

Part 1: Loading Web Pages with ‘request’
This is the link to this lab.
The module allows you to send HTTP requests using Python.
The HTTP request returns a Response Object with all the response data (content, encoding, status, and so on). One example of getting the HTML of a page:
Passing requirements:
- Get the contents of the following URL using module: https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/
- Store the text response (as shown above) in a variable called
- Store the status code (as shown above) in a variable called
- Print and using function
Once you understand what is happening in the code above, it is fairly simple to pass this lab. Here’s the solution to this lab:
Let’s move on to part 2 now where you’ll build more on top of your existing code.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
Сканер
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Common Challenges in Web Scraping
With the growing use of web scraping, people are also facing several problems in the process. This web scraping tutorial highlights the top four challenges that people commonly face while scraping websites.
Honeypots
In several cases, website developers install traps called honeypots, where scraping tools are not able to crawl and detect information. These honeypots are either color-disguised on the webpage or nested under “display:none” CSS (Cascading Style Sheet) tags.
Data Warehousing
Improper data storage infrastructure can downgrade the outcome of web scraping. For large-scale web scraping projects, it is important to facilitate scalable data warehousing.
Anti-Scraping & Crawler-Hostile Technologies
Dynamic coding algorithms disable scraping activities. Websites such as LinkedIn and Facebook use these algorithms to block scraping tools. These websites are also built on JavaScript technologies that create a hostile environment for web crawlers and scraping bots.
Changes in Website Structures
A simple change in website structure can create multiple changes in the outcome of web scraping processes. Hence, the scrapers are required to find the correct field and develop a relevant logic depending on the current website structure.
Which is the best tool for web scraping? There are several tools used for web scraping. Some of the best web scraping tools available to us are Dexi.io, Web Harvey, Apify SDK, Mozenda, Octoparse, PySpider, Content Grabber, and Cheerio.
Final Thoughts
In this web scraping tutorial, we understood the meaning of the web scraping process. We learned how the process works and why is it important to extract information from web pages. We also looked at the web scraping methods implemented with Python and Ruby programming languages. After going through this web scraping tutorial, consider collecting specific data from any targeted website of your choice and try to structurally organize it in the output file.
We hope our web scraping tutorial for beginners serves as a comprehensive guide for you. With our Python web scraping tutorial and web scraping with R tutorial, you can easily track your company’s performance and gain crucial insights about it.
Join the Python Programming Course and start your career as a Data Scientist.
If you’d like to get more information on some concepts of web scraping, leave your queries in the comments below.
Data Scraping with dynamic web queries in Microsoft Excel
Setting up a dynamic web query in Microsoft Excel is an easy, versatile data scraping method that enables you to set up a data feed from an external website (or multiple websites) into a spreadsheet.
Watch this excellent tutorial video to learn how to import data from the web to Excel – or, if you prefer, use the written instructions below:
- Open a new workbook in Excel
- Click the cell you want to import data into
- Click the ‘Data’ tab
- Click ‘Get external data’
- Click the ‘From web’ symbol
- Note the little yellow arrows that appear to the top-left of web page and alongside certain content
- Paste the URL of the web page you want to import data from into the address bar (we recommend choosing a site where data is shown in tables)
- Click ‘Go’
- Click the yellow arrow next to the data you wish to import
- Click ‘Import’
- An ‘Import data’ dialogue box pops up
- Click ‘OK’ (or change the cell selection, if you like)
If you’ve followed these steps, you should now be able to see the data from the website set out in your spreadsheet.
The great thing about dynamic web queries is that they don’t just import data into your spreadsheet as a one-off operation – they feed it in, meaning the spreadsheet is regularly updated with the latest version of the data, as it appears on the source website. That’s why we call them dynamic.
To configure how regularly your dynamic web query updates the data it imports, go to ‘Data’, then ‘Properties’, then select a frequency (“Refresh every X minutes”).
Инструменты для веб‑скрейпинга
Часто программисты пишут конкретных ботов с конкретными функциями под конкретную задачу, но есть и более простые, специализированные инструменты для веб‑скрейпинга. Мы расскажем именно о них.
Большинство сервисов работают по одной и той же схеме: нужно зарегистрироваться и подтвердить адрес электронной почты, а затем можно начинать скрейпить.
Сам скрейпинг прост в управлении: нужно ввести адрес сайта и выбрать элементы, которые необходимо собрать. Приложение сделает всё за вас и даст возможность посмотреть результаты в читаемом формате. Весь процесс проходит онлайн.
