более делать какие-то выводы.
При сборе из правой колонки порядок действий тот же самый. Только ключей получится больше, в силу того, что в таблицу попадут все “похожие”.
Частотность
После сбора самой семантики, вы можете собрать частотность. Причем базовая частотность не даст нам особо полезной информации, поэтому нас интересует частотности с вхождением конкретных слов (“ “) и с точным вхождением (“!”)
Для сбора всех видов частотностей мы можем использовать одну кнопку.
Съем более точных частотностей позволит вам получить наиболее правильные статистические данные о количестве запросов в Яндексе. Базовая вариация не отражает истинную суть, и чаще всего при составлении семантического ядра она игнорируется.
Именно сбор частотности в конечном итоге позволяет вам кластеризовать семантическое ядро по запросам: ВЧ, СЧ и НЧ. Исходя из этих данных, сеошники могут разделять ключи по группам, создавая для каждой отдельной статьи свою небольшую базу из тайтла и нескольких ключевых слов. Далее эта информация передается копирайтерам для написания статей. Сейчас такой способ является наиболее популярным при работе с информационными сайтами.
Сезонность
Сезонные запросы – это ключи, которые актуальны в какое-то время года или в какое-то конкретное время. Если вы собираете семантику для магазина с пляжными товарами, то вам нужно брать в расчет наибольший спрос, а именно в летнее время.
Сбор сезонности позволит вам определить, какие запросы в какое время пользуются наибольшей популярностью. Чтобы собрать эту информацию с помощью Кей Коллектора, найдите в меню иконок кнопку “Сбор ключевых слов и статистики”.
После завершения процесса на примере графика вы сможете увидеть популярность того или иного запроса в какой-то конкретный месяц.
Вы можете получить данные по неделям, а не по месяцам, как это представлено на скриншоте. Для настройки используйте все ту же кнопку “Сбор ключевых слов и статистики”, она раскрывается, там вы и найдете соответствующий пункт.
При необходимости вы можете посмотреть более подробную информацию. Для этого просто кликните на нужной ячейке.
Подбираем маски
Пробиваем маски через Wordstat и ищем похожие запросы.
Пример: собираем РК для бокс-клуба. Наши маски: «записаться на бокс», «занятия боксом» и т. д. Само слово «бокс» слишком широкое по смыслу. Включить его в нашу РК даже в точном соответствии нельзя. Но мы можем пробить слово «бокс» (уточнённое высокочастотными минус-словами) через Wordstat и найти ещё несколько масок, например, «абонемент на бокс», «тренера по боксу» и т. п.
Замеряем пульс российского диджитал-консалтинга
Какие консалтинговые услуги востребованы на российском рынке, и как они меняют бизнес-процессы? Представляете компанию-заказчика диджитал-услуг?
Примите участие в исследовании Convergent, Ruward и Cossa!
Кроме того
-
Изучайте отчёты по реальным поисковым фразам в «Яндекс.Метрике» и Google AdWords.
-
Используйте сервисы подбора синонимов.
-
Пользуйтесь формулами сцепки в Excel или сервисами перемножения. Excel позволяет рассортировать все полученные маски «по полочкам», точнее, по столбикам. Сервис перемножения, наоборот, формирует единый столбец. Что удобнее — зависит от ситуации.
-
Используйте минус-слова уже на уровне масок для уточнения запросов. Например, мы собираем ядро для шкафов, предназначенных для разных помещений. Очевидные маски: «Шкаф гостиная», «Шкаф прихожая» и т. д. Но также можно пробить «Шкаф -духовой -холодильный» — этими минусами мы отсеем половину мусора уже на входе.
-
Пользуйтесь операторами «+» и «!», чтобы вытянуть большее количество слов из Wordstat. (Знак «!» фиксирует падеж и число слова, а «+» нужен для принудительного учёта предлогов и союзов.) По запросу с использованием операторов Wordstat выдаёт новую выборку, в которой могут оказаться и новые слова.
Пример: пробиваем маску «купить шкаф». Wordstat выдаёт фразы со следующей частотностью:
-
«купить шкаф» (100 000 показов);
-
«купить шкаф москва» (50 000 показов);
-
«купить шкаф недорого» (10 000 показов).
-
…
Далее пробиваем маску «Купить шкаф +в» — и тут Wordstat выдаёт новую картинку:
-
«купить шкаф +в» (70 000 показов);
-
«купить шкаф +в спальню» (40 000) показов;
-
…
Во вторую выборку попал запрос «купить шкаф +в спальню» (40 000 показов). Это вложенная фраза для «Купить шкаф». Судя по количеству показов, она должна оказаться в первой выборке между фразами «Купить шкаф москва» (50 000) и «Купить шкаф недорого» (10 000), но её там нет.
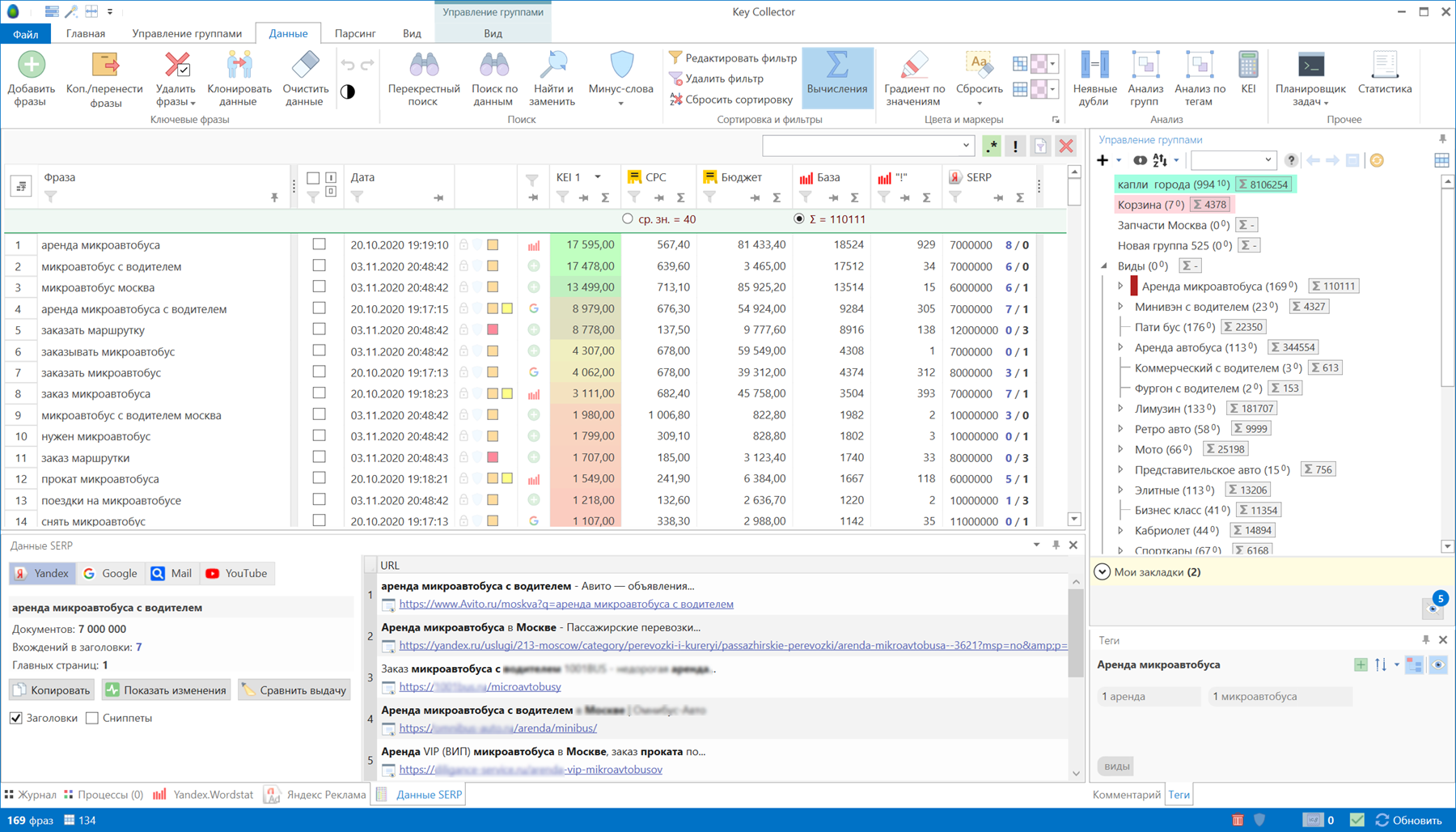
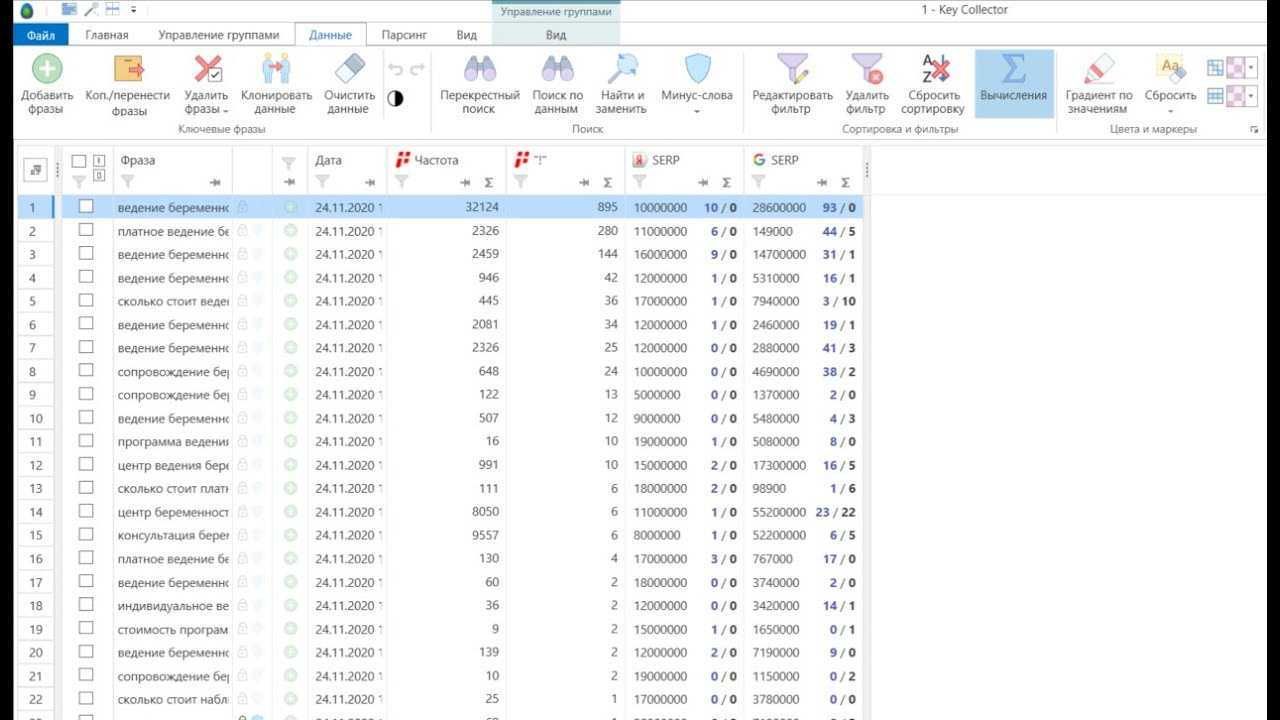
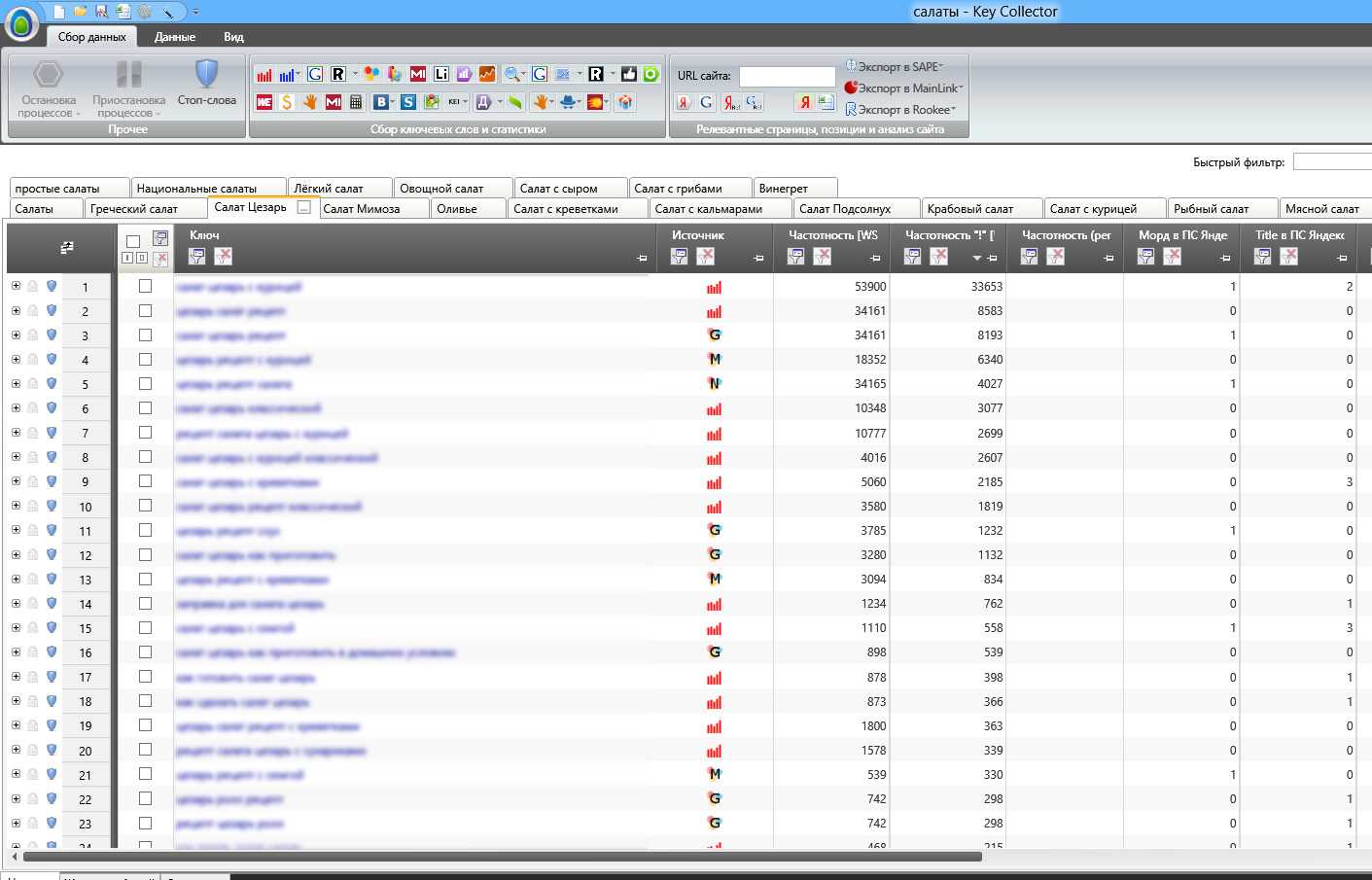
Зачем собирать семантическое ядро?