Некоторые сервисы предлагают скачать их API (программу) для скрейпинга. Как правило, на сайте приложения всегда есть инструкция по установке и использованию.
Некоторые сервисы предлагают персональные решения — они сделают всю работу за вас. Для этого надо связаться с менеджментом конкретной компании.
ScraperAPI
Бесплатное расширение для Chrome. Можно собирать разные типы данных и экспортировать их в CSV, XLS или JSON.





![Python web scraping tutorial: step-by-step [2024 guide]](https://triathlon21.ru/wp-content/uploads/1/4/f/14f2f88e5c75dcf0282c6bc3e0833bd3.jpeg)



Octoparse
Сервис с бесплатным тарифом для небольших проектов; для более сложных — от 75 долларов в месяц. Позволяет скачивать данные и хранить их в облаке, работает на Mac и Windows.
Xtract.io
Обеспечивает ротацию IP и проходит CAPTCHA. Есть демоверсия — её нужно запросить на сайте.
ParseHub
Десктопная программа. Выберите данные, которые нужно собирать, и ждите. Данные можно выгрузить в формате JSON, Excel и API.
Бесплатно можно получить 200 страниц с данными. Платные тарифы начинаются от 189 долларов в месяц.
Mozenda
Сервис позволяет скрейпить одновременно несколько типов данных, формируя их в задачи и выполняя поочерёдно. Можно сделать шаблон для быстрого сбора однотипных данных. Есть 30‑дневный бесплатный пробный период.
ScrapingBot
Сервис скрейпинга сайтов и соцсетей. Для каждого типа данных — например, сырого HTML, информации с сайтов недвижимости или торговли — предоставляются разные API, они специализированы для определенного сектора.
Например, API для скрейпинга сырого HTML извлекает HTML‑код страниц. API для ритейла позволяет просматривать страницы товаров и извлекать цены, описания и прочее. API для недвижимости даёт возможность просматривать площадь, местоположения, цены.
Задачи в приложении оплачиваются кредитами — в бесплатной версии у вас будет 100 кредитов. Когда они закончатся, придётся заплатить от 39 евро в месяц за 100 000 кредитов.
Scrapestack
Как и предыдущий, этот сервис предоставляет для скачивания API для скрейпинга. 1 000 запросов — бесплатно, платные тарифы — от 20 долларов в месяц.
Datahut
Здесь решения создаются под каждый конкретный бизнес. Стоимость — от 40 долларов в месяц за один сайт.
Datamam и Grepsr
Как в Datahut, здесь вам подберут персональное решение. Datamam, например, обойдется в 5 000+ долларов за полноценный сбор данных.
Avoiding Anti-Scraping Measures
While there is nothing wrong with moderate web scraping per se (please do not DDoS the server), many site owners are nonetheless not too keen of having their content scraped, and they often employ different anti-scraping technologies to make a scraper’s life more difficult and prevent scraping altogether.
Some of those measures include
- request throttling, where your requests get blocked when you exceed a certain number of requests a second or minute
- a user agent verification, which tries to analyse certain parameters of the request (user-agent, connection fingerprint) to make sure the request was sent by a regular browser
- JavaScript challenges, which require you to solve a computational problem
- CAPTCHAs, which are supposed to be solvable only by people — at least in theory
There are different ways to handle and approach each of them, but the most important factor is trying to lay low and fly under the radar in the first place.
If you like to know more about this subject, I would highly recommend the article Web Scraping without getting blocked.
Part 2: Extracting title with BeautifulSoup
This is the link to this lab.
In this whole classroom, you’ll be using a library called in Python to do web scraping. Some features that make BeautifulSoup a powerful solution are:
- It provides a lot of simple methods and Pythonic idioms for navigating, searching, and modifying a DOM tree. It doesn’t take much code to write an application
- Beautiful Soup sits on top of popular Python parsers like lxml and html5lib, allowing you to try out different parsing strategies or trade speed for flexibility.
Basically, BeautifulSoup can parse anything on the web you give it.
Here’s a simple example of BeautifulSoup:
Passing requirements:
- Use the package to get title of the URL: https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/
- Use BeautifulSoup to store the title of this page into a variable called
Looking at the example above, you can see once we feed the inside BeautifulSoup, you can start working with the parsed DOM tree in a very pythonic way. The solution for the lab would be:
This was also a simple lab where we had to change the URL and print the page title. This code would pass the lab.
Законен ли парсинг веб-страниц?