Семантическое ядро служит упорядочиванию всех поисковых запросов на сайте. Собирать ядро начинают в самом начале продвижения, чтобы актуализировать все ключевые запросы и составить технические задания для будущих SEO-текстов. Зная позиции по определенным запросам, вы можете оперативно приступить к работе над сайтом. После публикации текстов нужно завести проект в сервисе для мониторинга позиций, например, в Topvisor или AllPositions. В этот проект вы загружаете семантическое ядро и регулярно мониторите движение сайта в поисковой выдаче.
Если вы заметите, что высокочастотная фраза подобралась к топу, вы сможете подтолкнуть ее выше, например, с помощью внешней ссылки. Если все получилось, то трафик на сайте заметно вырастет.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Другие функции Кей Коллектора полезные для директолога:
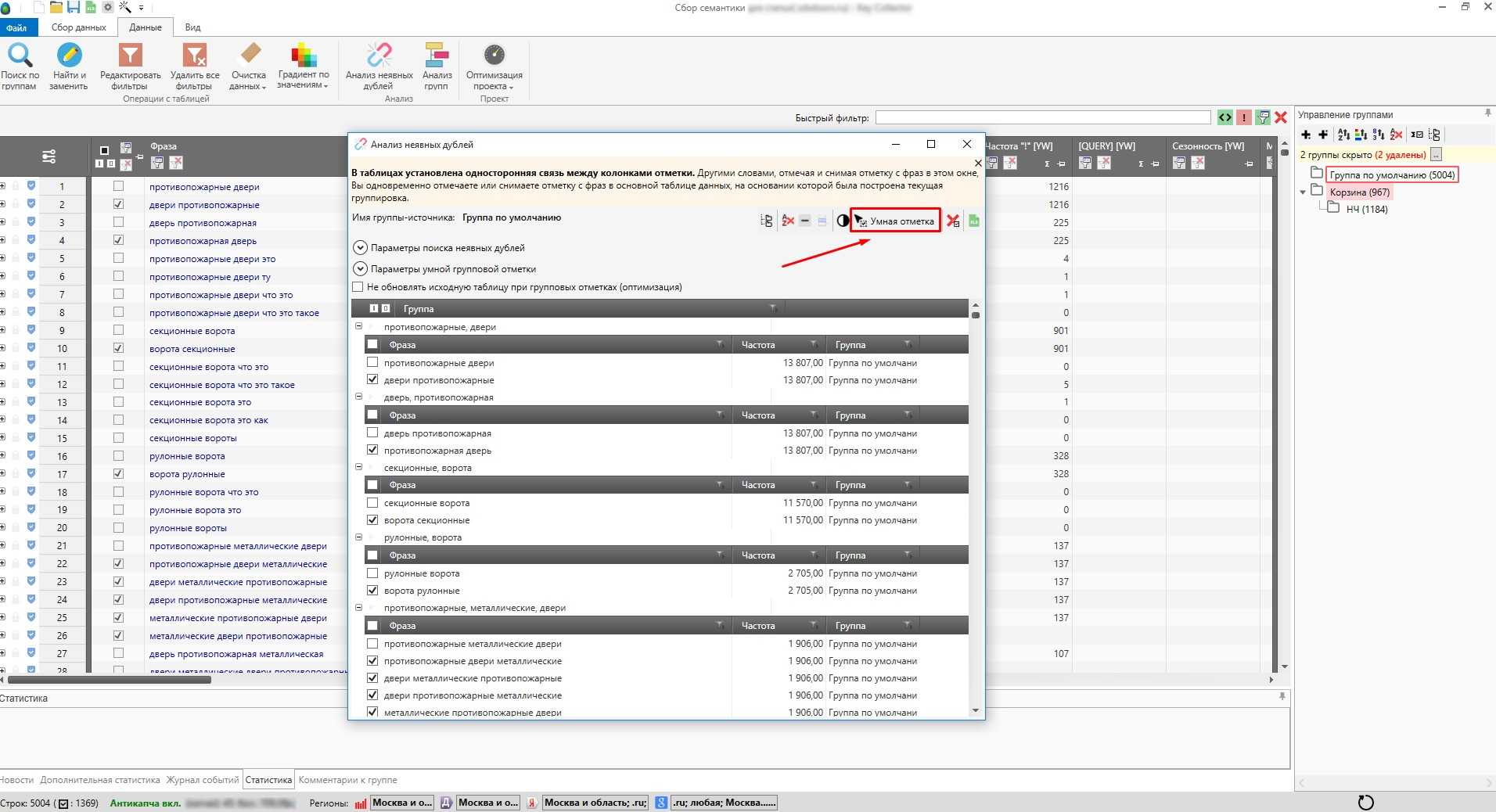
Удаление неявных дублей.
Если перейти во вкладку «Данные», то там будет полезная функция «Анализ неявных дублей», с помощью данной функции вы можете очистить собранное семантическое ядро не только от дублей, но и то неявных дублей. Например: как убрать комнату и как комнату убрать, будут считаться дублями. Программа покажет какие есть дубли, в каких группах, там же есть кнопка «Умная отметка», она автоматом выделяет один из дублей и вы его (или их удаляете), т.е. самостоятельно выделять и удалять дубли не надо, это делается в два клика.
Фильтры.
Каждый столбец в программе имеет самые различные фильтра. Например в столбце «Фразы» по фильтрам можно отыскать нужные ключевые слова, можно найти ключевые слова, которые состоят из определенного числа слов, это удобно при группировки ключей при обходе статуса «мало показов», когда в одну группу помещаются ключи с малой частотностью, но схожие по смыслу и написанию; в столбце «Базовая чистота», можно отфильтровать частотность по любому направлению (все ключи больше или равны 10, или меньше 5 и т.д.).
Быстрое составление списка минус слов.
Для того, чтобы максимально комфортно собрать полный список минус слов, достаточно выделить все ключевые слова, кликнуть правой кнопкой мыши на них и выбрать «Отправить выделенные фразы в окно стоп-слов». После этого откроется список со всеми выделенными ключами, где отмечая нужные слова далее их помещаем в список минус-слов.
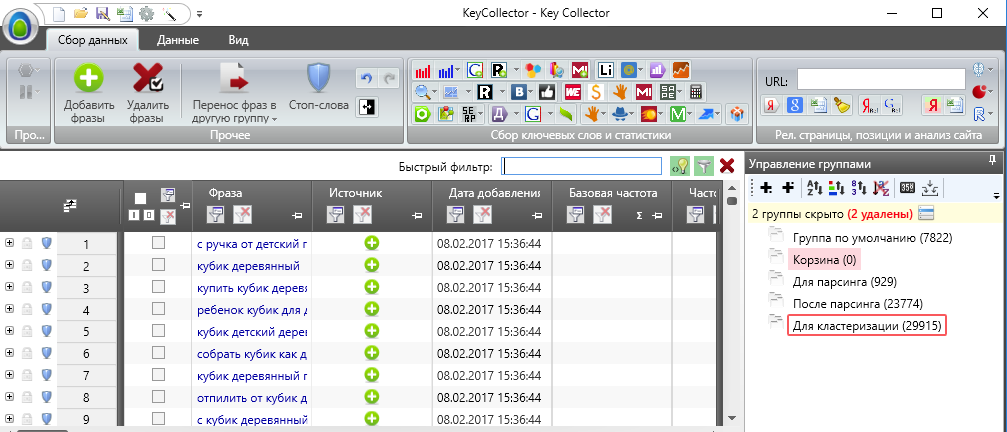
Режим мульти-группы.
Для того, чтобы выгрузить полученное семантическое ядро в единый эксель файл, или применить на все группы (папки) ключей минус слов и т.д. и т.п. необходимо сначала выделить все папки, и нажать на мульти-группы, и только тогда все папки как-бы объединяться в одну. Например: у вас много папок, и вы хотите выгрузить полное семантическое ядро в один единый файл в формате эксель. Если просто выделить все папки, то в эксель отправиться лишь одна папка, а для выбора и работы со всеми папками, как раз и нужен режим мульти-группа:
Сбор частотности ключевых слов.
Другие поисковые системы и рекламные сети
В этой статье я рассматривал наиболее популярную область применения Коллектора – парсинг с Yandex.Wordstat. Если вы хотите использовать это приложение для сбора семантического ядра с каких-то других поисковых систем или рекламных сетей, то вам также придется настраивать каждый отдельный пункт.
Возможно, в будущем появится отдельная статья о подробной настройке каждого пункта этой замечательной утилиты, но если вам невтерпеж, то вы можете воспользоваться официальным мануалом от разработчиков. В нем достаточно подробно рассматриваются аспекты настройки Adstat Rambler, LiveInternet, Google AdWords и других. Обязательно ознакомьтесь с представленным материалом.
Играемся с интерфейсом
По умолчанию в таблице Key Collector’а находится более 50 столбцов, большая часть которых, обычно, вообще пустует, а потому только мешает. Что делать?
Ответов на этот вопрос может быть несколько.
Пожалуй, самый оптимальный вариант – зайти на вкладку Вид и кликнуть на «Автонастройку видимости колонок». Как видите, пустые колонки просто скрылись.
Плюс в том, что Вам больше не будут мешать столбцы с пустыми данными. Минус – столбцы, которые ЗАПОЛНЕНЫ данными тоже иногда могут мешать, т.к. эти данные в данный момент могут быть и вовсе не нужны. Что делать? Правильно – сделать несколько собственных шаблонов «под себя» и при необходимости менять их.
И начнём с сохранения шаблонов. Если взглянуть на скриншот выше, то у нас получился практически готовый шаблон на рекомендации по внутренней перелинковке. Именно так мы его и сохраним.
Теперь давайте его чуточку подправим, удалив столбец с датой добавления и столбец с указанием источника добавления. Для этого кликаем на настройку столбцов, листаем список и убираем лишние галочки.
Как видите, таблица снова видоизменилась. Если такой вариант больше устраивает – его вполне можно сохранить как шаблон (причем вместо уже имеющегося).
Теперь давайте сконструируем шаблон, в котором будут отображаться только частоты по Яндексу. Снова заходим в настройки, удаляем столбец с УРЛ и открываем столбцы с частотами.
Да, столбцы на данный момент пустые, но это временно и в данном случае неважно. Важно другое
Мы удалили из таблицы столбец с УРЛами, которые получили в качестве рекомендованных акцепторов для перелинковки. И, несмотря на то, что столбец удалён, данные никуда не потерялись. Т.е. если столбец восстановить, то и собранные данные тоже восстановятся.
Таким образом, Вы можете сделать «под себя» несколько шаблонов и переключаться между ними по мере необходимости. В крайнем случае у Вас всегда есть возможность настроить отображение ВСЕХ столбцов.
Как проверить частотность запросов
Частотность будет отображаться сразу в окне с результатами поиска. Но ключевые фразы не отсортированы по этому показателю. Следовательно, чтобы отобрать только подходящие варианты, необходимо выполнить несколько несложных действий.
В окошке со списком ключей на верхней панели следует нажать на значок с изображением увеличительного стекла, обозначающий запуск поиска. Из предложенных вариантов сортировки нужно выбрать «Собрать частотности » «». Этот пункт поможет выделить самые эффективные ключевые запросы.
После завершения сбора частотности остается удалить фразы, для которых этот показатель равен нулю (настройках фильтрации). Тут несложно установить необходимые для эффективного отбора параметры. Удобно выбрать и опции упорядочивания ключевых слов по возрастанию или убыванию показателя их частотности.
Как парсить ключи для Гугл
Ключевые слова для Google собираются по аналогичному принципу работы с Яндексом. Для этого вам необходимо создать несколько аккаунтов для Google Аналитики и AdWords. Затем для сбора запросов вам понадобится:
-
Кликнуть на данную иконку:
- В образовавшимся окне ввести основные фразы.
- Начать поиск схожих запросов.
В данном окне вы сможете задать нужные настройки именно для Гугл, при необходимости. Если у вас возникнут вопросы, кликните на иконку вопросительного знака, чтобы всплыла информационная справка.
В результате у вас должна возникнуть схожая структура по выдаче запросов из AdWords. Затем можете приступать к работе с семантикой.
Что такое Key Collector?
Кей Коллектор – это платная утилита, которая повсеместно используется сеошниками и маркетологами. Суть ее состоит в почти полной автоматизации сбора семантического ядра. Приложение тесно интегрировано с Яндекс Директом, Вордстатом, гугловскими сервисами и прочими инструментами, которые поодиночке не выглядят такими практичными.
То есть Key Collector объединяет в себе несколько сервисов, интегрируя их возможности. Это позволяет людям легко и просто парсить запросы с того же Вордстата или Директа, в последствии превращая их во вполне себе обоснованное семантическое ядро.
Как я уже сказал, чтобы пользоваться программой, ее придется купить. Разработчики очень сильно заботятся о сохранении лицензии, поэтому каждая отдельная программа привязывается к одному персональному компьютеру с помощью идентификатора жесткого диска. Следовательно, вы не сможете скачать приложение, чтобы использовать его на нескольких машинах – 1 лицензия для 1 компьютера.
В интернете, конечно, есть взломанные версии, которые якобы предоставляют те же возможности, что и оригинал. Однако стоит учитывать, что через пиратское ПО очень часто распространяются вирусы
Если уж вы не хотите покупать Коллектор, то я бы рекомендовал вам обратить внимание на СловоЁб. Это бесплатное приложение от тех же разработчиков, которое представляет собой урезанный вариант Коллектора
Теперь давайте более подробно рассмотрим возможности программы. Итак, как заявляют разработчики, с помощью Key Collector мы сможем составить более точное семантическое ядро, не прибегая к помощи сторонних специалистов. Нам лишь нужно правильно настроить все параметры и познать некоторые азы.
Надо сказать, что Key Collector не работает с готовыми базами данных, которые требуют постоянные обновления. Он парсит всю информацию в реальном времени через интернет, подключаясь ко все тем же сервисам: Вордстат, Яндекс Директ, Гугл Адвордс и прочим. Такой подход гарантирует вам актуальность всех ключей, которые вы получите на выходе.
Эта программа поможет вам увидеть наиболее популярные страницы вашего сайта, определить верную стратегию продвижения, основываясь на статистических данных. В конечном итоге вы можете выгрузить всю информацию в удобный формат, например, в таблицу Excel.
Я уверен, что купить программу определенно стоит. Если понять, как работать, то это может сэкономить существенную часть финансов и времени. Да и проекты с качественной семантикой будут давать больше отдачи, что также является плюсом.
Собираем стартовые ключи
Полученный список конкурентов заносим в таблицу, он еще пригодиться для дальнейшего продвижения проекта.
Проанализировав структуру каждого сайта, мы видим, что она у всех одинаковая. А все целевые запросы, типа курсовая, дипломная, реферат, находится разделе “Услуги”.
Таким образом из структуры сайта конкурентов мы получаем стартовые ключи, которые дальше нужно распарсить.
 Типы студенческих работ
Типы студенческих работ
Далее… С нулевым бюджетом и стартовыми ключами можно пойти в Яндекс Вордстат, взять Excel или Google Таблицы, и закопаться еще на месяц — другой в ручной работе. Кто собирал семантику таким образом знает
Поэтому чтобы ускорить процесс я купил себе Key Collector 4. Стоит это удовольствие всего 1800 рублей. Лицензия покупается один раз, и на всю жизнь. Основной плюс — отсутствие ежемесячной подписки.
В нем можно собирать семантику и делать кластеризацию. А еще мониторить позиции и много, много чего полезного. Главное, разобраться как!
Первичный сбор частотности ключевых фраз
Вернемся к нашей карте мыслей и нашим пересечениям запросов.