Прежде чем мы погрузимся в статью, давайте обсудим насущный вопрос: является ли законным копирование информации с кого-то сайта? Разрешен ли веб-парсинг? Не нарушает ли это авторские права? Ну, не совсем.
Веб-парсинг не связан со взломом. Это всего лишь копирование информации, уже доступной для общественности, информации, которую люди могут прочитать, но в более удобном для машины формате. Так что да, это законно. Но есть некие подводные камни.
Хотя парсинг веб-страниц законен, есть ограничения на виды информации, которые можно парсить, и на способы выполнения этой процедуры. В целом, нужно избегать персональных данных и перегрузок сервера. Ваш основной упор должен быть на получение общедоступной информации.
Чтобы лучше понять это, давайте рассмотрим пример: совершенно законно фотографировать на телефон, но съемка секретных мест или конфиденциальных документов может привести к серьезным правовым последствиям.
Извлечение данных с помощью нашего веб-скрапера Python
Наконец-то мы подошли к самой интересной и сложной части – извлечению данных из HTML-файла. Поскольку почти во всех случаях мы извлекаем небольшие фрагменты из разных частей страницы и хотим сохранить их в списке, мы должны обработать каждый небольшой фрагмент, а затем добавить его в список:
Войти в полноэкранный режимВыйти из полноэкранного режима
“soup.findAll” принимает широкий набор аргументов. Для целей этого руководства мы используем только “attrs” (атрибуты). Это позволяет нам сузить поиск, задав утверждение “если атрибут равен X, то…”. Классы легко найти и использовать, поэтому мы будем использовать именно их.
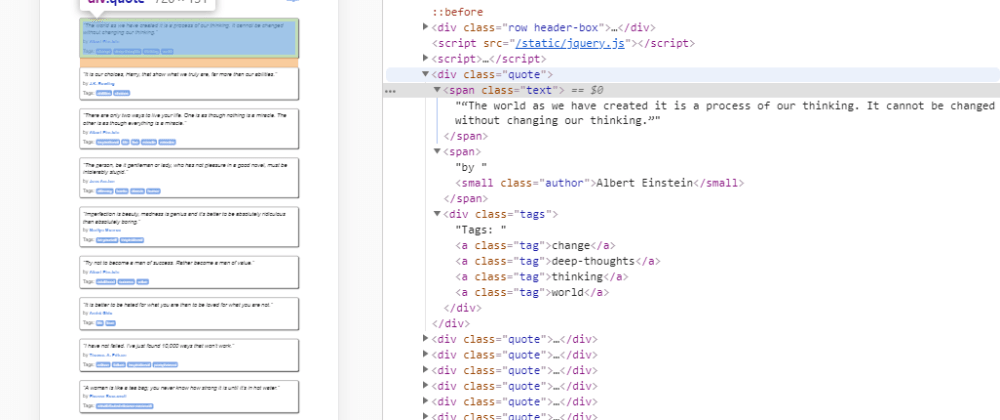
Прежде чем продолжить, давайте посетим выбранный URL в реальном браузере. Откройте источник страницы с помощью CTRL+U (Chrome) или щелкните правой кнопкой мыши и выберите “View Page Source”. Найдите “ближайший” класс, в котором вложены данные. Другой вариант – нажать F12, чтобы открыть DevTools и выбрать Element Picker. Например, данные могут быть вложены как:
Войти в полноэкранный режимВыйти из полноэкранного режима
Тогда наш атрибут “class” будет иметь значение “title”. Если вы выбрали простую цель, в большинстве случаев данные будут вложены аналогично приведенному выше примеру. Сложные цели могут потребовать больше усилий для извлечения данных. Давайте вернемся к кодированию и добавим класс, который мы нашли в источнике:
Вход в полноэкранный режимВыйти из полноэкранного режима
Теперь наш цикл будет перебирать все объекты с классом “title” в источнике страницы. Мы обработаем каждый из них:
Войти в полноэкранный режимВыйти из полноэкранного режима
Давайте посмотрим, как наш цикл проходит через HTML:
Вход в полноэкранный режимВыход из полноэкранного режима
Наш первый оператор (в самом цикле) находит все элементы, соответствующие тегам, атрибут “class” которых содержит “title”. Затем мы выполняем другой поиск внутри этого класса. Следующий поиск находит все теги в документе ( включается, а частичные совпадения, такие как – нет). Наконец, объект присваивается переменной “name”.