Сейчас требуется скопировать все пересечения и добавить их в key collector.
Для этого создаем новый проект.
Создание проекта в Кей Коллектор
В открывшемся окне переходим во вкладку «Сбор данных» и нажимаем на кнопку «Добавить фразы»
Вставляем полученные фразы при пересечении запросов из карты мыслей.
Жмём кнопку «Добавить в таблицу»
Добавление ключевых фраз в Key Collector
Нажимаем на значок директа (Сбор статистики Яндекс Директ)
В открывшемся окне задаем требуемый регион.
Проверяем наличие галочки в пункте «Целью запуска сбора статистики является заполнение колонок частот Yandex.Wordstat»
И нажимаем получить данные.
Настройки сбора частотности через Яндекс Директ
Первичный сбор статистики производить лучше именнотаким образом, так как этот метод гораздо быстрее, чем сбор статистики с помощью только одного wordstat.
Для увеличения скорости сбора семантического ядра, изначально требуется отбросить заведомо пустые запросы, чтобы лишний раз не обращаться к серверу яндекс вордстат при парсинге, что существенно экономит время.
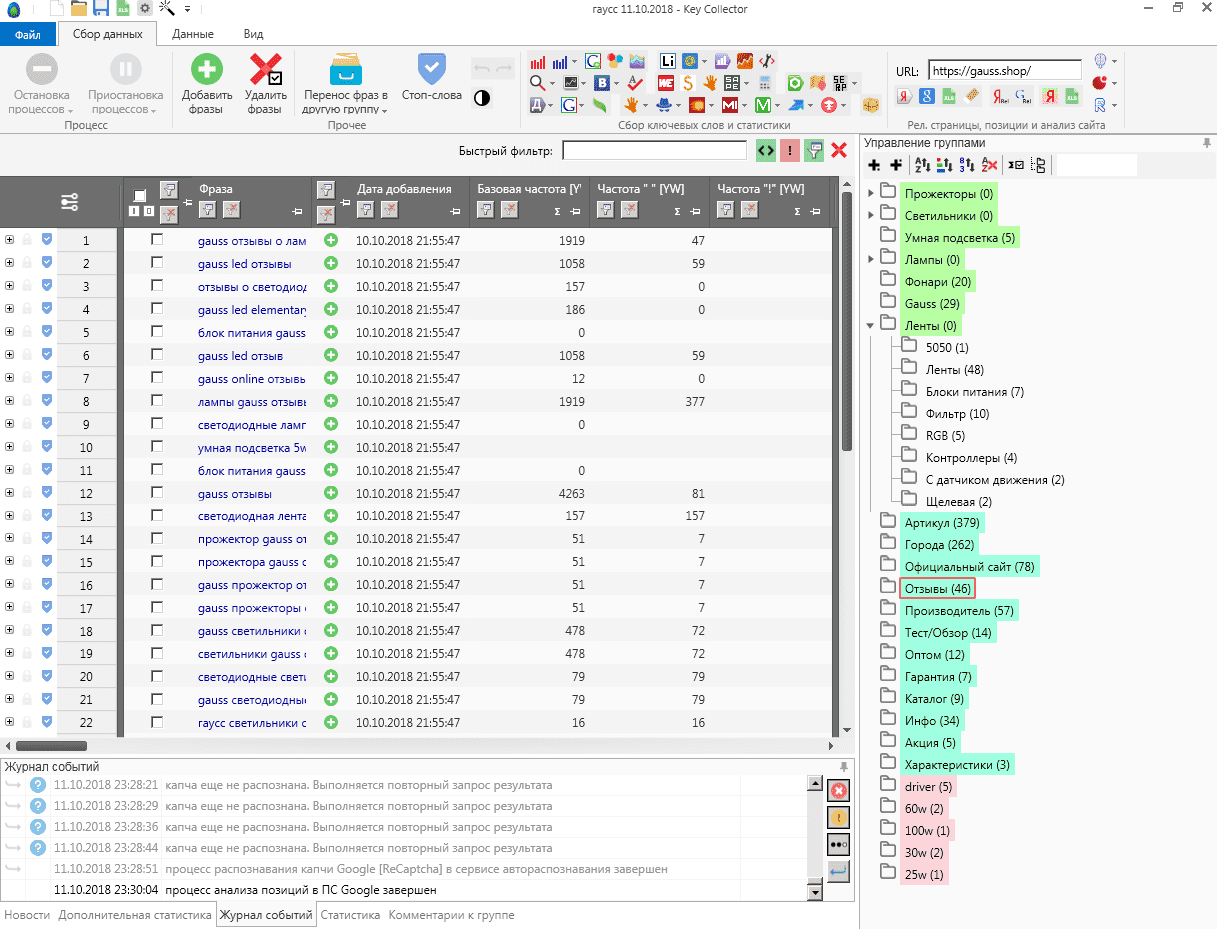
На скриншоте с Журнала событий Key Collector отчетливо видно, что сбор занял всего минуту при 1 аккаунте. Было проверено 42 слова и большую часть из этого времени заняла авторизация.
Скорость сбора статистики в Кей Коллектор
После сбора статистики в столбце «Базовая частота » появится число отражающие количество запросов в заданном регионе за месяц.
Далее требуется отсечь те слова, у которых по этой статистике 0 запросов.
Для этого их надо отфильтровать, нажимаем на значок воронки (фильтр) рядом с названием столбца.
В открывшемся окне, выбираем условие отображения «Больше» 0.
И нажимаем «Применить».
Настройки фильтра в Key Collector
Перед нами все фразы с частотность больше нуля.
Скопируем их.
Для этого правой клавишей мыши щелкаем по названию столбца и жмем «Скопировать колонку в буфер обмена»
Копирование слов из Key Collector
Готово! Теперь можно перейти к самому важному — Парсингу.
Парсинг запросов
Первым делом создаем новую папку, комбинацией shift+t или нажатием на значок плюса в меню с группами.
Новая папка для парсинга
Для добавления скопированных ранее слов в парсинг, нажимаем на «Пакетный Сбор слов из левой колонки Yandex.Wordstat» (Красный значок статистики).
Проверяем, что не установлено отслеживание повторов.
Парсинг запросов из левой колонки Wordstat
Вставляем слова в открывшееся окно и нажимаем кнопку «Начать сбор»
Парсинг в Key Collector.png
Вот и всё, ждем окончания парсинга и продолжаем работа.
После сбора семантического ядра потребуется разгруппировать и отобрать минус слова.
Способ 2. «Вордстат» и таблицы
Недостатки способа: Сложно обрабатывать более 1000 ключей, риск собрать не все.
Этап 1. Сбор основных масок
Он заключается в том, что мы выбираем самую ВЧ маску и собираем все ключи по ней.
В нашем случае мы возьмем маски «Токарный станок» и «Токарка».
Обратите внимание на то, что мы не берем маску «Станок», потому что это очень широкая маска и нам придется очень много чистить мусора. А если возьмем маску «Токарно-винторезный станок», то пропустим много целевых запросов
Поэтому используйте самую широкую подходящую маску.
Этап 2.Сбор основных масок
Не забудьте указать регион, по которому вы хотите собрать семантику
Это важно! Если вы соберете семантику по всей России, а показывать рекламу будете для жителей небольшого городка, то можете получить статус «мало показов» и пользователи вашу рекламу не увидят. Да и много лишнего придется минусовать
Поэтому собирайте семантику в том регионе, где хотите показывать рекламу.
Теперь, когда все настроено, вы можете собрать семантические ядро.
Если вы собираете по нескольким широким маскам, то просто вводите запрос и добавляете все запросы из левого столбца. Вносите со всех страниц, пока частотность не будет меньше 10 запросов.
Но если ключей много, вы можете недолистать до запросов с частотностью менее 10, потому что статистика показов ограничена 41 страницей.
Чтобы собрать всевозможные хвосты, на первых 10-20 страницах кликайте на запрос, чтобы Wordstat показал его хвосты.
И обращайте внимание на запросы из правой колонки. В этой колонке содержатся запросы, которые ищут вместе с тем, который вы ввели
Поэтому там могут быть широкие маски, которые мы могли не учесть.
После того как закончили сбор семантического ядра, скопируйте в буфер обмена запросы с их частотностью и вставьте на лист таблицы.
Этап 3. Удаляем мусорные запросы.
Теперь вам нужно, прочитывая каждую фразу, искать нерелевантные слова и выписывать их в соседний столбец.
По окончании выделите все столбцы и отсортируйте по столбцу с минус-словами.
После скопируйте очищенную семантику на отдельный лист, а в столбце с минус-словами удалите дубли. В итоге у вас должен остаться лист с минус-словами и лист с чистой семантикой.
Этап 4. Группировка ключевых запросов.
Чтобы разгруппировать вручную, вам придется просматривать все очищенные запросы в таблице и окрашивать их в цвет группы. Чтобы ускорить этот процесс, я через фильтр по условию «Текст содержит» ввожу слова, которые бы характеризовали всю группу, и окрашиваю их в цвет группы.
После сортирую по цветам, а оставшиеся незакрашенные группы сортирую вручную.
Импорт собранных данных в Key Collector
Key Collector предоставляет удобный способ импортировать собранные данные из других инструментов или сервисов. Этот функционал позволит вам экономить время и эффективно использовать уже существующую информацию.


Чтобы импортировать данные, необходимо выполнить следующие шаги:
Подготовьте данные для импорта. Убедитесь, что ваши данные сохранены в поддерживаемом формате, таком как CSV или Excel
Обратите внимание на структуру данных и убедитесь, что она соответствует требованиям Key Collector.
Откройте Key Collector. В левом меню найдите раздел «Импорт данных» и выберите соответствующий пункт.
Выберите источник данных для импорта
Вам будет предложено выбрать формат данных (CSV, Excel и т. д.) и указать путь к файлу, который вы хотите импортировать.
Настройте параметры импорта. Key Collector предоставляет возможность настроить различные параметры импорта, такие как выбор нужных столбцов данных, пропуск заголовков и другие.
Начните процесс импорта. После настройки параметров нажмите кнопку «Импортировать», чтобы начать процесс импорта данных в Key Collector.
После завершения импорта вы сможете увидеть свои данные в интерфейсе Key Collector и использовать их для проведения анализа, настройки фильтров и других действий.
Убедитесь, что вы понимаете структуру данных и требования Key Collector перед началом импорта, чтобы избежать проблем и сэкономить время на дальнейших корректировках.
Key Collector – обзор мощнейшего инструмента для SEO, часть 2
Итак, продолжаем разбирать программу KeyCollector. В прошлой части мы достаточно много внимания уделили сбору семантического ядра и его очистке
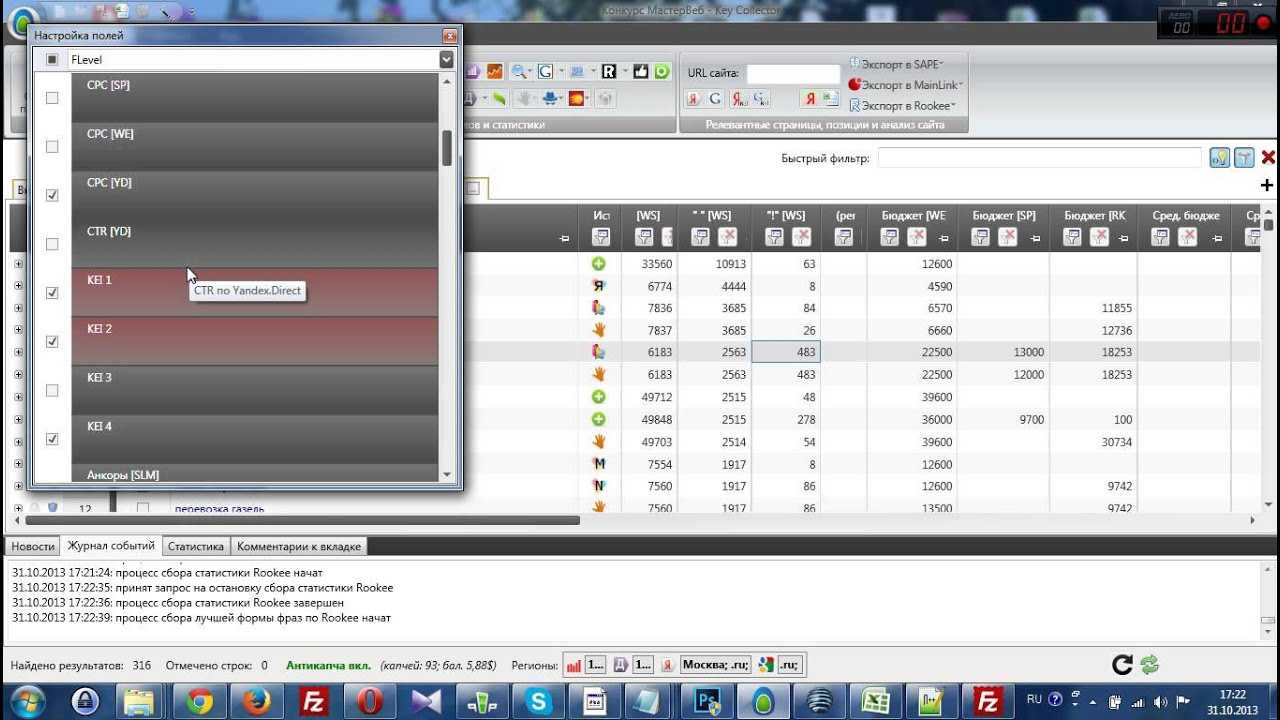
В этой же части мы уделим большое внимание формулам KEI
Для тех, кто не в курсе, KEI расшифровывается как Keyword Effectiveness Index, т.е. индекс эффективности ключа. Хотя, если посмотреть правде в глаза, то формулы KEI можно конфигурировать как угодно, т.е. какого-либо универсального рецепта формулы здесь нет и быть не может.
Для начала давайте рассмотрим, где вообще хранятся формулы для вычисления KEI. Заходим в Настройки – KEI & SERP и видим вот это:
Здесь мы видим 4 поля, в которых хранится одна и та же «штатная» формула для расчета KEI. Справа от этих четырех полей есть 4 калькулятора, с помощью которых можно вычислить KEI не по всем формулам сразу, а по какой-то одной конкретной формуле.
Данные, полученные в результате вычислений, выводятся в таблицу в соответствующие колонки:
Чуть ниже мы будем рассматривать несколько формул и у Вас наверняка возникнет вопрос, «А откуда Вы переменные-то берёте? И откуда Вы знаете, какая переменная за что отвечает?». Вот отсюда:
Сколько стоит Key Collector
Стоимость зависит от того, на каком количестве компьютеров или рабочих мест вам нужно установить и активировать программу.

Допустим, она нужна четырем сотрудникам. Вы покупаете 4 лицензии: первая обходится в 1 800 рублей (при электронном расчете), вторая, третья и четвертая – уже по 1 400 каждая.
P.S. В этой статье мы затронули только те функции сервиса Key Collector, без которых не обойтись при настройке контекстной рекламы. Помимо комплексной работы с ключами Key Collector также работает с содержимым сайта, проводит экспресс-анализ на соответствие семантике и дает рекомендации по внутренней перелинковке.