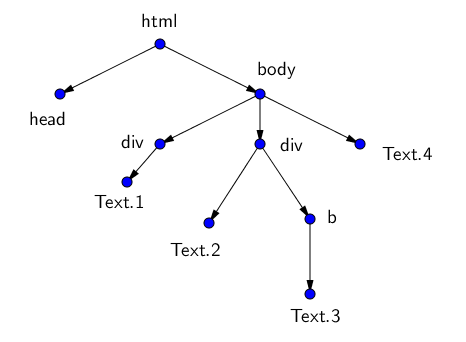









Затем мы могли бы присвоить имя объекта нашему ранее созданному массиву списков “results”, но это привело бы к тому, что весь тег с текстом внутри него оказался бы в одном элементе. В большинстве случаев нам нужен только сам текст без дополнительных тегов.
Наш цикл просмотрит весь источник страницы, найдет все вхождения перечисленных выше классов, а затем добавит вложенные данные в наш список:
Вход в полноэкранный режимВыход из полноэкранного режима
Обратите внимание, что два утверждения после цикла имеют отступ. Циклы требуют отступов для обозначения вложенности
Любой последовательный отступ будет считаться законным. Циклы без отступов выдадут сообщение “IndentationError”, при этом на ошибочное утверждение будет указывать “стрелка”.
What Is The Difference Between Web Scraping & Web Crawling?
Although commonly confused, web scraping is not the same as web crawling.
Web crawling is the process of traversing a website by following links in pages or the sitemap. Oftentimes, indexing the web pages as it goes. Google uses web crawling to index the web, and provides a powerful search engine that can find content anywhere.
Web scraping, on the other hand, is the process of extracting specific bits of data from a target web page and storing it for your own purposes.
The confusion often arises because sometimes developers use a combination of web crawling and web scraping to extract the data they need.
They have a web crawler that traverses a website finding web pages that they want to scrape data from, then use a web scraper to extract the data.
Part 5: Top items being scraped right now
This is the link to this lab.
Let’s go ahead and extract the top items scraped from the URL: https://codedamn-classrooms.github.io/webscraper-python-codedamn-classroom-website/
If you open this page in a new tab, you’ll see some top items. In this lab, your task is to scrape out their names and store them in a list called . You will also extract out the reviews for these items as well.
To pass this challenge, take care of the following things:
- Use to extract the titles. (Hint: one selector for product titles could be )
- Use to extract the review count label for those product titles. (Hint: one selector for reviews could be ) Note: this is a complete label (i.e. 2 reviews) and not just a number.
- Create a new dictionary in the format:
- Note that you are using the method to remove any extra newlines/whitespaces you might have in the output. This is important to pass this lab.
- Append this dictionary in a list called
- Print this list at the end
There are quite a few tasks to be done in this challenge. Let’s take a look at the solution first and understand what is happening:
Note that this is only one of the solutions. You can attempt this in a different way too. In this solution:
- First of all you select all the elements which gives you a list of individual products
- Then you iterate over them
- Because allows you to chain over itself, you can use select again to get the title.
- Note that because you’re running inside a loop for already, the selector would only give you one result, inside a list. You select that list’s 0th element and extract out the text.
- Finally you strip any extra whitespace and append it to your list.
Straightforward right?
Python Web Scraping Tutorial
This web scraping tutorial for beginners also discusses how to implement the process in the Python programming language. Python is a popular programming language used in web development. With its simple code and easy-to-understand syntax, Python is easy to learn.
Python web scraping allows us to use a large collection of libraries such as Pandas and Numpy, where there are ample services and methods suitable for manipulating the extraction of web data.
In this Python web scraping tutorial, let’s learn how to extract product information from an e-commerce website, say Amazon.com.
Step 1: Find the URL of the targeted website
For this instance, we’ll target the URL for the “Computers & Tablets” product page on Amazon.com.
Log in on Amazon and type “Computers & Tablets”.
Step 2: Inspect the Page
Once the webpage gets loaded on the browser, you need to find and extract the data specific to product information. This data is situated in different tags of the web page. To find the specific data, we need to inspect the page as follows:
(i) Hover the cursor over a specific product
(ii) Right-click on it
(iii) Click on “Inspect” from the drop-down menu
The Browser Inspector Box opens up next to the web page in the same browser window.
Step 3: Find the Data for Extraction
In the Browser Inspector Box, go to the Elements section and locate the highlighted tag. In this case, the name, price, and rating of the product will be present inside the respective “div” tags.
Step 4: Create a Python File & Write the Code
Download and install the Python Terminal on your operating system (Windows, Ubuntu, or iOS). Open a terminal and execute the command lines as follows:
To create a test Python file called “web-test”, add the .py extension.
gedit web-test.py
Import the necessary libraries for web scraping. Here, Beautiful Soup, Selenium, and Panda will be imported as follows:
from selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
Set the path of the web driver to the driver of the Chrome browser:
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")
To open the targeted URL, run the following code:
products=[] #List to store name of the product
prices=[] #List to store price of the product
ratings=[] #List to store rating of the product
driver.get("<a href="https://www.amazon.com/s?i=specialty-aps&bbn=16225007011&rh=n%3A16225007011%2Cn%3A13896617011&ref=nav_em_T1_0_4_NaN_3__nav_desktop_sa_intl_computers_tablets")
To extract data from the respective div tags, run the following code:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a',href=True, attrs={'class':'_31qSD5'}):
name=a.find('div', attrs={'class':'_3wU53n'})
price=a.find('div', attrs={'class':'_1vC4OE _2rQ-NK'})
rating=a.find('div', attrs={'class':'hGSR34 _2beYZw'})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
Step 5: Extract & Store the Data
After finding the specific data, extract it with the following code:
Python web-test.py
The data can be stored in a specific format, let’s say in a CSV file, as follows:
df = pd.DataFrame({'Product Name':products,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')
This creates the “products.csv” file which contains all the extracted data. You can browse the product names, prices, ratings, and the respective product information structurally from the CSV file by opening it in a spreadsheet application such as Microsoft Excel and VisiCalc.
If you want to delve more deeply into the topic of web scraping with Python, you can watch this video.
Основной скрипт
pages = 10
for page in range(1, pages):
url = "http://quotes.toscrape.com/js/page/" + str(page) + "/"
driver.get(url)
items = len(driver.find_elements_by_class_name("quote"))
total = []
for item in range(items):
quotes = driver.find_elements_by_class_name("quote")
for quote in quotes:
quote_text = quote.find_element_by_class_name('text').text
author = quote.find_element_by_class_name('author').text
new = ((quote_text, author))
total.append(new)
df = pd.DataFrame(total, columns=)
df.to_csv('quoted.csv')
driver.close()
Изучив внимательнее URL сайта, обнаружим, что адрес для пагинации формируется следующим образом:
Вооруженные этим знанием,
мы создадим переменную pages с количеством страниц, которое мы собираемся обработать. В
данном примере мы в цикле извлечем сведения всего из 10 страниц.
Команда посылает HTTP-запрос к соответствующей странице
Дальше нам важно знать точное число объектов, которые мы получим с каждой страницы
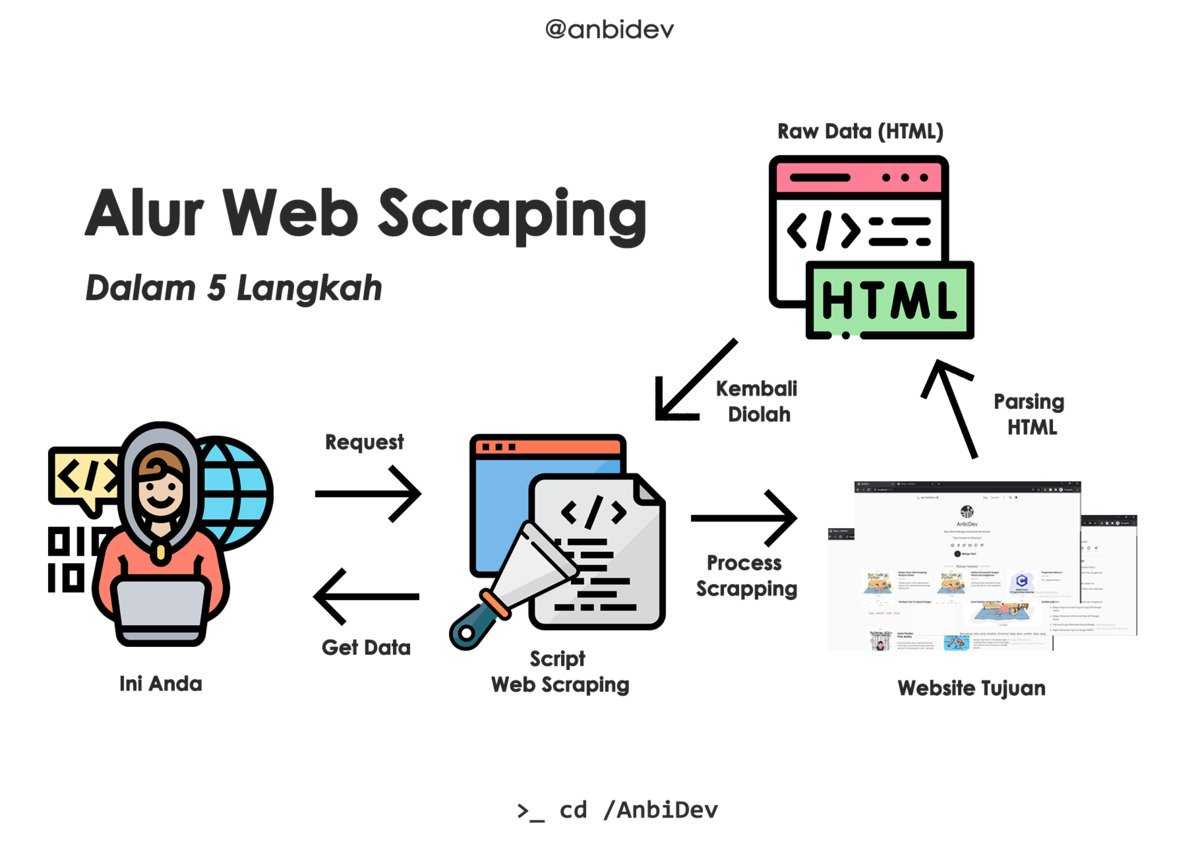
Приведу простое определение:
Веб-скрейпинг позволяет собрать неупорядоченные данные в интернете и сохранить их в структурированном формате.
Осмотрев элементы с цитатами, замечаем, что каждый из них заключен в тег div, принадлежащий классу с названием ”quote”. При помощи вызова мы получим все элементы, соответствующие этому шаблону.







Эту команду обернем в функцию и таким образом получим точное количество цитат на текущей странице. Сохраним его в переменную items, чтобы ограничить наш итератор.