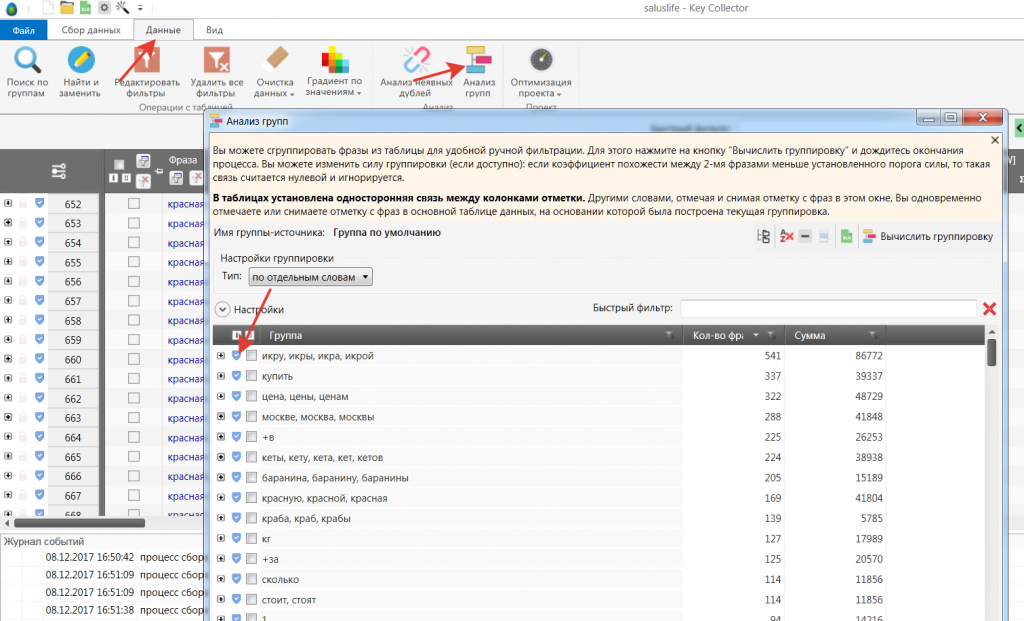
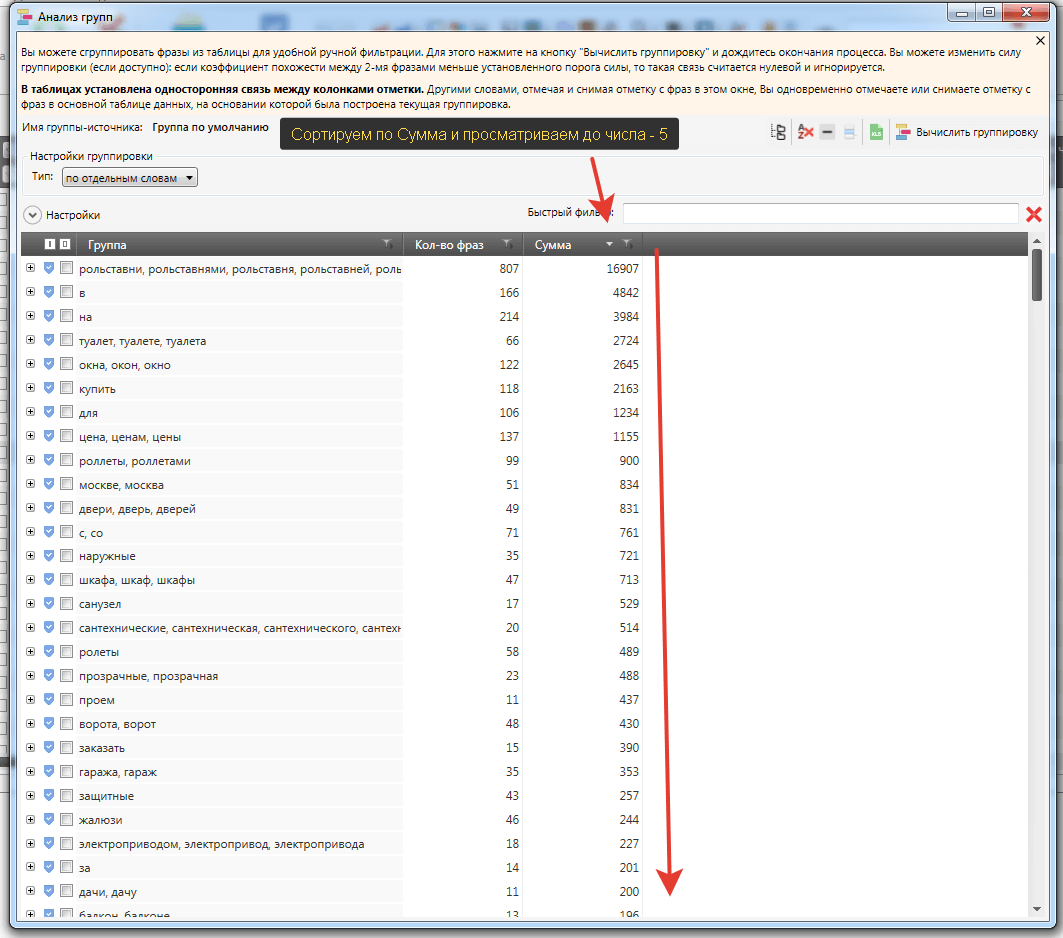
Кластеризация в Key Collector 4
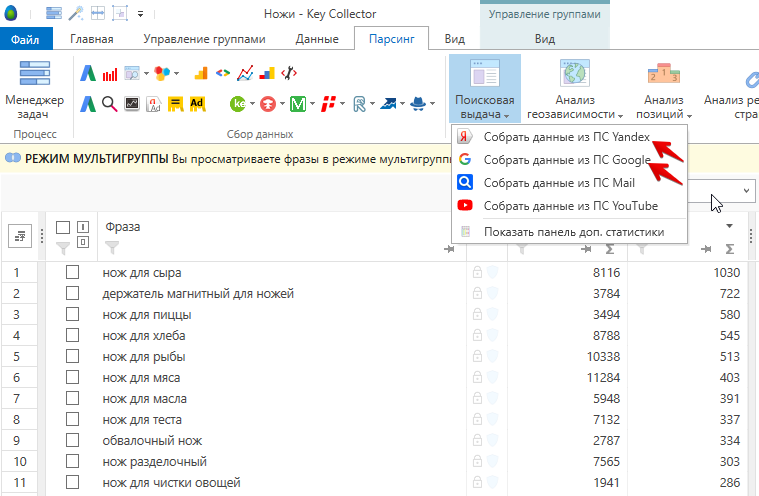
1. Для кластеризации нам нужно собрать данные по SERP. Переходим во вкладку Парсинг — Поисковая выдача — “Собрать данные из ПС Яндекс”
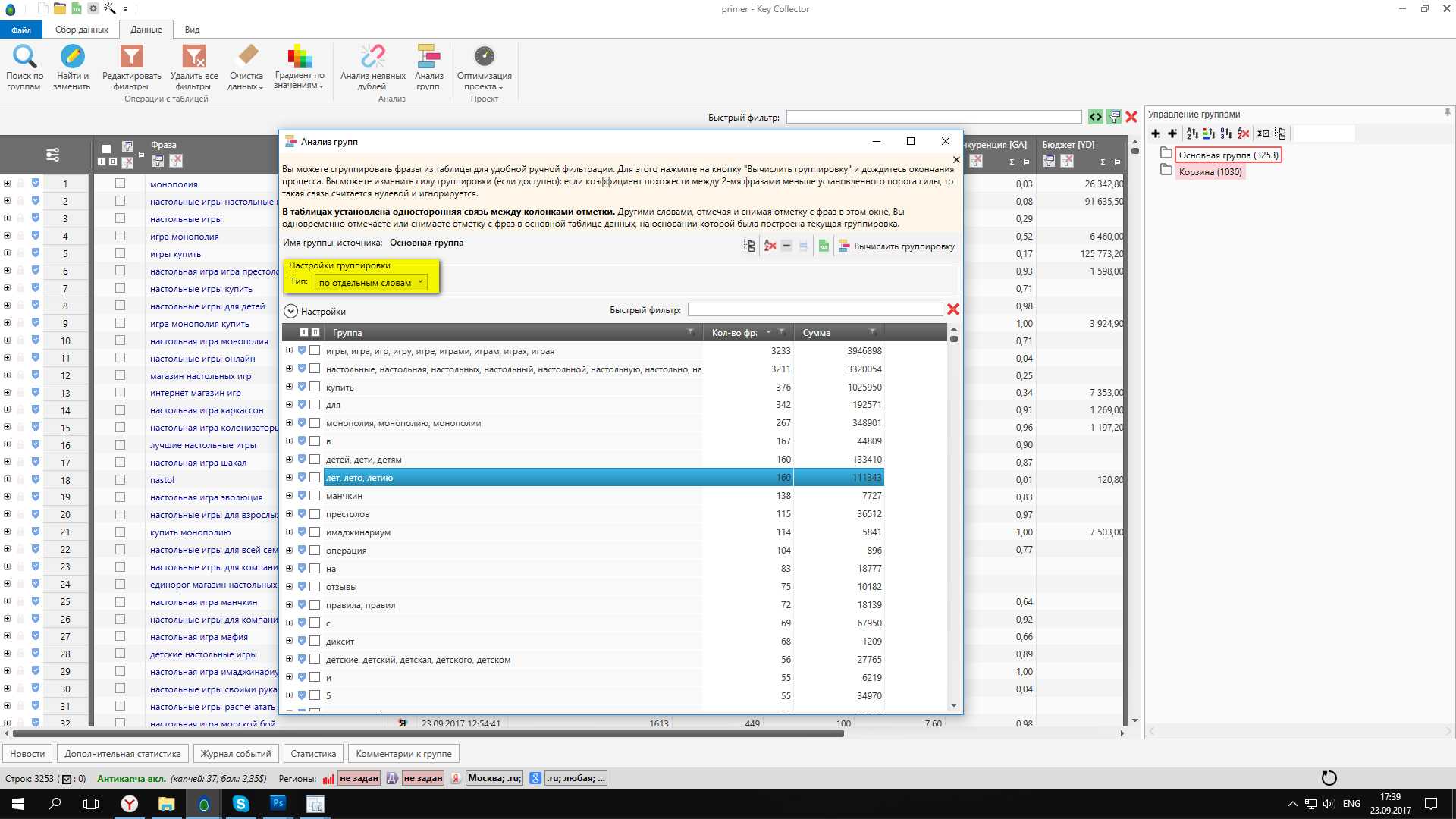
2. Когда данные по SERP будут спаршены. Переходим во вкладку данные — “Анализ групп” по поисковой выдачи v3.
В колонке “Сумма” выбираем точную частотность. Режим группировки “Пересечение”. Сила группировки 4, размер группы 3. Также ставим галочки напротив всех настроек. Нажимаем “Начать анализ”.
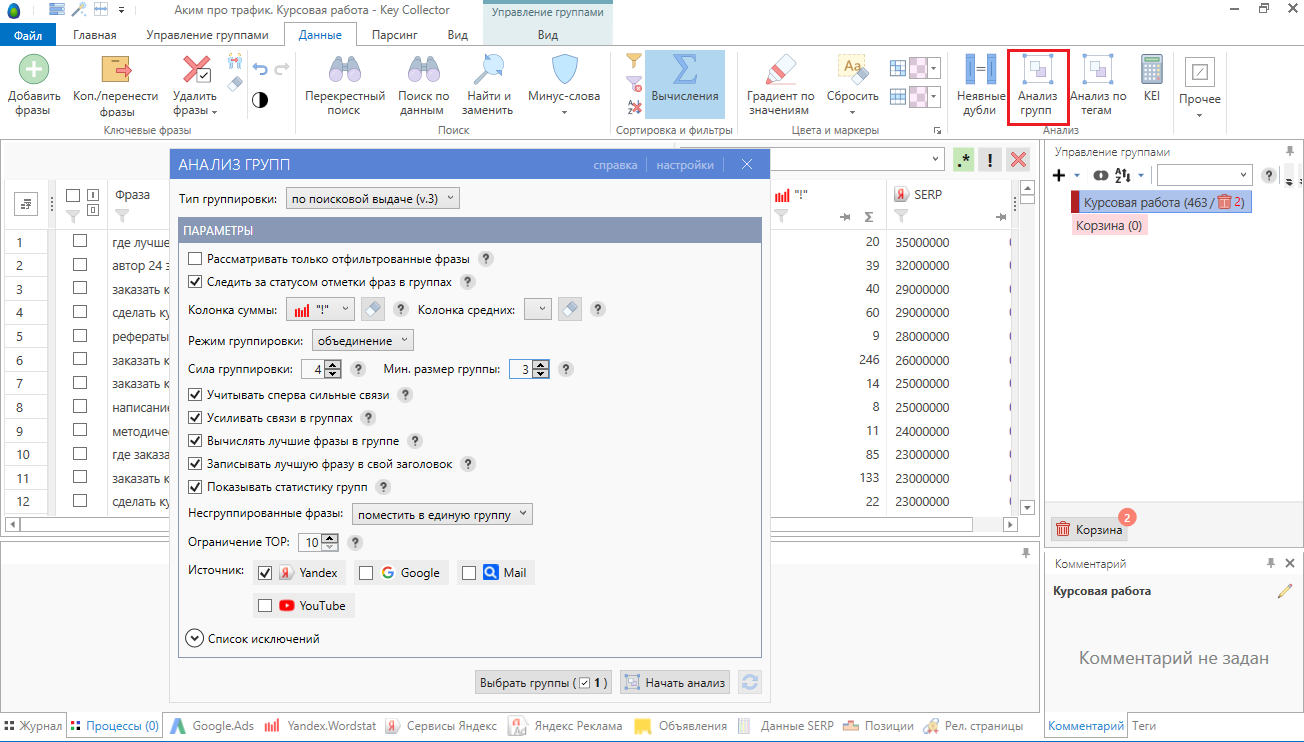
3. По завершению анализа у нас есть готовая кластеризация. Благодаря данным SERP. Кейколлектор сгруппировал запросы. Теперь их нужно пересмотреть на предмет интента и пересечения в выдачи. А потом создать структуру.
Вот неплохой видео мануал по кластеризации в кей коллектор 4.
Да нужно потратить свое время, чтобы изучить данный софт. Да нужно купить расходники в виде прокси и капчи. Но зато нет ежемесячной подписки. А когда вам нужно собрать или кластеризовать семантику, вам это легко сделаете здесь и сейчас, без регистрации и смс*
Структура для сайта
Благодаря группировке у меня появилась структура для страницы Услуг: “Курсовая работа”. Теперь можно писать ТЗ для копирайтеров. Хотя скорее всего, тексты я буду писать сам.
Доброго времени и спасибо за внимание!
Чистка семантического ядра в Key Collector
Чистка в Key Collector — это один из самых важных этапов. Нужно удалить мусорные запросы и постараться оставить целевые запросы, по которым будем рекламироваться. Большинство людей на этом этапе совершают различные ошибки. Вам в любом случае их не избежать, но если соберете 10 семантик и почистите, то процесс запомнится и уже будет не так сложно. Для начала нам нужно очистить список шаблонными минус-словами и городам, берем весь список и вставляем в стоп слова. Дальше нажимаем «Отметить фразы в таблице». Прежде, чем что либо удалять, убедимся, что мы удаляем только мусорные запросы, для этого сортируем по базовой частоте. Нам необходимо пройтись по списку и посмотреть, что мы удалили нужного. Нашли? Теперь удаляем это слово из списка стоп слов через поиск.
После того, как удалили некоторые минус-слова, нужно снять отметку и по новой отметить фразы. Оставшиеся фразы переносим в корзину. Не забудьте после этого удалить все фильтры.