History of Web Scraping
The idea of web scraping is pretty much intertwined with the web itself. The first scraper already appeared in 1993 and was intended to build an index of the then brand-new WWW, the Wanderer. Only a couple of months later, JumpStation went online and served as the first search engine as we’d define it these days.
Crawling, or scraping, the web was relatively straightforward back then, as pages were assembled in their entirety on the server (server-rendering) and — believe it or not — there was no JavaScript shifting around, or assembling, entire layouts on the client-side (client-rendering).
For that reason, one could use a traditional HTTP client or library to send a single HTTP request and get the desired data in the response. Especially with the advent of the DOM and XPath and CSS selectors, it really became easy to parse HTML and extract exactly the data one was after.
As sites became more complex over the years, web scraping had to adapt as well. Especially the adoption of JavaScript and its use to manipulate the content of pages, made it impossible to solely rely on individual HTTP requests. This is when the era of scraping frameworks and full-fledged browser integrations (aka headless browsers) started.
Headless browsers were quite the game changer. Contrary to manual scraping, they allow you to run a site in the exact same environment a regular visitor would use. This means the site will be rendered in the precise way it was supposed to be, with all CSS styles applied and all JavaScript code logic executed.
This really makes it as easy as pie to extract data even from sites which heavily rely on JavaScript and where content is loaded and displayed asynchronously and depending on certain browser events.
Web Scraping of APIs
One of the key aspects of web scraping is that you are dealing with data whose structure is not necessarily well-defined and which can change at any time, depending on the mood of the site’s designer. This is what web APIs (e.g. REST or SOAP) are supposed to address, by providing a well-defined and unified interface to access data.
Because of this defined and dedicated background, we are typically not talking about scraping in the context of accessing APIs, with one exception however: unoffical and undocumented APIs
Sites and services do not necessarily make all their APIs public and one can often find a true data treasure, simply by observing from where a website (particularly SPAs) or a mobile application fetches its data.
Developer tools
As always, your browser’s developer tools (the magic
F12) can be of great assistance in this context and the network tab can quickly uncover potential URLs and parameters of any undocumented API.
With that information it can be easy to reverse-engineer such calls and incorporate that API in one’s venture to get data from a particular service and actually receive already well-structured data, instead of fetching and parsing HTML manually.
Monitoring HTTP connections with a local proxy
Sometimes the developer tools may not be able to provide you with the full picture, and this is where another approach can prove to be quite handy: man-in-the-middle’ing the connection with a local proxy
There are quite a few solutions in that area out there, some free, some paid. Most notably mitmproxy and Charles. For the last one, we actually have a dedicated article on how to use Charles proxy for web scraping.